由散列表到BitMap的概念与应用(一)
散列表
提到散列表,大家可能会想到常用的集合HashMap,HashTable等。
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
散列表是种数据结构,它可以提供快速的插入操作和查找操作。第一次接触散列表时,它的优点多得让人难以置信。不论散列表中有多少数据,插入和删除只需要接近常量的时间即O(1)的时间级。实际上,这只需要几条机器指令。
对散列表的使用者来说,这是一瞬间的事。散列表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用散列表(例如拼写检查器)的速度明显比树快,树的操作通常需要O(N)的时间级。散列表不仅速度快,编程实现也相对容易。
散列表也有一些缺点。它是基于数组的,数组创建后难于扩展。某些散列表被基本填满时,性能下降得非常严重,所以程序虽必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的散列表中,这是个费时的过程)。
当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的冲突,也叫哈希碰撞。前面我们提到过,散列函数的设计至关重要,好的散列函数会尽可能地保证计算简单和散列地址分布均匀。但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的散列函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址)、再散列函数法和链地址法等,而HashMap即是采用了链地址法,也就是数组+链表的方式。
下面我们通过HashMap来具体讲解散列表的应用以及冲突解决方式。
HashMap实现原理
Java中HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
从中,我们可以看出 Entry 实际上就是一个单向链表。这也是为什么我们说HashMap是通过拉链法解决哈希冲突的。

简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,从性能方面考虑,HashMap中的链表出现越少,性能才会越好。
Hash表算法
Hash表的构造方法有多种,包括:直接定址法、除留取余法、平均取中法、折叠法、随机数法和数学分析法等。
直接定址法
取关键字key的某个线性函数为散列地址,如 H a s h ( k e y ) = k e y Hash(key) = key Hash(key)=key 或 H a s h ( k e y ) = A ∗ k e y + B ; Hash(key) = A*key+B; Hash(key)=A∗key+B; A,B为常数。
如:有一个从1到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。但这种方法效率不高,时间复杂度是O(1),空间复杂度是O(n),n是关键字的个数。
除留取余法
关键值除以比散列表长度小的素数所得的余数作为散列地址。 H a s h ( k e y ) = k e y Hash(key) = key % p; Hash(key)=key
在这里p的选取非常关键,p选择的好的话,能够最大程度地减少冲突,p一般取不大于m的最大质数。
平均取中法
先计算构成关键码的标识符的内码的平方,然后按照散列表的大小取中间的若干位作为散列地址。
如:有以下关键字序列{421,423,436},平方之后的结果为{177241,178929,190096},那么可以取{72,89,00}作为Hash地址。
折叠法
把关键码自左到右分为位数相等的几部分,每一部分的位数应与散列表地址位数相同,只有最后一部分的位数可以短一些。把这些部分的数据叠加起来,就可以得到具有关键码的记录的散列地址。分为移位法和分界法。
随机数法
选择一个随机函数,取关键字的随机函数作为它的哈希地址。
H ( k e y ) = r a n d o m ( k e y ) H(key)=random(key) H(key)=random(key),其中random为随机函数。通常用于关键字长度不等时采用此法。
数学分析法
设有N个d位数,每一位可能有r种不同的符号。这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布均匀些,每种符号出现的机会均等;在某些位上分布不均匀,只有某几种符号经常出现。可根据散列表的大小,选取其中各种符号分布均匀的若干位作为散列地址。
如:一批人的生日数据如下:
年.月.日
95.10.03
95.11.23
96.07.12
95.04.21
96.02.15
...
经分析,第一位,第二位,第三位重复的可能性大,取这三位造成冲突的机会增加,所以尽量不取前三位,取后三位比较好。
冲突解决
在上面介绍了Hash表的构造方法,尽管有这么多种方法,但是不同的key值可能会映射到同一散列地址上。这样就会造成哈希冲突/哈希碰撞。下面我们介绍下Hash表的冲突处理方法。
闭散列方法
又称为开放定址法,有线性探测和二次探测两种。
-
线性探测:当不同的key值通过哈希函数映射到同一散列地址上时,检测当前地址的下一个地址是否可以插入,如果可以的话,就存在当前位置的下一个地址,否则,继续向下一个地址寻找,地址++。
比如有一组关键字{12,13,25,23,38,34,6,84,91},Hash表长为11,Hash函数为address(key)=key%11,当插入12(hash(12)=1),13(hash(13)=2),25(hash(25)=3)时可以直接插入,而当插入23时,地址1被占用了,因此沿着地址1依次往下探测(探测步长可以根据情况而定,如(hash(23)+1)%11=2,(hash(23)+2)%11=3,(hash(23)+3)%11=4),直到探测到地址4,发现为空,则将23插入其中。
-
二次探测:是针对线性探测的一个改进,线性探测后插入的key值太集中,这样造成key值通过散列函数后还是无法正确的映射到地址上,太集中也会造成查找、删除时的效率低下。因此,通过二次探测的方法,取当前地址加上 i 2 i^2 i2,可以取到的新的地址就会稍微分散开。
(hash(23)+1^2)%11=2,(hash(23)+2^2)%11=5,直到探测到地址5,发现为空,则将23插入其中。
再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。这种做法使得计算时间增加。
开链法(哈希桶)
当用线性探测和二次探测时,总是在一个有限的哈希表中存储数据,当数据特别多时,效率就比较低。因此采用拉链法的方式来降低哈希冲突。

当一个链上链的数据过多时,我们可以采用红黑树的方式来降低高度,保持平衡且不至于过载。
BitMap
BitMap理解为位图的意思,用一个Bit位来标记某个元素对应的Value,而Key即是该元素。
在所有具有性能优化的数据结构中,使用最多的就是Hash表。在上一小节已经提到,Hash表具有定位查找上的时间级为O(1)。但是数据量大了,内存就不够了。由于采用了Bit为单位来存储数据,因此BitMap在存储空间方面,可以大大节省。
BitMap算法思想
32位机器上,一个整形,比如int a;在内存中占32bit位,可以用对应的32bit位对应十进制的0-31个数,BitMap算法利用这种思想处理大量数据的排序与查询.
优点:
- 运算效率高,不许进行比较和移位;
- 占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:所有的数据不能重复。即不可对重复的数据进行排序和查找。
比如:00000000000000000000000000010100 标注了2和4。
十进制和二进制bit位需要一个map图,把十进制的数映射到bit位。下面详细说明这个map映射表。
map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推BitMap表为:
- a[0]--------->0-31
- a[1]--------->32-63
- a[2]--------->64-95
- a[3]--------->96-127
- …
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
- 求十进制0-N对应在数组a中的下标:十进制0-31,对应在a[0]中,先由十进制数n转换为与32的余可转化为对应在数组a中的下标。当n=24,那么n/32=0,则24对应在数组a中的下标为0。当n=51,那么n/32=1,则51对应在数组a中的下标为1,同理可以计算0-N在数组a中的下标。
- 求0-N对应0-31中的数:十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得对应0-31中的数。
- 利用移位0-31使得对应32bit位为1。
BitMap应用
排序
假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复),我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0。
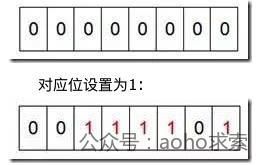
遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的,时间复杂度O(n)。
快速去重
2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
内存空间不足以容纳这2.5亿个整数,我们可以快速的联想到BitMap。下边关键的问题就是怎么设计我们的Bit-map来表示这2.5亿个数字的状态了。其实这个问题很简单,一个数字的状态只有三种,分别为不存在,只有一个,有重复。因此,我们只需要2bits就可以对一个数字的状态进行存储了,假设我们设定一个数字不存在为00,存在一次01,存在两次及其以上为11。那我们大概需要存储空间几十兆左右。
接下来的任务就是遍历一次这2.5亿个数字,如果对应的状态位为00,则将其变为01;如果对应的状态位为01,则将其变为11;如果为11,对应的转态位保持不变。
最后,我们将状态位为01的进行统计,就得到了不重复的数字个数,时间复杂度为O(n)。
快速查询
利用BitMap也可以进行快速查询,这种情况下对于一个数字只需要一个bit位就可以了,0表示不存在,1表示存在。假设上述的题目改为,如何快速判断一个数字是够存在于上述的2.5亿个数字集合中。
同之前一样,首先我们先对所有的数字进行一次遍历,然后将相应的转态位改为1。遍历完以后就是查询,由于我们的BitMap采取的是连续存储(整型数组形式,一个数组元素对应32bits),我们实际上是采用了一种分桶的思想。一个数组元素可以存储32个状态位,那将待查询的数字除以32,定位到对应的数组元素(桶),然后再求余(%32),就可以定位到相应的状态位。如果为1,则代表改数字存在;否则,该数字不存在。
布隆过滤器
单使用BitMap有时候是不够的,如果数据量大到一定程度,如64bit类型的数据,这时候用BitMap?所需要的存储大小:
2 64 b i t = 2 61 B y t e = 2048 P B = 2 E B 2^{64}bit=2^{61}Byte=2048PB=2EB 264bit=261Byte=2048PB=2EB
1PB=1024TB,1TB=1024GB。而EB(Exabyte,艾字节)这个计算机科学中统计数据量的单位有多大,1EB=1024PB。这个量级的BitMap,已经不是人类硬件所能承担的了。所以Bitmap的好处在于空间复杂度不随原始集合内元素的个数增加而增加,而它的坏处也源于这一点——空间复杂度随集合内最大元素增大而线性增大。
所以接下来,我们要引入另一个著名的工业实现——布隆过滤器(Bloom Filter)。如果说Bitmap对于每一个可能的整型值,通过直接寻址的方式进行映射,相当于使用了一个哈希函数,那布隆过滤器就是引入了k(k>1)k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。下图中是k=3时的布隆过滤器。
布隆过滤器的其中一种应用就是缓存雪崩。
总结
本文首先讲解了散列表的相关概念和应用。Hash表实际上为每一个可能出现的数字提供了一个一一映射的关系,每个元素都相当于有了自己的独享的一份空间,这个映射由散列函数来提供。Hash表甚至还能记录每个元素出现的次数,利用这一点可以实现更复杂的功能。
我们的需求是集合中每个元素有一个独享的空间并且能找到一个到这个空间的映射方法。独享的空间对于我们的问题来说,一个Boolean就够了,或者说,1个bit就够了,我们只想知道某个元素出现过没有。如果为每个所有可能的值分配1个bit,32bit的int所有可能取值需要内存空间为: 2 32 b i t = 2 29 B y t e = 512 M B 2^{32}bit=2^{29}Byte=512MB 232bit=229Byte=512MB。由此引出BitMap算法。我们介绍了BitMap算法的思想和部分应用,包括排序、去重、查询等应用,BitMap在这些大数据量上的应用都很高效。Bloom filter可以看做是对BitMap的扩展。更大数据量的有一定误差的用来判断映射是否重复的算法。关于布隆过滤器的具体应用细节,内容较多,将会在下篇文章具体介绍。
最后,欢迎购买笔者的新书《Spring Cloud微服务架构进阶》。

参考
- 哈希表(闭散列、拉链法–哈希桶)
- BitMap
- 大数据处理-Bitmap