Python爬虫框架Scrapy入门
Python爬虫框架Scrapy入门
一、爬虫定义
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面,以获取这些网站的内容。
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
二、所需知识
需要的知识有:linux系统 + Python语言 +Scrapy框架 + XPath(XML路径语言) + 一些辅助工具(浏览器的开发者工具和XPath helper插件)。
我们的爬虫是使用Python语言的Scrapy爬虫框架开发,在linux上运行,所以需要熟练掌握Python语言和Scrapy框架以及linux操作系统的基本知识。
我们需要使用XPath从目标HTML页面中提取我们想要的东西,包括汉语文字段落和“下一页”的链接等。
浏览器的开发者工具是编写爬虫主要使用的辅助工具。使用该工具可以分析页面链接的规律,可以用来定位HTML页面中想要提取的元素,然后提取其XPath表达式用于爬虫代码中,还可以查看页面请求头的Referer、Cookie等信息。如果爬取的目标是动态网站,该工具还可以分析出背后的JavaScript请求。
XPath helper插件是chrome的一个插件,基于chrome核的浏览器也可以安装。XPath helper可以用来调试XPath表达式。
三、环境搭建
安装Scrapy可以使用pip命令:pip install Scrapy
Scrapy相关依赖较多,因此在安装过程中可能遇到如下问题:
- ImportError: No module named w3lib.http
解决:pip install w3lib
- ImportError: No module named twisted
解决:pip install twisted
- ImportError: No module named lxml.HTML
- error: libxml/xmlversion.h: No such file or directory
apt-get install Python-lxml
- ImportError: No module named cssselect
- ImportError: No module named OpenSSL
或者使用简单的方法:使用anaconda安装。
四、Scrapy框架
1. Scrapy简介
Scrapy是大名鼎鼎的爬虫框架,是使用Python编写的。Scrapy可以很方便的进行web抓取,并且也可以很方便的根据自己的需求进行定制。
Scrapy整体架构大致如下:
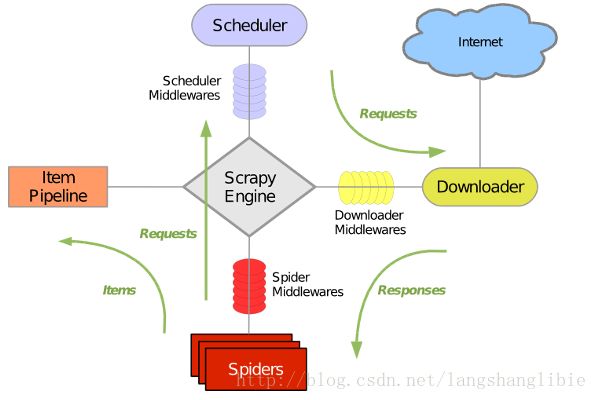
2. Scrapy组件
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
- 调度器(Scheduler)
- 下载器(Downloader)
- 爬虫(Spiders)
- 项目管道(Pipeline)
- 下载器中间件(Downloader Middlewares)
- 爬虫中间件(Spider Middlewares)
- 调度中间件(Scheduler Middewares)
3. Scrapy运行流程
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
五、爬虫举例
我们以美剧天堂网站最近更新页面(http://www.meijutt.com/new100.HTML)为例,讲述如何使用scrapy。
源码地址:https://pan.baidu.com/s/1htFmXPM
现在我们想要爬取最近更新的100部美剧的名称。
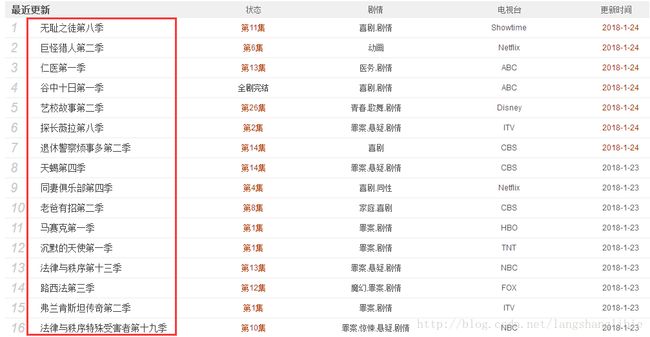
1. 创建工程
![]()
movie 为爬虫工程的名称
2. 创建爬虫程序
![]()
meiju 为爬虫的名称,meijutt.com为要爬取的网站的域名。
3. 目录及文件结构
创建完爬虫后的目录及文件结构如下:

4. 文件说明
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名。
5. 设置数据存储模板
items.py
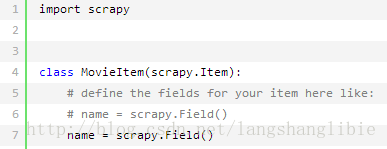
6. 编写爬虫
meiju.py

7. 修改配置文件
settings.py增加如下内容
![]()
8. 编写数据处理脚本
pipelines.py

9. 执行爬虫
![]()
10. 爬虫结果

六、XPath
上面的爬虫代码中在提取电影列表和电影名称时使用了XPath(下图红框部分)。

1. XPath定义
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。XPath当然也适用于HTML。
2. XPath语法
XPath使用路径表达式在 XML文档中选取节点。节点是通过沿着路径或者 step来选取的。
下面列出了最有用的路径表达式:
| 表达式 |
描述 |
| nodename |
选取此节点的所有子节点。 |
| / |
从根节点选取。 |
| // |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . |
选取当前节点。 |
| .. |
选取当前节点的父节点。 |
| @ |
选取属性。 |
3. 实例
现在有这样一个XML文档:
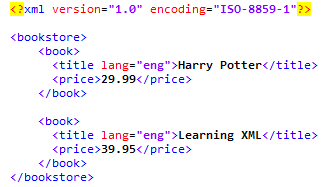
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 |
结果 |
| bookstore |
选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book |
选取属于 bookstore 的子元素的所有 book 元素。 |
| //book |
选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book |
选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore之下的什么位置。 |
| //@lang |
选取名为 lang 的所有属性。 |
上面知识XPath的一部分,详细的XPath知识可参考w3school网站。
七、相关工具
1. 浏览器的开发者工具
浏览器的开发者工具在写爬虫过程中具有很重要的作用。
1.1 定位HTML页面中的元素
在指定的网页元素上单击右键,选择“审查元素”,开发者工具就会定位到页面代码中该元素的位置。

定位的地方往上看就可以看到代码中Xpath表达式'//ul[@class="top-list fn-clear"]/li'中"top-list fn-clear"的来源。

1.2 查看请求头信息
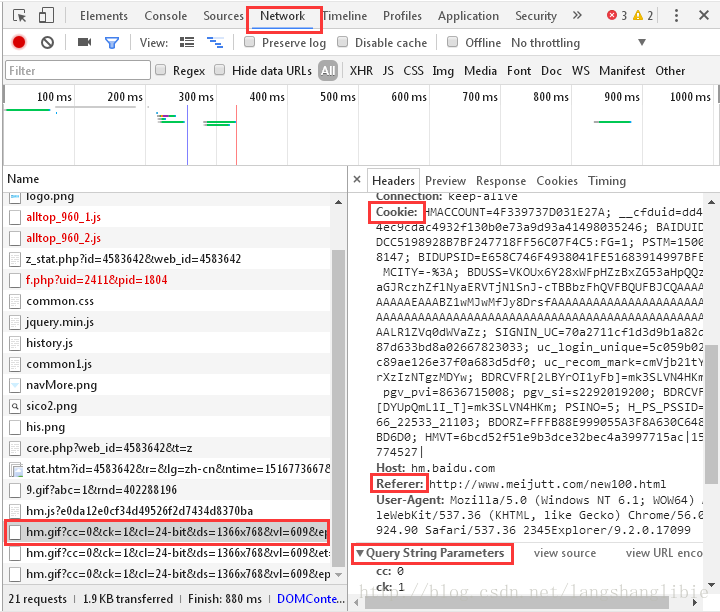
这些信息包含Cookies、Referer等,在爬虫里面有时会用到。
1.3 捕获动态网站背后的真实请求
这个动态网站章节会详细介绍。
浏览器开发者工具还有一些其他用处,这里不方便一一列出。
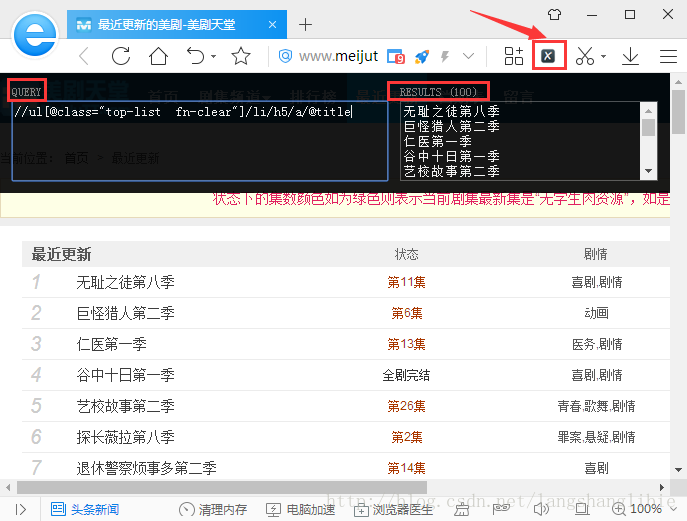
2. XPath提取工具 XPath Helper
XPath Helper是chrome系浏览器的一个插件,只要是chrome核的浏览器都可以使用。
XPath Helper可以用来调试XPath表达式,在左边的query框里面输入XPath表达式,右边的results框就会实现显示结果。
八、动态网站
前面的例子介绍的是静态网站,静态网站的意思就是说想要提取的元素直接包含在了HTML页面的代码里面,可以用XPath直接获取到。但是现在的很多网站都是动态网站,使用Ajax技术。典型的例子就是新闻流页面,鼠标点击“加载更多”或一直向下滚动才会加载更新新闻,但是URL地址并没有变,页面的HTML代码里面也不含这些新闻。例如UC头条:

Ajax背后的大致原理是通过JavaScrpit向服务器发送异步请求,服务端查询数据库,返回数据,客户端根据返回的数据,使用JavaScript操作DOM将数据再展示出来。
所以要想爬这种网站,最主要的是知道JavaScrpit向服务器发送的那个异步请求。下面我们举个动态网站的例子:新浪滚动新闻首页,打开如下:

如果这是一个静态页面,在解析完第一页后,获取“下一页”按钮里面的链接,然后再打开该链接,再解析,再获取“下一页”按钮里面的链接。。。这样一直下去,直到最有一页。
但是这是一个动态网站,看一下“下一页”按钮的HTML的代码。
![]()
这个超链接可以提取,但是打开之后还是第一页,并不是第二页,所以真实的数据不在这里。通过浏览器的“审查元素”功能可以看到这个按钮的动作是执行一个JavaScript函数。
![]()
为什么“审查元素”看到的和HTML代码里面不一样?因为“审查元素”看到的是HTML里面的JavaScript代码执行后的。
我们可以使用浏览器开发者工具看看点击这个按钮时到底干了啥。打开浏览器开发者工具,切到“Network”,下面的类型选择” JS”。

准备就绪之后,我们点击一下“下一页”按钮,可以到看多了一条记录,类型是脚本。

点击选中这个记录,切到”Preview”选项卡,里面的数据正好是第二页的新闻。

现在可以知道,原来第二页的数据是动态向服务器请求回来的,是一个Json格式的字符串赋值给了一个变量,其实整个就是JavaScript代码,服务器返回JavaScript代码.
请求的链接可以在“Headers”里面看到。
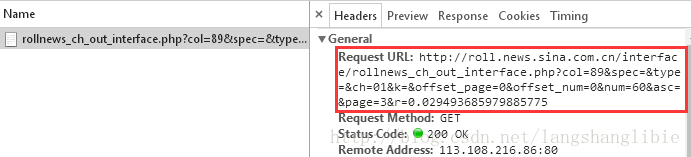
这个链接就是我们想要的,其实这个链接就是新浪新闻后台提供给前端页面使用的数据接口,我们也可以直接请求这个链接获取数据,而不用解析HTML页面,这无疑提升了效率和稳定性。因为既然是接口,那么就要保持稳定,不能频繁变动,而前端HTML页面代码相对来说变动的代价较小。。
我们继续看这个链接,发现后面有很多参数。

这些参数代表什么意思?我们不用全部知道,只需要知道那些会变化的参数,而那些不变化的参数,我们保持一致即可。所以我们再点击2下“下一页”按钮,看看3次之间哪些参数会发生变化,然后建立一个表格对比看下。
| col |
spec |
type |
ch |
k |
offset_page |
offset_num |
num |
asc |
page |
r |
| 89 |
01 |
0 |
0 |
60 |
2 |
0.029493685979885775 |
||||
| 89 |
01 |
0 |
0 |
60 |
3 |
0.3121254224752399 |
||||
| 89 |
01 |
0 |
0 |
60 |
4 |
0.656132625486423 |
可以发现只有“page”和”r”在变化,其它的不动。“page”很容易可以猜到是第几页,“r”看上去是一个随机数,0-1之间的随机数。其它参数也可以猜测下,比如“col”可能是栏目ID,“num”是向服务器请求的新闻条数。
知道了可以用“page”控制向服务器请求的页数,但是我们怎么知道一共有多少页呢,请求到什么时候截止呢?这是一个问题。
再观察服务器返回的数据,发现里面有一个“count”字段。
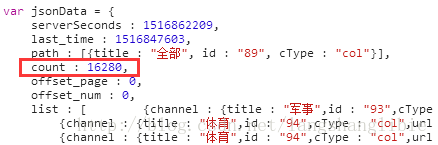
这个字段的值三次返回的结果分别是16204、16207、16210,猜测这个就是总的新闻条数,因为新闻编辑者们在实时编辑,所以总是在上升,但是变化不大。
有了新闻总数count、每次向服务器请求的新闻个数,那么有多少页就很简单了。
page_count = count / num
page_count就是页数了。
至此,爬虫代码就很简单了,请求接口返回来的是JavaScript的代码,将其中的JavaScript数据提取出来就可以了,剩下的跟静态网站一样了。
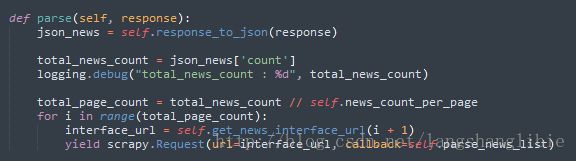

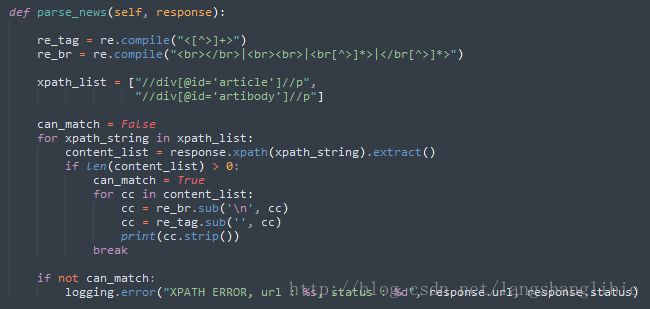
九、反爬
爬虫、反爬虫、反反爬虫,这之间的斗争恢宏壮阔,不是三两句话能讲清楚的。这里简单了说一下几个反反爬虫的方法。
1. 随机user_agent
利用Scrapy写出来的爬虫,请求头的user_agent字段都含有“Scrapy”关键字,很容易被识别出来是爬虫,所以我们可以伪装成浏览器。通过浏览器随意打开一个网站,在开发者工具里面可以看到这个浏览器的user_agent。
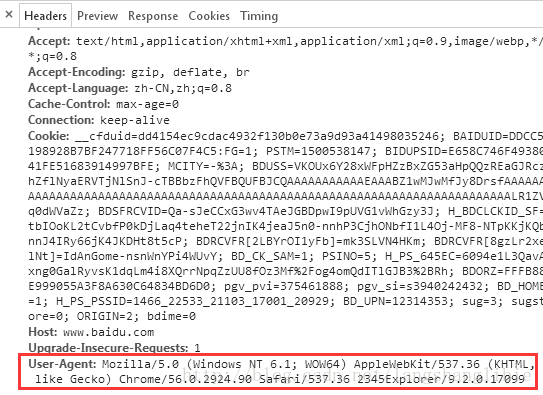
多弄些浏览器在不同平台、不同系统下的的user_agent,随机切换,这样更具隐蔽性。自定义user_agent可以通过继承Scrapy的UserAgentMiddleware类来实现。
2. 添加Referer
Referer是告诉服务器我是从哪个页面链接过来的,服务器借此可以获得一些信息用于处理。例如,用户在打开新闻详情页时,一般都是从新闻列表页链接过来的,或者是从别的网站链接过来的,Referer都是有值的。而Scrapy写的爬虫,Referer字段都是空的。打开百度新闻首页(http://news.baidu.com/)里的一篇文章,可以用开发者工具获取到Referer:

3. 延时
有些网站监控同一个IP向服务器请求的频率,如果频率太大,比如一秒钟几百次,这完全超出人类的行为,所以服务器直接视为爬虫,将IP拉黑,豆瓣就是这样的。对于这样的网站,我们可以在爬虫中增加延时,比如每两个请求之间间隔0.3秒。
4. 随机代理IP
对于封IP的网站,延时的方法使得爬虫效率大大下降。更好的办法是使用IP代理,每次向服务器请求使用不同的IP。高质量的、稳定的代理IP一般都是收费的,需要购买。有些网站提供一些免费的限时的代理IP,可以临时一用。
十、局限
一个全新的网站入口需要重新订制一个爬虫,不利于大规模抓取。