时间序列异常检测 EGADS Surus iForest

阅读全文
正文共3483个字,3张图,预计阅读时间9分钟。
时间序列异常检测
(原文链接:http://wurui.cc/tech/time-series-anomaly-detection/)
本文总结了我在时间序列异常算法方面的一些经验。读者需要对常规机械学习算法有一定的了解。希望本文能帮助有相关需求的工程师快速切入。
EGADS Java Library
EGADS (Extendible Generic Anomaly Detection System)(https://github.com/yahoo/egads)是Yahoo一个开源的大规模时间序列异常检测项目。它的框架主要由两个模块构成,一个是时间序列构造模块,另一个是异常检测模块。给定一段时间的离散值(构成一个序列),时间序列模块会学习这段序列的特征,并试图重新构建一个和原序列尽量接近的序列。结果和原序列一同送入异常检测模块,基于不同的算法(原则,阈值),异常点会被标记出来。
Time-series Modeling Module
时间序列构造模块提供了多种算法。简单介绍如下:
Olympic Model(Seasonal Naive)一个简单的窗口模型,对点Px的预测为点Px前n个值的Smoothed Average.
Exponential Smoothing Model 一个平滑模型,由简单的数列获得。ETS模型可以自动选择Single、Double、Triple里面匹配最好的输出。
Moving Average Model 也是平滑模型,点Px的预测值取邻近点的平均值。
Regression Models 一般是线性回归,特殊例子或者异常偏差特别大的时候有用。
Anomaly Detection Module
异常检测模块
ExtremeLowDensityModel 超低密度模型,很简单有效的密度模型。
AdaptiveKernelDensityChangePointDetector 拐点检测模型
KSigmaModel 经典K-sigma模型
DBScanModel(Density-Based Spatial Clustering of Applications with Noise)又是一个基于密度的模型,在空间中作聚类,如果目标序列可以比较好的分类的话会有不错的效果。
实践经验。
序列构造自动选优
不同类型的数据可能适合不同的模型。选择AutoForecastModel,程序会自动把所有TMM都跑一遍,并推选偏差值最小的模型送入异常检测模块。值得注意的是,这里自动选取的标准只关注了还原度,但还原度高并不直接代表能更好的查找异常,在使用本方法的时候要留意在心。
多数投票算法
不同的异常检测算法从不同的角度定义了异常。实践过程中我发现,单一异常算法并不能找出所有异常点,同时还会出现一系列的假阳性异常。使用Majority Voting,规定半数以上算法识别为异常的点才输出为结果,在实际数据中提供了远高于单一算法的准确度。
Surus
Surus(https://github.com/Netflix/Surus)是Netflix开源的一个项目,因为Netflix内部大量使用Pig和Hive,Surus主要的功能是提供RPCA的Pig/Hive封装。核心算法Robust PCA是Java实现的,可以单独调用。
Netflix首先对他们的问题定了一个基调。Profile是一个非常好的习惯,对决策者来说可以提供命中率,也就提高了团队效率。问题的特征定义如下:
高纬度。数据集纬度高,数据间相互交织,人工检测基本不可能。
最低加阳性。作为异常检测问题,我们不希望有过多的假阳性报警来干扰监控人员。
周期性。每小时/每天/每周/每月这样的周期性数据如果不妥善处理,某些周期性的行为可能误报为异常。实际数据中,每天固定时段的峰值数据相对于大部分采样点都可能被判定为异常,但实际为周期性正常现象。
数据并不是均匀分布的。像Netflix在两年中实现了高增长,算法需要足够健壮来处理非均匀分布的数据集(增长性数据是一个普遍现象,如长期来看的股市指数等)。
算法细节
Robust PCA是一个非常常见的主要成分提取算法。RPCA本质其实是一个矩阵分解算法。目标是将输入X分解为X=L+S+E。L代表了X的low rank approximation(低秩估计)。而低秩估计本质就是将矩阵中相关性强的行投影到更低维的线性空间,实现了一个降维平滑的功能,同时剔除了冗余信息,提取了矩阵特征。提取完主要成分L后,获得了剩下的稀疏矩阵S,和噪点E。
这里做异常检测的时候简单认为低秩矩阵L就能大部分还原输入序列。异常点的特征应该就表现在S或者E中。实际应用中可以把RPCA作为一个时间序列构造模型添加入EGADS中,用后者的异常检测模块提取异常。
Isolation Forest
上面两个项目使用了若干种类的异常检测算法。如基于模型的(统计模型,线性模型);基于距离的(K临近等聚类算法);基于密度模型的(Extreme Low Density Model)。隔离森林(Isolation Forest)跟他们都有比较明显的区别。论文代码(https://sourceforge.net/projects/iforest/?source=navbar)
在训练阶段,小样本抽样更利于获得优质的分类结果。
因为不用计算点与点直接的距离,计算时间大大优于各种基于距离的算法。
同样因为小样本抽样后迭代,时间、空间复杂度都可以维持在相当低的水平。
基于上一点,iForest有能力处理超高维,超大规模的数据。
iForest适用场景需要符合两个要求:1. 异常点非常少 2. 异常点的某些属性要跟正常点非常不同。
iForest是基于随机森林的算法。对异常的分类能力基于两个假设:
数据集中少数的异常点会形成少量的聚类。
异常点具有明显不同的属性,使他们很快在分类中被区分出来。正常点很难被分类,而存在于树的更深层。

上图横坐标表示了随机森林的迭代过程。选取一个异常点Xo和一个正常点Xi。纵轴代表了点Xo和Xi在迭代中被区分出时树深度的平均值。可以明显的看到,正常节点平均需要12次随机分类,而异常点只需要4次多就可以被区分出来。
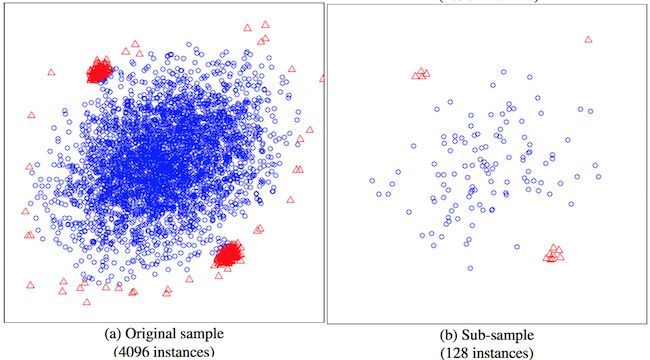
上图展示了小规模随机抽样同样可以达到非常好的聚类效果。这在处理大规模数据的时候尤其有用,在多篇文章中,iForest因为这一特性被推荐为首选算法。实现方面有R,Java,Python,搜索一下就有。
BENCHMARKING ALGORITHMS FOR DETECTING ANOMALIES IN LARGE DATASETS
这篇论文(http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.188.6153)使用了比较常见,简单易得的算法,基于学术界认可的标准数据集,进行了一系列性能,准确度试验,希望得到异常检测这一问题的一个基准。
本文使用了以下几种算法,因为是调用的Weka,所以算是比较简单的试验。
K邻近
多层神经网络(Multi-layer Perceptron) 可以简单认为是一个复杂参数学习的分类器。
基于密度的聚类算法:LOF (Local Outlier Factor)
随机森林(random forest)
Isolation Forest
经过一系列试验,结论中推举了以下步骤:
如果是维度非常高的数据,用J48选Attribute。
用iForest预选异常点,标准为score > 0.50
把ANN,J48,RF作为一个组合再处理2步得到的异常点。
被较多算法标注为异常的点就认为有高可信度。
主要数据集
KDDCUP99(http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html)网络流数据。常用入侵检测数据,学术界大量使用。不过据说后来被证明不太可靠。
Amazon监控数据(https://github.com/numenta/NAB/tree/master/data)Amazon EC2性能检测的真实检测数据,放出的数据有真实异常,并且有人工标注。
内部威胁数据(https://www.cert.org/insider-threat/tools/index.cfm)CERT人造的内部威胁数据。人造的方法还是比较科学的,不过异常模式比较简单,知道答案倒推就很容易。不过要自己发现异常就需要比较大的工作量了。
原文链接:https://www.jianshu.com/p/99b0452e55a4
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础
![]()