谷歌开源新模型 EfficientNet:图像识别效率提升 10 倍,参数减少 88%
转自:https://www.infoq.cn/article/w3-7SmYM6TecLmCh9QHO
卷积神经网络通常是再有限的资源下进行开发,然后在条件允许的情况下将其扩展到更大的计算资源上以获得更好的准确率。谷歌 AI 的科学家们在论文《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》中系统地研究了模型扩展的问题,并提出了新的复合扩展法以及一个更高性能的 EfficientNet,EfficientNet 模型的相关代码和 TPU 训练数据也已经在 GitHub 上开源。该论文已被 ICML2019 接收,AI 前线对其进行了简单地梳理总结,本文是 AI 前线第 81 篇论文导读。
介绍
模型扩展被广泛地用于提高卷积网络的准确性。例如,ResNet 系列可以通过增加层数从 ResNet-18 扩展到 ResNet-200。谷歌的开源神经网络训练库 GPipe 通过对基线网络的四倍扩展可以在 ImageNet 数据库上达到 84.3% 的 top-1 精度。然而,虽然有很多途径对卷积网络进行扩展,却鲜有工作对其进行深入的理解。许多先前的工作都是针对神经网络三个维度——深度、宽度和图像大小中的一个因素进行调整。虽然对其中任意两个或三个因素进行调整看起来是可行的,但实际上这需要大量的人工调参来达到勉强说的过去的提升。对于 EfficientNet 的效果,我们先来看张图:
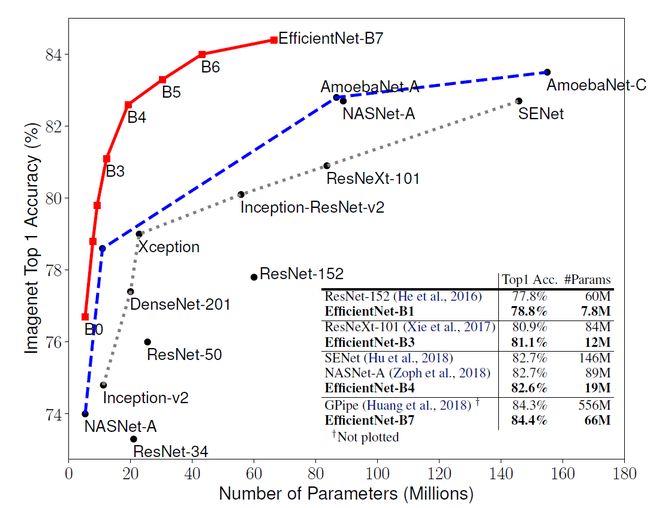
图中横坐标表示参数量,纵坐标表示 ImageNet 数据库上的 Top1 准确率。可以看出 EfficientNet 系列完胜了其他所有的卷积网络。其中,Efficient-B7 取得了新的最高准确率,达到了 84.4%。但是它的参数量相比 GPipe 减少了 8.4 倍,并且推理速度达到了 GPipe 的 6.1 倍。更加细节的数据可以参考后面的实验部分。
研究动机
这篇文章的作者对神经网路的扩展过程进行了研究与反思。特别的是,作者提出了一个思考:能否找到一个规范化的神经网络扩展方法可以同时提高网络的准确率和效率。要实现这点,一个很关键的步骤便是如何平衡宽度、深度和分辨率这三个维度。作者通过一些经验性的研究发现,可以使用一种固定比例的放缩操作简单地实现对三者的平衡。最终,作者提出了一种简单却有效的复合扩展方法(compound scaling method)。例如,对于一个标准的模型,如果想使用 2^N 倍的计算资源,作者认为只需要对网络宽度增加α^N,深度增加β^N,以及增加γ^N 倍的图像大小。其中α、β、γ是一组恒定系数,他们的值通过在原始的标准模型中使用小范围的网格搜索(grid search)得到。为了直观地说明本文提出的复合扩展方法与传统方法的区别,作者提供了下图作为参考:
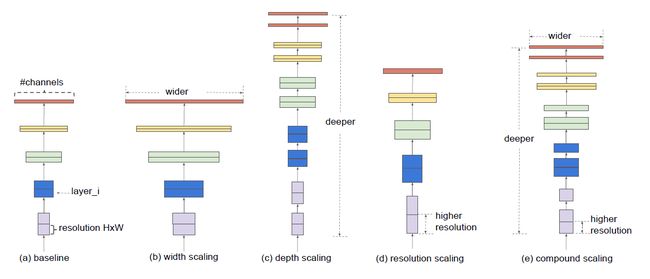
其中,(a)是一个基线网络,(b)到(d)是三种不同的传统方法,分别对宽度、深度和图像分辨率进行了扩展,(e)是本文提出的复合扩展方法,使用固定比率同时对三个维度进行了扩展。直观地讲,复合扩展法是说得通的。因为对于更大的输入图像,网络需要更多的层来增加感受野,同时需要更多的通道来获取细粒度的信息。总的来说这篇论文的核心工作主要分为两个方面:
-
提出了一种复合扩展方法,这是首次尝试同时对卷积网络的三种维度进行扩展的方法。该方法可以有效地提升现有的网络结构在大规模计算资源上的训练效果。
-
设计了一种新的性能卓越的网络结构——EfficientNet。该网络不仅性能远超其他网络结构,网络参数还更少,推理速度更快。
复合模型扩展方法
这一部分将为大家详细介绍什么是网络扩展问题,并对不同的方法进行了研究,从而引出我们的主角:复合扩展法。
问题建模
卷积网络的本质是一个映射函数,这个函数可以写为下面这个形式:
![]()
其中 Fi 表示第 i 层进行的运算,Xi 是输入的张量,我们假设这个张量的大小为:
通常,我们会使用多个叠加的子模块来组成完整的卷积网络。例如 ResNet 由 5 个子模块构成,也被称为五个阶段。除了第一个阶段进行了降采样外,每个阶段中的所有层的卷积操作都是一样的。因此,神经网络也可以被定义为下面这个形式(公式(1)):
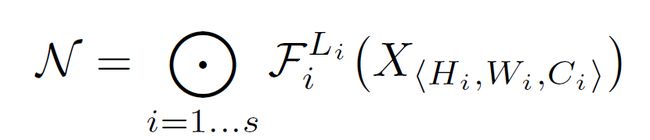
其中,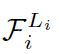 表示的是层 Fi 在第 i 阶段被重复了 Li 次。
表示的是层 Fi 在第 i 阶段被重复了 Li 次。
对于一个神经网络,作者假定所有的层都必须通过相同的常数比例进行统一的扩展。因此,模型扩展问题的可以表示为(公式(2)):
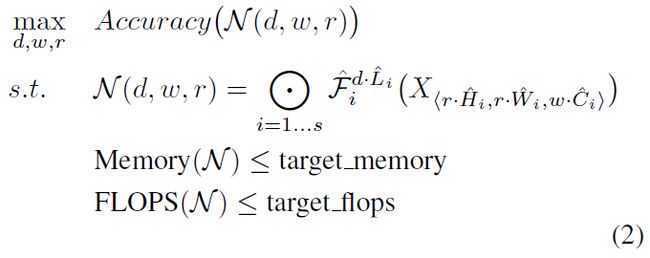
其中 w,d,r 分别是扩展网络的宽度、深度和分辨率。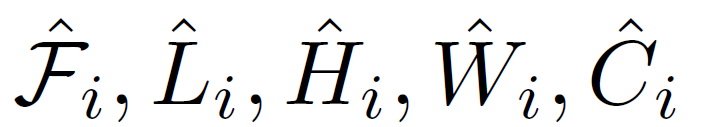 是基线网络中预定义的网络参数。
是基线网络中预定义的网络参数。
单维度扩展
解决公式(2)的一个难点就在于 d,w,r 彼此依赖,并且会由于不同的资源条件所改变。传统方法主要集中于独立地解决其中一个维度的扩展问题。下图是改变每个维度对模型性能影响的部分实验结果:
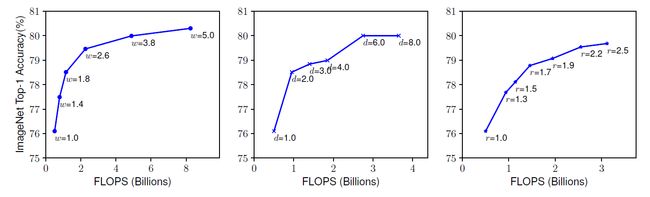
图中从左至右分别表示的是不同宽度、深度、分别率系数对模型性能的影响。随着宽度、深度、分辨率的提高,更大的网络会获得更好的准确率。但是,在达到 80% 后,准确率很快就趋于饱和,这说明了单维度的扩展是具有局限性的。这里的实验结果均使用的是 EfficientNet-B0 作为基线网络,具体结构如下表所示:
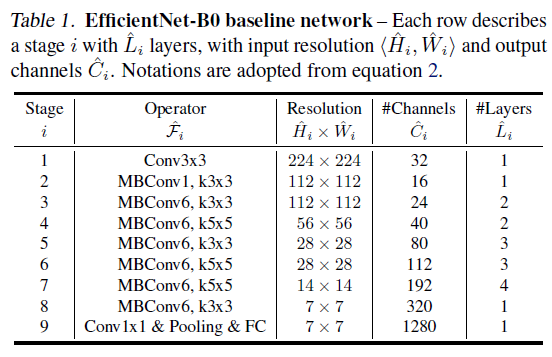
表 1:EfficientNet-B0 网络,每一行表示多层网络的某个阶段,resolution 输入张量大小,Channels 表示输出通道数。表中的符号与公式(1)中的符号意思
通过这一部分的比较作者得出:
观察 1:对网络的宽度、深度以及分辨率中的任意一项做扩展都可以提高其准确率,但是随着模型越来越大,这种提升会逐渐缩小。
复合扩展
实际上,不同的扩展维度之间并不是各自独立的。直观地讲,对于更高分辨率的图像,应当使用更深的网络,这样会有更大的感受野对图像进行采样与特征提取。同样的,网络的宽度也应该增加,这是为了通过分高分辨图像中更多的像素点来捕获更加细粒度的模式。基于上述直觉,本文的作者做出了一个假——“我们应当平等地对不同的扩展维度进行平衡,而不是像传统方法那样仅进行单维度扩展。”
为了验证这个假设,作者比较了不同深度和分辨率下对网络进行宽度扩展时的实验结果:
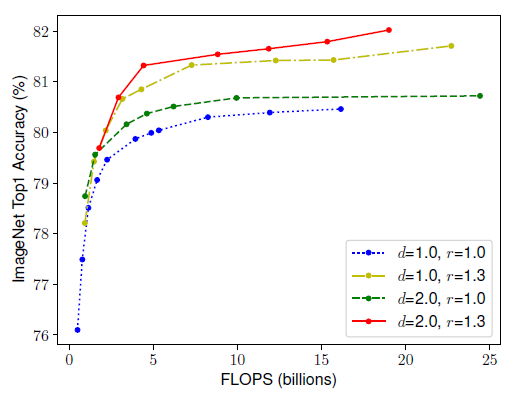
上图中每条线上的每个点表示模型在不同宽度系数配置下的效果。所有的基线网络都使用表 1 中的结构。第一个基线网络(d=1.0,r=1.0)有 18 个卷积层,其输入的分辨率是 224224。最后一个基线网络(d=2.0,r=1.3)有 36 个卷积层,输入分辨率为 299299。可以看出,在宽度不变得情况下,如果仅改变深度和分辨率,准确率很快趋于饱和。在 FLOPS(每秒浮点运算次数)消耗相同的情况下,分辨率更高、网络更深的模型可以获得更好的准确度。通过这部分分析,作者得出:
观察 2:为了得到更好的准确率和效率,在卷积网络扩展中,平衡网络的宽度、深度和分辨率这三种维度是非常关键的一步。
事实上,一些类似的工作也尝试过随机的平衡网络的宽度和深度,但是这些工作都需要冗长的手动微调。与上述方法不同,本文的作者提出了一种新的复合扩展方法。该方法使用一个复合系数Φ通过一种规范化的方式统一对网络的深度、宽度和分辨率进行扩展:
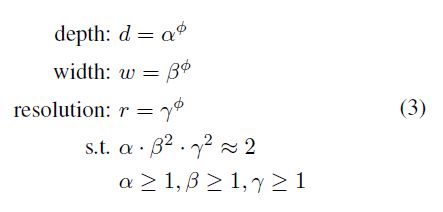
其中α,β,γ是常数,它们有小型网络搜索确定。Φ则是一个由用户指定的扩展系数,它用来控制到底有多少资源是模型扩展可用的。对于一般的卷积操作,其 FLOPS 需求与 d,w^2,r^2 是成比例的。由于卷积网络中最消耗计算资源的通常是卷积操作,因此使用公式(3)对网络进行扩展会导致总 FLOPS 近似变为![]() 。本文中作者使用公式
。本文中作者使用公式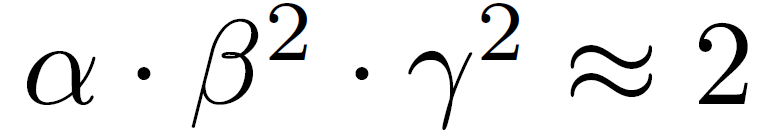 对这三个参数进行了约束,因此,总 FLOPS 增加 2^Φ。
对这三个参数进行了约束,因此,总 FLOPS 增加 2^Φ。
EfficientNet 结构
上面提到的模型扩展方法并不会改变基线网络中每一层的运算操作,因此要想提升模型的准确率,有一个好的基线网络也非常重要。在实验部分,作者使用现有的卷积网络对复合扩展法进行了评估。但是为了更好地展示复合扩展法的有效性,作者设计了一个新的轻量级基线网络 EfficientNet。(注:这里的轻量级网络表示可用于移动端的参数较少的卷积网络。)
EfficientNet 的结构已经在表 1 中列出,它的主干网络是由 MBConv 构成,同时作者采取了 squeeze-and-excitation 操作对网络结构进行优化(见 SENet,ILSVRC 2017 冠军)。对于 Efficient-B0,若要使用复合扩展法对其进行扩大需要通过两步来完成:
-
第一步:首先将Φ固定为 1,假设至少有两倍以上的资源可用,通过公式(2)和公式(3)对α,β,γ进行网格搜索。特别的是,对于 EfficientNet-B0,在约束条件
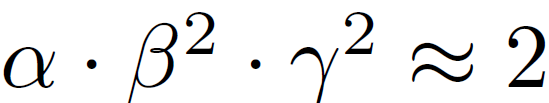 下,α,β,γ分别为 1.2,1.1 和 1.15 时网络效果最好。
下,α,β,γ分别为 1.2,1.1 和 1.15 时网络效果最好。 -
第二步:α,β,γ作为常数固定,然后通过公式(3)使用不同Φ对基线网络进行扩展,得到 EfficientNet-B1 到 EfficientNet-B7
这里之所以仅在小的基线网络上使用网格搜索(步骤 1)然后直接将参数扩展到大的模型上(步骤 2)是因为如果直接在大模型上进行参数搜索是非常昂贵且不可行的,因此作者采用了这种两步走的方法确定模型的扩展参数。
实验这一部分,作者首先对在广泛使用的 MobileNets 以及 ResNets 上对他们提出的模型扩展法进行了验证。其实验结果如表三所示:
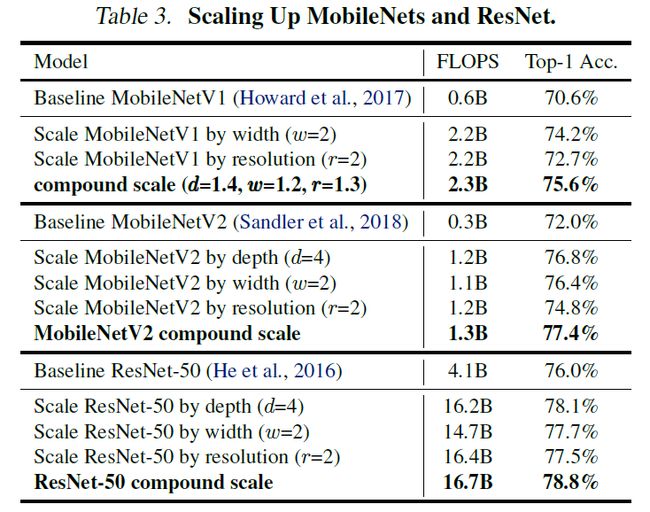
与单维度的扩展方法相比,复合扩展法在三种网络模型上都有所提升,这说明复合扩展法对于目前的现有网络都是有效的。
随后,作者在 ImageNet 数据库上对 EfficientNet 进行了训练。实验结果表明 EfficientNet 模型在参数量和 FLOPS 方面比其他卷积网络少一个数量级却能得到近似的准确率。特别是 Efficient-B7 在 top1 达到了 84.4% 在 top5 达到了 97.1%,比 GPipe 更加准确但模型小了 8.4 倍:

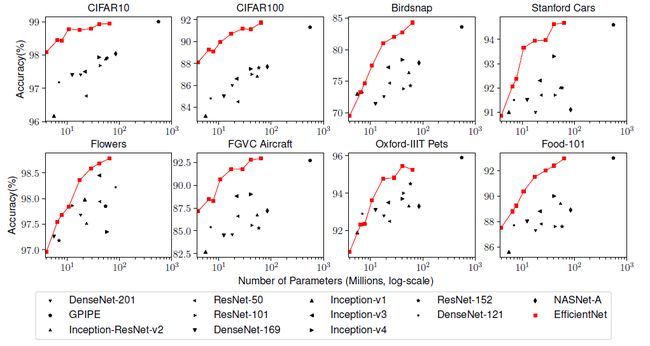
同时,作者也在常用的迁移学习数据集上对 EfficientNet 进行了评估。EfficientNet 的性能较其他类型的网络均有一致的提升。实验结果如下图所示:
为了更深入地理解复合扩展法能取得更好效果的原因,作者对网络的激活图进行了可视化。比较了相同配置的基线网络经过不同的扩展方法后激活图的变化:
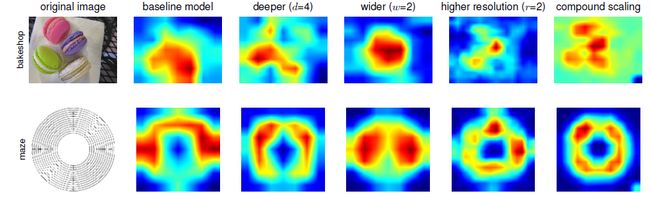
可以看出复合扩展法使得模型更加关注与目标细节相关的区域,而其他配置下的模型则无法很好的通过图像捕捉目标的细节信息。
总结
本文作者通过对模型扩展方法方面存在地问题进行了讨论,从如何权衡网络的深度、宽度以及分辨率方面出发提出了复合扩展方法。并在两种网络结构 MobileNets 和 ResNet 上对这种扩展方法进行了验证。此外,作者还通过神经结构搜索设计了一种新的基线网络 EfficientNet,并对其进行扩展得到了一系列的 EfficientNets。在图像分类标准数据集上,EfficientNets 超越了之前的卷积网络,并且 EfficientNet 参数量更少、推理过程更快。
论文原文链接:https://arxiv.org/abs/1905.11946
开源代码地址:
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet