python爬虫入门之————————————————第二节--使用xpath语法获取数据
准备工作
⚫了解爬虫的数据处理体系结构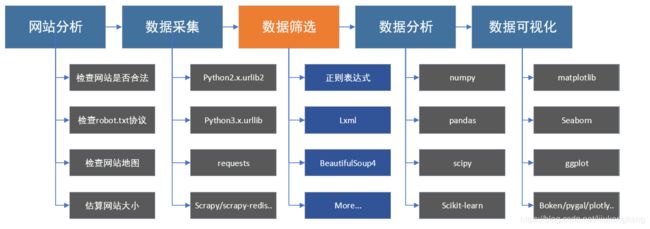
⚫ 处理数据的软件准备 采集到的结构化数据[如 html 网页文档数据] python 开发环境 lxml 第三方库 结构化数据基本理论:DOM 模型
1结构化数据
具备有一定的结构,有预定义规则的数据模型,统称为结构化数据 如:数据进行格式化展示的 HTML 文档中的数据、数据进行格式化传输的 XML 文档中的数据、数据进行格式化整理的 Excel 表格中的数据等等都是结构 化数据;同时按照表中行和列的形式进行数据整理的数据库中的数据,也是结构化数据
因为结构化数据有预定义规则的数据模型,所以可以被按照路径进行解析 爬虫采集的大都是网络上的网页数据,就常见的两种数据格式进行分析【html 网页文档数据、xml 数据文档】

2.xlml下载安装
官方网站:https://lxml.de/
下载安装:pypi 下载地址 https://pypi.org/project/lxml/#files 下载对应的 wheel 包,通过命令的方式直接安装即可
pip install lxml-4.2.5-cp36-cp36m-win32.whl
注意:下载离线包时切记注意安装依赖关系[依赖的python 平台版本和操作系统平台]
命令安装方式: 打开 windows 的命令行 or unix/linux 的 shell 窗口 通过包管理命令安装:pip install lxml
招聘网站的信息爬取
案例演示:
"""
Version 1.1.0
Author lkk
Email [email protected]
date 2018-11-20 15:38
DESC 招聘网站信息爬取
"""
from urllib import request
from fake_useragent import UserAgent
import chardet,pymysql
from lxml import etree
# 定义请求头
def getinfo():
ua = UserAgent()
headers = {
'User-agent': ua.random
}
url_list = [
'http://sydw.huatu.com/ha/zhaopin/1.html',
'http://sydw.huatu.com/ha/zhaopin/2.html',
'http://sydw.huatu.com/ha/zhaopin/3.html',
'http://sydw.huatu.com/ha/zhaopin/4.html',
'http://sydw.huatu.com/ha/zhaopin/5.html',
'http://sydw.huatu.com/ha/zhaopin/6.html',
'http://sydw.huatu.com/ha/zhaopin/7.html',
'http://sydw.huatu.com/ha/zhaopin/8.html',
'http://sydw.huatu.com/ha/zhaopin/9.html',
'http://sydw.huatu.com/ha/zhaopin/10.html',
]
for j in url_list:
start_url = request.Request(j, headers=headers)
response = request.urlopen(start_url)
content = response.read()
encoding = chardet.detect(content).get('encoding')
content = content.decode(encoding, 'ignore')
# print(content)
# 通过xpath直接提取其中的某个指定数据
docs = etree.HTML(content)
times = docs.xpath("//ul[@class='listSty01']/li/time/text()")
city = docs.xpath("//ul[@class='listSty01']/li/lm/a/text()")
info = docs.xpath("//ul[@class='listSty01']/li/a/text()")
for i in range(len(times)):
print(times[i], city[i], info[i])
mysql(times[i], city[i], info[i])
class DownMysql:
def __init__(self, times, city, info):
self.times = times
self.city = city
self.info = info
self.connect = pymysql.connect(
host='localhost',
db='data',
port=3306,
user='root',
passwd='123456',
charset='utf8',
use_unicode=False
)
self.cursor = self.connect.cursor()
# 保存数据到MySQL中
def save_mysql(self):
sql = "insert into invite(times, city, info) VALUES (%s,%s,%s)"
try:
self.cursor.execute(sql, (self.times, self.city, self.info))
self.connect.commit()
print('数据插入成功')
except Exception as e:
print(e)
# 新建对象,然后将数据传入类中
def mysql(times, city, info):
down = DownMysql(times, city, info)
down.save_mysql()
if __name__ == '__main__':
getinfo()
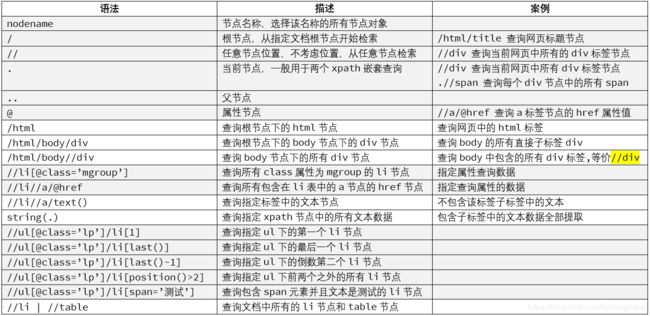
3.lxml-xpath常见的基本操作
电影天堂的爬取
import requests, chardet
from lxml import html
from fake_useragent import UserAgent
ua = UserAgent()
headers = {'User-agent': ua.random, 'cookie': None}
response = requests.get('http://www.dy2018.com', headers=headers)
content = response.content
encoding = chardet.detect(content).get('encoding')
content = content.decode(encoding, 'ignore')
docs = html.fromstring(content)
links = docs.xpath("//div[@class='co_content222']/ul/li/a")
for link in links:
print(link.xpath('string(.)').strip())