scrapy爬虫框架学习入门教程及实例
Scrapy是一个基于Twisted,纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便~
Scrapy 使用 Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。整体架构如下图所示:
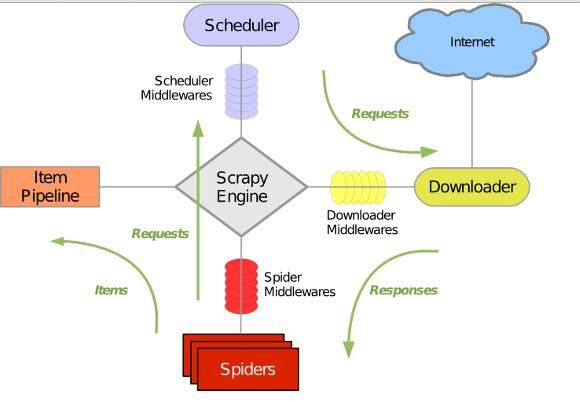
绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
在本文中,我们将学会如何使用Scrapy建立一个爬虫程序,并爬取指定网站上的内容
1. 创建一个新的Scrapy Project
2. 定义你需要从网页中提取的元素Item
3.实现一个Spider类,通过接口完成爬取URL和提取Item的功能
4. 实现一个Item PipeLine类,完成Item的存储功能
爬取网址: 盗墓笔记小说 http://www.daomubiji.com/
爬取盗墓笔记小说 书的大标题 小标题 章节名称 第几章 章节网址
Step1: 新建scrapy工程
打开命令行 scrapy startproject 工程名称
建好工程,有以下几个文件
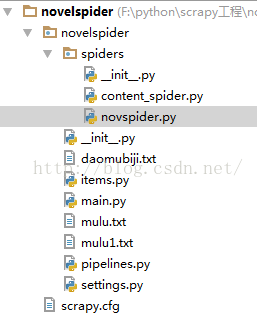
必有的文件 settings.py items.py pipelines.py __init__.py scrapy.cfg 及spider文件夹下 __init__.py 其它一些是自己后来添加的
scrapy.cfg: 项目配置文件
items.py: 需要提取的数据结构定义文件
pipelines.py:管道定义,用来对items里面提取的数据做进一步处理,如保存等
settings.py: 爬虫配置文件
spiders: 放置spider的目录
BOT_NAME = 'novelspider'
SPIDER_MODULES = ['novelspider.spiders']
NEWSPIDER_MODULE = 'novelspider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
## ITEM_PIPELINES是自己添加的 novelspider工程名字 NovelspiderPipeline 为文件pipelines中的类
ITEM_PIPELINES = ['novelspider.pipelines.NovelspiderPipeline']
# Obey robots.txt rules
# user_agent 自动配置 可修改
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
COOKIES_ENABLED = True
# 连接接数据库
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = 27017
MONGODB_DBNAME = 'ss'
MONGODB_DOCNAME = 'daomubiji'
from scrapy.item import Item,Field
class NovelspiderItem(Item):
# define the fields for your item here like:
bookName = Field() #书的大标题
bookTitle = Field() #书的小标题
chapterNum = Field() #书的章节 chapterName = Field() #书的章节名字 chapterURL = Field() #各章节url # name = scrapy.Field() #pass
#导入了3个模块
from items import NovelspiderItem ## 链接item
from scrapy.conf import settings
#from scrapy import settings # 不出错
import pymongo
class NovelspiderPipeline(object):
def __init__(self):
host = settings['MONGODB_HOST'] ## settings 赋值piplines
port = settings['MONGODB_PORT']
dbName = settings['MONGODB_DBNAME'] ## 数据库名字
client = pymongo.MongoClient(host = host,port = port) #链接数据库
tdb = client[dbName]
self.post = tdb[settings['MONGODB_DOCNAME']]
print 'piplines'
def process_item(self, item, spider):
bookInfo = dict(item) #把item转换为字典
self.post.insert(bookInfo) # 把数据存入到bookInfo字典里,插入数据库
return item
Spider是一个继承自scrapy.contrib.spiders.CrawlSpider的Python类,有三个必需的定义的成员
name: 名字,这个spider的标识
start_urls:一个url列表,spider从这些网页开始抓取
parse():一个方法,当start_urls里面的网页抓取下来之后需要调用这个方法解析网页内容,同时需要返回下一个需要抓取的网页,或者返回items列表
所以在spiders目录下新建一个spider,novelspider.py:
实现代码如下
# -*- coding: utf-8 -*- import sys reload(sys) sys.setdefaultencoding("utf-8") # 导入3个模块 一个CrawlSpider 一个selector 一个导入item类的模块 #from scrapy.spiders import CrawlSpider from scrapy.contrib.spiders import CrawlSpider # from scrapy.selector import Selector # 出错:没有该模块 更换下面这个模块XpathSelector from scrapy.selector import XPathSelector # 导入不出错 from novelspider.items import NovelspiderItem #导入item中的类NovelspiderItem #from scrapy.selector import HtmlXPathSelector 自定义类 class novSpider(CrawlSpider): name = "novspider" # name ,spider标识 唯一 redis_key = 'nvospider' start_urls = ['http://www.daomubiji.com/'] #spider从这里开始爬取网页 def parse(self,response): selector = XPathSelector(response) # 获取网页源代码 print '爬取源码完毕。。。' table = selector.select('//table') ## 查找书及其内容所在位置,获取书的名字 for each in table: bookName = each.select('tr/td[@colspan="3"]/center/h2/text()').extract()[0] content = each.select('tr/td/a/text()').extract() # 章节名称 url = each.select('tr/td/a/@href').extract() # 章节网址 # print type(bookName) # print content # 列表 for i in range(len(url)): item = NovelspiderItem() #链接item item['bookName'] = bookName item['chapterURL'] = url[i] ## 赋值给item中定义的chapterurl ### 防止报错 try: item['bookTitle'] = content[i].split(' ')[0] item['chapterNum'] = content[i].split(' ')[1] except Exception,e: continue try: item['chapterName'] = content[i].split(' ')[2] except Exception,e: item['chapterName'] = content[i].split(' ')[1][-3:] yield item
Step3 运行工程
上述四个文件的配置定义实现做好后就可以运行该程序了
如何运行程序
1、新建立一个.py文件 例如 main.py
#coding=utf-8
from scrapy import cmdline # 导入命令行
cmdline.execute("scrapy crawl novspider".split()) #命令行运行scrapy工程
注意:crawl后的(这里novspider)是自己定义的 name (spider标识)的名字,不是工程名字
2、直接启动命令行
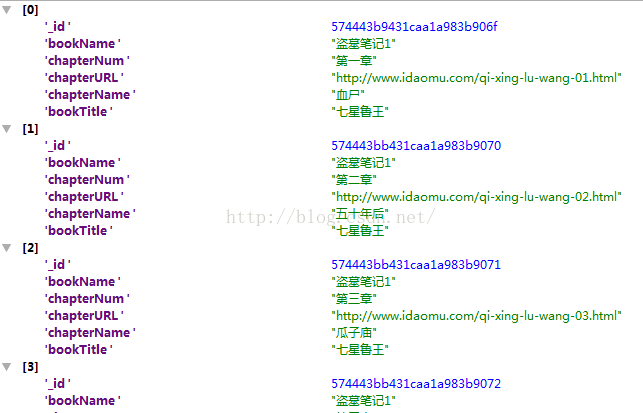
FEED_URI = u'file///F:\daomubiji\daobi.csv' 文件路径
FEED_FORMAT = 'CSV'