Spark学习之6:Broadcast及RDD cache
1. Broadcast


1.1. 创建流程
BlockManager的三个put*方法(putIterator、putBytes、putArray)都包括(tellMaster: Boolean = true)参数,默认值为true。该参数是是否通知Master(BlockManagerMasterActor)的开关,当为true时,在将数据写入本地存储系统后,将会把BlockInfo信息发个Master。这样,其他节点就可以通过
BlockManagerMasterActor获取对用BlockId的信息。
1.1.1 TorrentBroadcast.writeBlocks
private def writeBlocks(value: T): Int = {
// Store a copy of the broadcast variable in the driver so that tasks run on the driver
// do not create a duplicate copy of the broadcast variable's value.
SparkEnv.get.blockManager.putSingle(broadcastId, value, StorageLevel.MEMORY_AND_DISK,
tellMaster = false)
val blocks =
TorrentBroadcast.blockifyObject(value, blockSize, SparkEnv.get.serializer, compressionCodec)
blocks.zipWithIndex.foreach { case (block, i) =>
SparkEnv.get.blockManager.putBytes(
BroadcastBlockId(id, "piece" + i),
block,
StorageLevel.MEMORY_AND_DISK_SER,
tellMaster = true)
}
blocks.length
}
(1)将数据作为整体存在本地;
(2)将数据按一定大小进行切片(默认为4096KB=4MB,每个切片对应一个block,并有唯一的BroadcastBlockId),存在本地并向Master报告。
注:
HttpBroadcast只将数据作为整体存储在本地,并通知Master,不会对数据进行切片。TorrentBroadcast同过将数据切片,最后会形成在很多节点上都有备份数据,当有新节点需要数据时,就可以提高数据获取的并行度,从而提高数据远程读取效率。
1.1.2 BlockManagerMasterActor.updateBlockInfo
BlockManagerMasterActor收到UpdateBlockInfo消息后将调用updateBlockInfo方法。
该方法主要更新下面成员:
// Mapping from block manager id to the block manager's information.
private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo]
......
// Mapping from block id to the set of block managers that have the block.
private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
一个block可能在多个节点存有备份,所以每个BlockId对应一个位置集合,位置用BlockManagerId表示。
方法代码:
private def updateBlockInfo(
blockManagerId: BlockManagerId,
blockId: BlockId,
storageLevel: StorageLevel,
memSize: Long,
diskSize: Long,
tachyonSize: Long): Boolean = {
if (!blockManagerInfo.contains(blockManagerId)) {
if (blockManagerId.isDriver && !isLocal) {
// We intentionally do not register the master (except in local mode),
// so we should not indicate failure.
return true
} else {
return false
}
}
if (blockId == null) {
blockManagerInfo(blockManagerId).updateLastSeenMs()
return true
}
blockManagerInfo(blockManagerId).updateBlockInfo(
blockId, storageLevel, memSize, diskSize, tachyonSize)
var locations: mutable.HashSet[BlockManagerId] = null
if (blockLocations.containsKey(blockId)) {
locations = blockLocations.get(blockId)
} else {
locations = new mutable.HashSet[BlockManagerId]
blockLocations.put(blockId, locations)
}
if (storageLevel.isValid) {
locations.add(blockManagerId)
} else {
locations.remove(blockManagerId)
}
// Remove the block from master tracking if it has been removed on all slaves.
if (locations.size == 0) {
blockLocations.remove(blockId)
}
true
}
(1)更新BlockManagerInfo;
(2)更新block的位置信息(用BlockManagerId表示)。
1.2. 读取流程
先从本地获取,然后考虑远程获取。
1.2.1 TorrentBroadcast.getValue
override protected def getValue() = {
_value
}
_value是一个lazy变量:
@transient private lazy val _value: T = readBroadcastBlock()1.2.2 TorrentBroadcast.readBroadcastBlock
TorrentBroadcast.synchronized {
setConf(SparkEnv.get.conf)
SparkEnv.get.blockManager.getLocal(broadcastId).map(_.data.next()) match {
case Some(x) =>
x.asInstanceOf[T]
case None =>
logInfo("Started reading broadcast variable " + id)
val startTimeMs = System.currentTimeMillis()
val blocks = readBlocks()
logInfo("Reading broadcast variable " + id + " took" + Utils.getUsedTimeMs(startTimeMs))
val obj = TorrentBroadcast.unBlockifyObject[T](
blocks, SparkEnv.get.serializer, compressionCodec)
// Store the merged copy in BlockManager so other tasks on this executor don't
// need to re-fetch it.
SparkEnv.get.blockManager.putSingle(
broadcastId, obj, StorageLevel.MEMORY_AND_DISK, tellMaster = false)
obj
}
}
(1)先从本地读取对应BroadcastBlockId对应的数据;
(2)调用readBlocks读取所有的block;
(3)合并读到的blocks;
(4)调用BlockManager.putSingle将数据存储在本地,其tellMaster值为false,即不通知Master。
1.2.3 TorrentBroadcast.readBlocks
// Fetch chunks of data. Note that all these chunks are stored in the BlockManager and reported
// to the driver, so other executors can pull these chunks from this executor as well.
val blocks = new Array[ByteBuffer](numBlocks)
val bm = SparkEnv.get.blockManager
for (pid <- Random.shuffle(Seq.range(0, numBlocks))) {
val pieceId = BroadcastBlockId(id, "piece" + pid)
logDebug(s"Reading piece $pieceId of $broadcastId")
// First try getLocalBytes because there is a chance that previous attempts to fetch the
// broadcast blocks have already fetched some of the blocks. In that case, some blocks
// would be available locally (on this executor).
def getLocal: Option[ByteBuffer] = bm.getLocalBytes(pieceId)
def getRemote: Option[ByteBuffer] = bm.getRemoteBytes(pieceId).map { block =>
// If we found the block from remote executors/driver's BlockManager, put the block
// in this executor's BlockManager.
SparkEnv.get.blockManager.putBytes(
pieceId,
block,
StorageLevel.MEMORY_AND_DISK_SER,
tellMaster = true)
block
}
val block: ByteBuffer = getLocal.orElse(getRemote).getOrElse(
throw new SparkException(s"Failed to get $pieceId of $broadcastId"))
blocks(pid) = block
}
blocks
(1)先从本地获取对应的切片;
(2)如果本地没有,则从Remote获取,并将获取的切片存储在本地,并通知Master。
BlockManager.getRemoteBytes将调用BlockManager.doGetRemote方法。
1.2.4 BlockManager.doGetRemote
private def doGetRemote(blockId: BlockId, asBlockResult: Boolean): Option[Any] = {
require(blockId != null, "BlockId is null")
val locations = Random.shuffle(master.getLocations(blockId))
for (loc <- locations) {
logDebug(s"Getting remote block $blockId from $loc")
val data = blockTransferService.fetchBlockSync(
loc.host, loc.port, loc.executorId, blockId.toString).nioByteBuffer()
if (data != null) {
if (asBlockResult) {
return Some(new BlockResult(
dataDeserialize(blockId, data),
DataReadMethod.Network,
data.limit()))
} else {
return Some(data)
}
}
logDebug(s"The value of block $blockId is null")
}
logDebug(s"Block $blockId not found")
None
}
(1)获取BlockId所在的BlockManager,返回值是BlockManagerId序列,并将BlockManagerId进行随机排列;
(2)通过NettyBlockTransferService来从远端读取block。
2. RDD cache
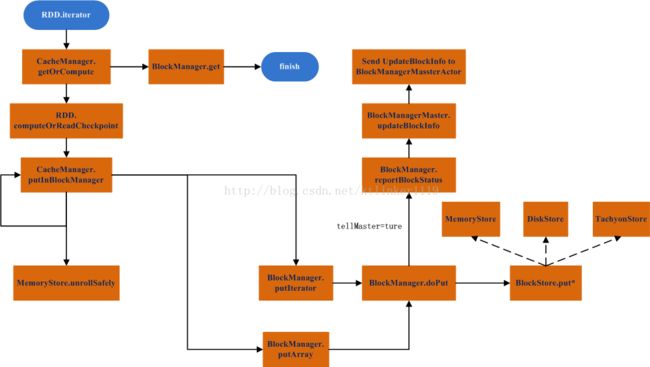
2.1. RDD读写流程
(1)RDD cache读写入口为RDD.iterator函数,在RDD具体计算过程中发起;
(2)CacheManager.getOrCompute方法首先从BlockManager中查找partition对应的Block(一个partition对应一个block),若没找到则调用RDD.computeOrReadCheckpoint方法,计算完成后将结果进行cache;
(3)到具体写Memory、Disk的过程和Broadcast相同;
(4)从BlockManager进行get的流程和Broadcast也相似。
2.2. RDD.iterator
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)
} else {
computeOrReadCheckpoint(split, context)
}
}
根据RDD的storageLevel,判断是否cache。
2.3. CacheManager.getOrCompute
def getOrCompute[T](
rdd: RDD[T],
partition: Partition,
context: TaskContext,
storageLevel: StorageLevel): Iterator[T] = {
val key = RDDBlockId(rdd.id, partition.index)
logDebug(s"Looking for partition $key")
blockManager.get(key) match {
case Some(blockResult) =>
// Partition is already materialized, so just return its values
......
val iter = blockResult.data.asInstanceOf[Iterator[T]]
new InterruptibleIterator[T](context, iter) {
override def next(): T = {
existingMetrics.incRecordsRead(1)
delegate.next()
}
}
case None =>
......
// Otherwise, we have to load the partition ourselves
try {
logInfo(s"Partition $key not found, computing it")
val computedValues = rdd.computeOrReadCheckpoint(partition, context)
// If the task is running locally, do not persist the result
if (context.isRunningLocally) {
return computedValues
}
// Otherwise, cache the values and keep track of any updates in block statuses
val updatedBlocks = new ArrayBuffer[(BlockId, BlockStatus)]
val cachedValues = putInBlockManager(key, computedValues, storageLevel, updatedBlocks)
val metrics = context.taskMetrics
val lastUpdatedBlocks = metrics.updatedBlocks.getOrElse(Seq[(BlockId, BlockStatus)]())
metrics.updatedBlocks = Some(lastUpdatedBlocks ++ updatedBlocks.toSeq)
new InterruptibleIterator(context, cachedValues)
} finally {
......
}
}
}
(1)根据RDD的id和partition的索引值创建RDDBlockId对象;
(2)从BlockManager中查找对应RDDBlockId的block;
(3)如果找到,直接返回结果;
(4)如果没有找到,则调用RDD.computeOrReadCheckpoint计算分区;
(5)调用CacheManager.putInBlockManager将分区结果进行cache。
2.4. CacheManager.putInBlockManager
private def putInBlockManager[T](
key: BlockId,
values: Iterator[T],
level: StorageLevel,
updatedBlocks: ArrayBuffer[(BlockId, BlockStatus)],
effectiveStorageLevel: Option[StorageLevel] = None): Iterator[T] = {
val putLevel = effectiveStorageLevel.getOrElse(level)
if (!putLevel.useMemory) {
/*
* This RDD is not to be cached in memory, so we can just pass the computed values as an
* iterator directly to the BlockManager rather than first fully unrolling it in memory.
*/
updatedBlocks ++=
blockManager.putIterator(key, values, level, tellMaster = true, effectiveStorageLevel)
blockManager.get(key) match {
case Some(v) => v.data.asInstanceOf[Iterator[T]]
case None =>
logInfo(s"Failure to store $key")
throw new BlockException(key, s"Block manager failed to return cached value for $key!")
}
} else {
/*
* This RDD is to be cached in memory. In this case we cannot pass the computed values
* to the BlockManager as an iterator and expect to read it back later. This is because
* we may end up dropping a partition from memory store before getting it back.
*
* In addition, we must be careful to not unroll the entire partition in memory at once.
* Otherwise, we may cause an OOM exception if the JVM does not have enough space for this
* single partition. Instead, we unroll the values cautiously, potentially aborting and
* dropping the partition to disk if applicable.
*/
blockManager.memoryStore.unrollSafely(key, values, updatedBlocks) match {
case Left(arr) =>
// We have successfully unrolled the entire partition, so cache it in memory
updatedBlocks ++=
blockManager.putArray(key, arr, level, tellMaster = true, effectiveStorageLevel)
arr.iterator.asInstanceOf[Iterator[T]]
case Right(it) =>
// There is not enough space to cache this partition in memory
val returnValues = it.asInstanceOf[Iterator[T]]
if (putLevel.useDisk) {
logWarning(s"Persisting partition $key to disk instead.")
val diskOnlyLevel = StorageLevel(useDisk = true, useMemory = false,
useOffHeap = false, deserialized = false, putLevel.replication)
putInBlockManager[T](key, returnValues, level, updatedBlocks, Some(diskOnlyLevel))
} else {
returnValues
}
}
}
}
(1)如果不存储在memory中,则直接调用BlockManager.putIterator;
(2)如果存储在memory中,这先调用MemoryStore.unrollSafely方法,判断分区是否能够全部缓存在memory中;
(3)如果能,则调用BlockManager.putArray;
(4)如果不能,则判断是否需要存储在Disk中,若条件满足,则修改存储方式,让后直接调用putInBlockManager自身。