Tensorflow Overfitting过拟合解决方法 Dropput()使用方法
Overfitting过拟合
所谓过拟合,就是指把学习进行的太彻底,把样本数据的所有特征几乎都习得了,于是机器学到了过多的局部特征,过多的由于噪声带来的假特征,造成模型的“泛化性”和识别正确率几乎达到谷点,于是你用你的机器识别新的样本的时候会发现就没几个是正确识别的。
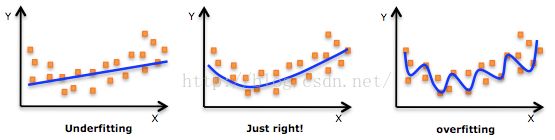
如上图所示,左边是Underfitting欠拟合,一根直线,根本无法区分数据,或是与理想区分度误差太大。中间图片,是我们理想的学习结果,能正确的区分数据。而最右边的Overfitting过拟合,因为数据本身带有一定的噪音,而机器学习又学的太好了,分类分的太细致了,导致训练数据能有极高的正确率,但测试数据正确率低。
一张图能形象有趣的解释过拟合:

Dropout方法:
既然过拟合是因为机器学习学的太过优秀导致的,因此解决过拟合的一种方法就是让机器少学点,比如使用Dropout()方法去除一定比例的学习结果。
下面来看个例子。
首先,我们要创建一套过拟合的神经网络系统:
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer
#读数据
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
def add_layer(inputs,in_size,out_size,layer_name,activation_function=None): #activation_function=None线性函数
Weights = tf.Variable(tf.random_normal([in_size,out_size])) #Weight中都是随机变量
biases = tf.Variable(tf.zeros([1,out_size])+0.1) #biases推荐初始值不为0
Wx_plus_b = tf.matmul(inputs,Weights)+biases #inputs*Weight+biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.histogram_summary(layer_name+'/outputs',outputs) #histogram_summary和scalar_summary对应
return outputs
xs = tf.placeholder(tf.float32,[None,64]) #8*8,64个单位
ys = tf.placeholder(tf.float32,[None,10])
l1 = add_layer(xs,64,50,'l1',activation_function=tf.nn.tanh) #隐藏层(输出100为了展示过拟合)
prediction = add_layer(l1,50,10,'l2',activation_function=tf.nn.softmax) #输出层
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
tf.scalar_summary('loss',cross_entropy) #可视化记录
train_step = tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
merged = tf.merge_all_summaries()
train_write = tf.train.SummaryWriter("logs/train",sess.graph)
test_write = tf.train.SummaryWriter("logs/test",sess.graph)
sess.run(init)
for i in range(1000):
sess.run(train_step,feed_dict = {xs:X_train,ys:y_train})
if i%50 == 0:
train_result = sess.run(merged,feed_dict = {xs:X_train,ys:y_train})
test_result = sess.run(merged,feed_dict = {xs:X_test,ys:y_test})
train_write.add_summary(train_result,i)
test_write.add_summary(test_result,i)
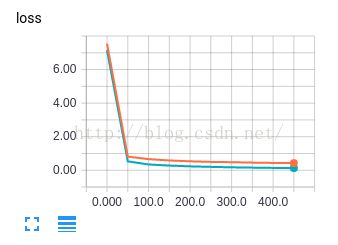
发现训练样本(绿)和测试样本(红)到50次训练后开始出现分叉,也就是训练样本略有过拟合,因此测试样本的正确率低于训练样本。
使用Dropout()方法舍弃50%学习结果:
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer
#读数据
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
def add_layer(inputs,in_size,out_size,layer_name,activation_function=None): #activation_function=None线性函数
Weights = tf.Variable(tf.random_normal([in_size,out_size])) #Weight中都是随机变量
biases = tf.Variable(tf.zeros([1,out_size])+0.1) #biases推荐初始值不为0
Wx_plus_b = tf.matmul(inputs,Weights)+biases #inputs*Weight+biases
Wx_plus_b = tf.nn.dropout(Wx_plus_b,keep_prob) #丢弃50%结果,减少过拟合
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.histogram_summary(layer_name+'/outputs',outputs) #histogram_summary和scalar_summary对应
return outputs
keep_prob = tf.placeholder(tf.float32) #保留的数据,不被dropout的数据
xs = tf.placeholder(tf.float32,[None,64]) #8*8,64个单位
ys = tf.placeholder(tf.float32,[None,10])
l1 = add_layer(xs,64,50,'l1',activation_function=tf.nn.tanh) #隐藏层(输出100为了展示过拟合)
prediction = add_layer(l1,50,10,'l2',activation_function=tf.nn.softmax) #输出层
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1])) #loss
tf.scalar_summary('loss',cross_entropy) #可视化记录
train_step = tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
merged = tf.merge_all_summaries()
train_write = tf.train.SummaryWriter("logs/train",sess.graph)
test_write = tf.train.SummaryWriter("logs/test",sess.graph)
sess.run(init)
for i in range(500):
sess.run(train_step,feed_dict = {xs:X_train,ys:y_train,keep_prob:0.5})
if i%50 == 0:
train_result = sess.run(merged,feed_dict = {xs:X_train,ys:y_train,keep_prob:1}) #记录数据时不要drop
test_result = sess.run(merged,feed_dict = {xs:X_test,ys:y_test,keep_prob:1})
train_write.add_summary(train_result,i)
test_write.add_summary(test_result,i)

可以发现,训练和测试数据基本一致,过拟合问题解决。