莫凡机器学习课程笔记
怎样区分好用的特征
- 避免无意义的信息
- 避免重复性的信息
- 避免复杂的信息
激活函数的选择
浅层神经网络,可以随便尝试各种激活函数
深层神经网络,不可随机选择各种激活函数,这涉及到梯度爆炸和梯度消失。(给出梯度爆炸和梯度消失的度量来判别激活函数的效果)
卷积神经网络,推荐的激活函数是 relu
循环神经网络,推荐的激活函数是relu or tanh
加速神经网络训练
Stochastic Gradient Descent (SGD)
批量数据,可加速训练过程,不会丢失太多信息
Momentum 惯性原则
W += - Learning rate * dx, 这种方法可以让学习过程曲折无比。
从平地到斜坡上来进行学习。
m = b1 *m - Learning rate *dx
W += m
AdaGrad: 学习率 对错误方向的阻力
W += - Learning rate * dx
给一双破鞋子,使得当摇晃走的时候,会感觉到不舒服,变成了走弯路的阻力,逼着的往前走。
v += dx^2
W += -Learning rate*dx/squrt(v)
RMSProp
W += - Learning rate * dx
Momentum(m = b1*m - Learning rate * dx) + AdaGrad(v+= dx^2)
v = b1*v + (1-b1)*dx^2
W += -Learning rate*dx/squrt(v)
Adam: 下坡和破鞋子
m = b1*m +(1-b1)*dx (Momentum)下坡属性
v = b2*v + (1-b2)*dx^2 (AdaGrad)阻力属性
W += -Learning rate*dx/squrt(v)
处理不均衡数据
永远总是猜测多数派。
1.获取更多的数据
2. 换个评判方式:
准确率(Accuracy)和误差(cost) 》》》》》》》》》》》》
confusion Matrix
Precision & Recall
F1 Score (0r F-score)
这种方式可以更好区分不均衡数据,给出更好的评判。
3. 重组数据:复制,上采样,下采样。
4. 其他机器学习方法:decision tree 对不均衡数据不敏感
5. 修改算法 :修改权重。
特征数据标准化
特征数据的标准化,归一化。
预测价格 = a * 离市中心距离 + b* 楼层 + c* 面积
a, b, c 就是需要学习的参数。
误差 = 预测 - 实际价格。
离市中心的数值范围 0~10 km
楼层的数值范围 1~30 层
面积范围 0 ~ 200 m^2
说白了就是不同维度的尺度不一样。这样就会导致每个维度对最终预测价格的影响严重不一样。
方法:
minmax normalization >>>>> (0,1)
std normalization >>>>>(mean = 0, std = 1)
加快学习速度,避免学出来的模型扭曲。
Batch Normalization 批标准化
对不同数据进行 BN。对不同维度进行的是归一化。
输入数据 X >>>> 全连接层 >>>> 激活函数>>>> 全连接层 ——-
输入数据 X >>>> 全连接层 >>>>BN >>>> 激活函数>>>> 全连接层—–
过拟合
自负 = 过拟合
对训练数据过于自信。而不能表达训练数据之外的数据。说白了就是学习出来的模型的泛化性太差。
- 增加数据量
- 正规化 L1 ,L2
- Dropout regularization
Y = WX, 在过拟合中,W一般变化比较大。那么可以将W的变化添加到损失函数,来约束W的变化。
L1: cost = (WX - realy)^2 + abs(WX)
L2: cost = (WX - realy)^2 + (W)^2
L1 L2 正规化
误差 J(theta) = [y_theata(x) - y]^2
L2 正则化误差 J(theta) = [y_theata(x) - y]^2 + [theata_1^2 + theata_2^2 + ……]
L1 正则化误差 J(theta) = [y_theata(x) - y]^2 + [|theata_1| + |theata_2| + ……]
这样最终的误差不仅取决于 拟合数据的好坏,还取决于拟合参数值的大小。

L1 的解 不稳定
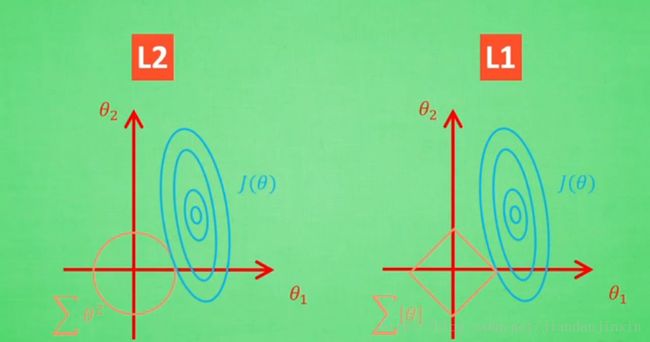

控制正规化的强度。用交叉验证来选择比较好的lamb

强化学习(Reinforcement Learning)
分数导向性。
强化学习没有数据和标签,通过一次次在环境中尝试来
获取数据和标签。
而监督学习一开始就有数据和标签。
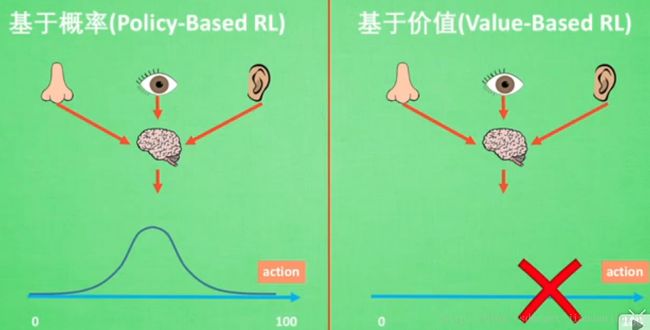
通过价值选行为
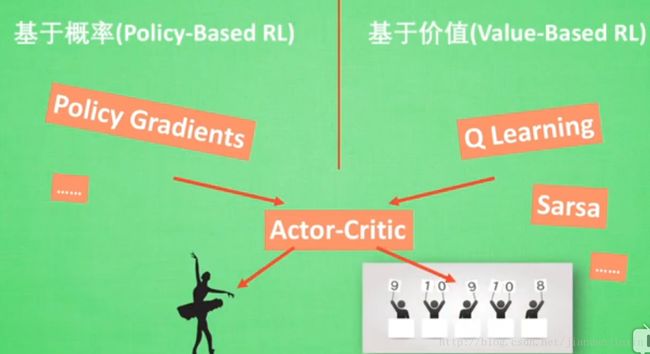
Q Learning 表格学习
Sarsa 表格学习
Deep Q Network 神经网络
直接选行为
Policy Gradients
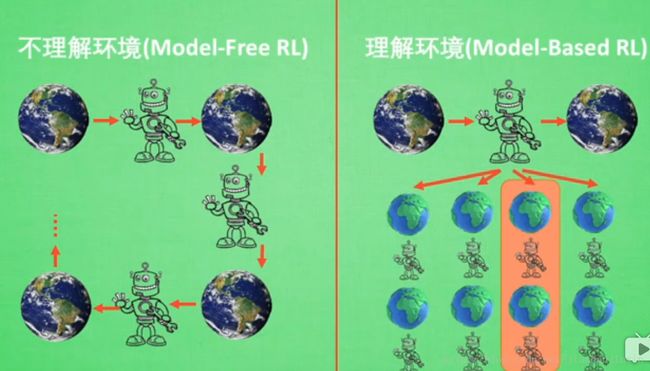
想象环境并从中学习
Model based RL 从虚拟环境中学习
强化学习方法汇总(Reinforcement Learning)



基于连续动作
结合
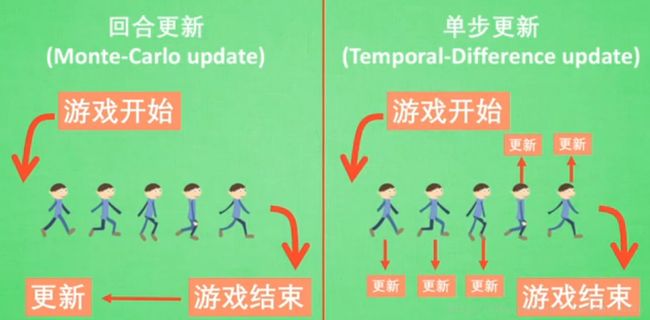



Q Learning
行为准则
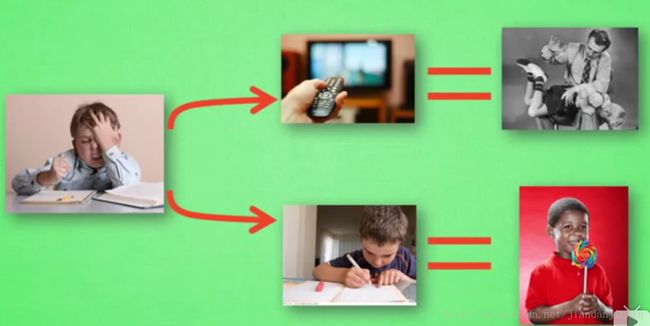
Q Learning 的示例
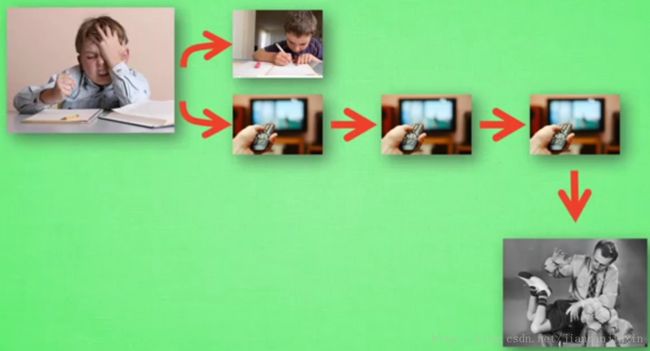
Q Learning 的决策过程

Q Learning 的Q表的提升过程

Q Learning 理解

Sarsa
Sarsa与 Q Learning极其相似
Sarsa 的Q表的提升过程
Q Learning Q表的提升过程

而 Sarsa的Q表的提升过程


Sarsa(lambda) (Reinforcement Learning)

* DQN (Reinforcement Learning)*
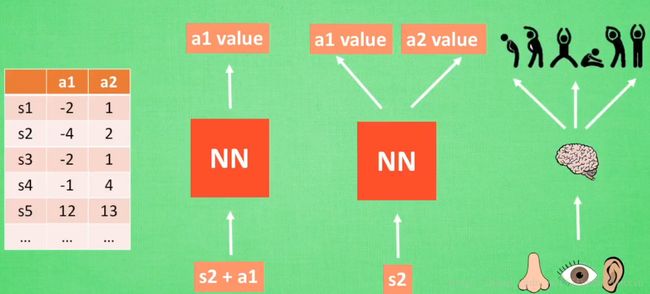
Q Learning 神经网络的训练过程
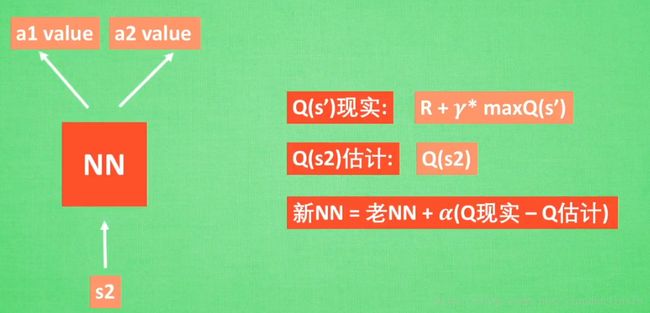

Policy Gradients (Reinforcement Learning)
无误差,用奖惩来选择

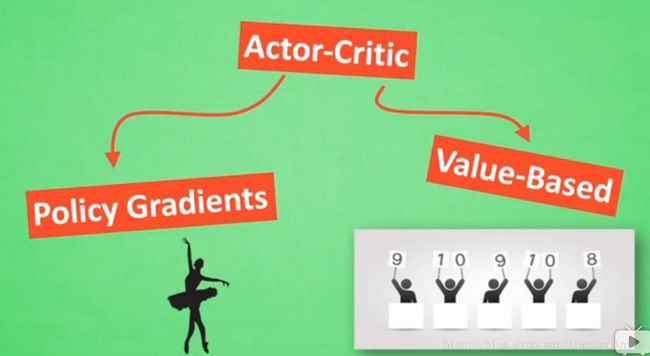
Actor Critic (Reinforcement Learning)
参考文献
莫烦课程主页
莫烦-机器学习
莫烦机器学习原来可以很简单-知乎
莫烦知乎专栏