BP神经网路【附源码】--2018华为软件挑战赛总结
今天,5/15号,在这华为软件挑战赛后一个月时间里, 本来是不打算写这篇文章的 ,原因还是因为队友问题。
软件挑战赛在没开始前一个星期,通过贴吧、公众号、朋友圈信息散播招募队友的信息,最后招募两个比较有激情的队友,一个是电子科大的研究生,另外一个是擅长全能分析的同班同学。 从招募的队友来看,一个是电子科大,能考上这所学校的,高数必定不会差劲(头脑肯定不错),另外一个(擅长全能型,这种人涉及的范围很多,对不同事物的思考会有不一样的建议)。 但很遗憾,这些都是理想的,最终两位队友一一放弃了,第一个,看了题目以后,就不在出现了,怎么也联系不上,也不说话,不讨论。第二个,电子科大,也扛受不住压力,最终也放弃了,没办法,我只能每天下班就回来熬,每熬到半夜 一两点,每天晚上吃外卖的时候,巴不快点吃完,挤出时间来做。
此次比赛题目是关于利用虚拟机历史申请使用记录来预测未来一周虚拟机的申请情况,并对预测的虚拟机合理分配到服务器上,具体内容可参考:http://codecraft.devcloud.huaweicloud.com/home/detail
一、选择语言编程。
针对题目的原意,我们是要通过历史数据,去预测未来的数据,这里明显用到了神经网络,在数据处理和神经网络利用方面,python都是不二的选择,毅然选择了Python进行编程,在后面会附上源码。
二、模型选择
经常多方面的考虑,预测模型,最终选择了Bp神经网络。
下面对BP神经网络进行讲解:
人工神经网络是一种经典的机器学习模型,随着深度学习的发展神经网络模型日益完善,很多人对人工神经网络的认识很迷茫,不知道它是怎么样的一种事物,在这里举一个例子说明,我们的目的是通过神经网络去获取未来的数据。 但怎么样才能得到呢? 我们必定需要有一个模型,即函数,通过x 输入,得到 y输出。 神经网络的作用就是构建函数。
一、神经网络原理
经典的BP神经网络通常由三层组成: 输入层, 隐含层与输出层.通常输入层神经元的个数与特征数相关,输出层的个数与类别数相同, 隐含层的层数与神经元数均可以自定义.。

每个神经元代表对数据的一次处理::

每个隐含层和输出层神经元输出与输入的函数关系为:
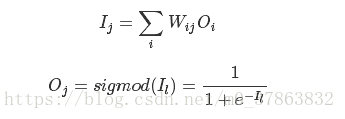
其中WijWij表示神经元i与神经元j之间连接的权重,OjOj代表神经元j的输出, sigmod是一个特殊的函数用于将任意实数映射到(0,1)区间.
上文中的sigmod函数称为神经元的激励函数(activation function), 除了sigmod函数11+e−Il11+e−Il外, 常用还有tanh和ReLU函数.
我们用一个完成训练的神经网络处理回归问题, 每个样本拥有n个输入.相应地,神经网络拥有n个输入神经元和1个输出神经元.
实际应用中我们通常在输入层额外增加一个偏置神经元, 提供一个可控的输入修正;或者为每个隐含层神经元设置一个偏置参数.
我们将n个特征依次送入输入神经元, 隐含层神经元获得输入层的输出并计算自己输出值, 输出层的神经元根据隐含层输出计算出回归值.
上述过程一般称为前馈(Feed-Forward)过程, 该过程中神经网络的输入输出与多维函数无异.
现在我们的问题是如何训练这个神经网络.
作为监督学习算法,BP神经网络的训练过程即是根据前馈得到的预测值和参考值比较, 根据误差调整连接权重WijWij的过程.
训练过程称为反向传播过程(BackPropagation), 数据流正好与前馈过程相反.
首先我们随机初始化连接权重WijWij, 对某一训练样本进行一次前馈过程得到各神经元的输出.
首先计算输出层的误差:
Ej=sigmod′(Oj)∗(Tj−Oj)=Oj(1−Oj)(Tj−Oj)
其中EjEj代表神经元j的误差,OjOj表示神经元j的输出, TjTj表示当前训练样本的参考输出, sigmod′(x)sigmod′(x)是上文sigmod函数的一阶导数.
计算隐含层误差:
Ej=sigmod′(Oj)∗∑kEkWjk=Oj(1−Oj)∑kEkWjk
隐含层输出不存在参考值, 使用下一层误差的加权和代替(Tj−Oj)(Tj−Oj).
计算完误差后就可以更新WijWij和θjθj:
Wij=Wij+λEjOi
Wij=Wij+λEjOi
其中λλ是一个称为学习率的参数,一般在(0,0.1)区间上取值.
实际上为了加快学习的效率我们引入称为矫正矩阵的机制, 矫正矩阵记录上一次反向传播过程中的EjOiEjOi值, 这样WjWj更新公式变为:
Wij=Wij+λEjOi+μCij
Wij=Wij+λEjOi+μCij
μμ是一个称为矫正率的参数.随后更新矫正矩阵:
Cij=EjOi
Cij=EjOi
每一个训练样本都会更新一次整个网络的参数.我们需要额外设置训练终止的条件.
最简单的训练终止条件为设置最大迭代次数, 如将数据集迭代1000次后终止训练.
单纯的设置最大迭代次数不能保证训练结果的精确度, 更好的办法是使用损失函数(loss function)作为终止训练的依据.
损失函数可以选用输出层各节点的方差:
L=∑j(Tj−Oj)2
L=∑j(Tj−Oj)2
为了避免神经网络进行无意义的迭代, 我们通常在训练数据集中抽出一部分用作校验.当预测误差高于阈值时提前终止训练。
Python实现预测模型
#!/usr/bin/python
# -*- coding: UTF-8 -*-
###############################################################
#函数名字 : predictor
#函数功能描述 : 这里编写预测函数
#作者 :石润发
#修改 :
# 1.开始编?2018-03-16 21:06:19
# 2.add 对历史数据和输入文件进行切片处理 2018-03-17 11:44:19
# 3.add 将input文件信息全部存贮在全局变量里面 2018-3-17
# 4.bug test()函数里面,复制一个新的二维数组,操作会被随之改变 2018-3-20已解决
# 5.对总数量和各规格数量进行归一化处理,出现反归一化后对不上 2018-3-26
# 6.解决思路错了,需要对输入文件中指定预测的规格进行预测 2018-3-26
# 7,对输入文件进行数据分析,提取历史训练数据中的预测规格。2018-3-27
# 8,对提取输入文件规格。2018-3-28
# 9,对预测出来规格,进行装箱。2018-3-29
# 10,讲实现装箱方案写入文件,并保存。2018-4-1
###############################################################
import math
import random
import copy
import collections
##########全集变量####################
cpu_core_num =0 #CPU核数
mem_num =0 #内存大小
disk_num =0 #硬盘大小
input_vm_species_num =0 #虚拟机规格数
input_vm_data ='' #虚拟机数据:规格名称n CPU核数 内存大小(MB?
need_optimize ='' #需要优化的名称
predict_start ='' #预测的开始时间
predict_end ='' #预测的结束时间
time_sum =[]
normalized_time=[]
min_time =0
max_time =0
result =[]
uuid =[]
flavorName =[]
createTime =[]
train_spc =[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
train_data =[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
train_data_zuhe=[]
labels =[]
flavor_spec =[]
predict_end_time=0
predict_start_time=0
future_sum =0
###########################################
def rand(a, b):
return (b - a) * random.random() + a
##########################################################
#函数名字 :list_cut
#函数功能描述 :二维列表切
#函数参数 : list :列表 num:列表维度,0表示第一列,1表示第二列
#返回值 :返回切片出来的列数
#作者 :runfashi
##########################################################
def list_cut(list,num):
list_num=[]
for i,item in enumerate(list):
list_num.append(item[num])
return list_num
##########################################################
#函数名字 :make_matrix
#函数功能描述:创造一个指定大小的矩阵
#函数参数 : 行、列
#作者 :runfashi
##########################################################
def make_matrix(m, n, fill=0.0):
mat = []
for i in range(m):
mat.append([fill] * n)
return mat
##########################################################
#函数名字 : sigmoid
#函数功能描述:激励函数
#函数参数 : x
#作者 :runfashi
##########################################################
def sigmoid(x):
return 1.0 / (1.0 + math.exp(-x))
##########################################################
#函数名字 : sigmoid_derivative
#函数功能描述:激励函数的导数
#函数参数 : 逆向输入
#返回值 :输出x
#作者 :runfashi
##########################################################
def sigmoid_derivative(x):
return x*(1-x)
##########################################################
#函数名字 : normalized
#函数功能描述:归一化数据(0-1?#函数参数 : x 输入? max最大?min 最小?#返回? ?输入归一化的?#作? ;runfashi
##########################################################
def normalized(x,max,min):
return ((x-min)*1.0)/((max-min)*1.0)
##########################################################
#函数名 : num_flavor
#函数功能描述:字符串转化为数字
#函数参数 : str1: 输入规格字符串 例如 flavor4
#返回值 : 返回 4
#作者 :runfashi
##########################################################
def num_flavor (str1):
return int(str1[6:])
##########################################################
#函数名字 : fan_normalized
#函数功能描述:反归一化数据
#函数参数 : x 输入, max最大,min 最小
#返回值 :输出反归一化数据
#作者 :runfashi
##########################################################
def fan_normalized(x,max,min):
return x[0]*(max-min)+min
##########################################################
#函数? : time_int
#函数功能描述:将时间转化为多少秒 数
#函数参数 : time 时间字符串,例如2015-01-01 19:03:32
#返回值 :返回预测结果
#作者 :runfashi
##########################################################
def time_int(time):
y_m_d =time.split("-")
year =int(y_m_d[0])
mon =int(y_m_d[1])
day =int(y_m_d[2])
return (year*365+mon*30+day)
##########################################################
#函数名 : file_math
#函数功能描述:根据文件内容,查询匹配字符串的数目
#函数参数 : train_data 训练数据 data 匹配字符串
#返回值 : 返回匹配到的数量
#作者 :runfashi
##########################################################
def file_math(train_data,data):
print("1")
##########################################################
#函数名 : judge_vm_spc
#函数功能描述:判断虚拟机的规格
#函数参数 : str1 虚拟机的规格 例如“flavor1”
#返回值 : 返回虚拟机的cpu核数,和mem大小
#作者 :runfashi
##########################################################
def judge_vm_spc(str1):
if str1=="flavor1":
return [1,1]
if str1=="flavor2":
return [1,2]
if str1=="flavor3":
return [1,4]
if str1=="flavor4":
return [2,2]
if str1=="flavor5":
return [2,4]
if str1=="flavor6":
return [2,8]
if str1=="flavor7":
return [4,4]
if str1=="flavor8":
return [4,16]
if str1=="flavor9":
return [8,8]
if str1=="flavor10":
return [8,8]
if str1=="flavor11":
return [8,16]
if str1=="flavor12":
return [8,32]
if str1=="flavor13":
return [16,16]
if str1=="flavor14":
return [16,32]
if str1=="flavor15":
return [16,64]
#########################################################
#类名 :BPNeuralNetwork
#描述 :BP神经网络类
#########################################################
class BPNeuralNetwork:
def __init__(self):
self.input_n = 0 #输入神经元数量
self.hidden_n = 0 #隐含层神经元数量
self.output_n = 0 #输出神经元数量
self.input_cells = []
self.hidden_cells = []
self.output_cells = []
self.output_cells = []
self.input_weights = [] #输入神经元权重
self.output_weights = [] #输出神经元权重
self.input_correction = [] #输入校正
self.output_correction = [] #输出校正
#初始化神经网络
def setup(self, ni, nh, no):
self.input_n = ni + 1
self.hidden_n = nh
self.output_n = no
# 初始化神经元
self.input_cells = [1.0] * self.input_n
self.hidden_cells = [1.0] * self.hidden_n
self.output_cells = [1.0] * self.output_n
# 初始化神经元之间的权重矩阵
self.input_weights = make_matrix(self.input_n, self.hidden_n)
self.output_weights = make_matrix(self.hidden_n, self.output_n)
# 随机赋值权重
for i in range(self.input_n):
for h in range(self.hidden_n):
self.input_weights[i][h] = rand(-0.2, 0.2)
for h in range(self.hidden_n):
for o in range(self.output_n):
self.output_weights[h][o] = rand(-2.0, 2.0)
# 初始化校正矩阵
self.input_correction = make_matrix(self.input_n, self.hidden_n)
self.output_correction = make_matrix(self.hidden_n, self.output_n)
#预测函数
def predict(self, inputs):
# 激活输入层
for i in range(self.input_n - 1):
self.input_cells[i] = inputs[i]
# 激活隐含层
for j in range(self.hidden_n):
total = 0.0
for i in range(self.input_n):
total += self.input_cells[i] * self.input_weights[i][j]
#激励函数
self.hidden_cells[j] = sigmoid(total)
# 激活输出层
for k in range(self.output_n):
total = 0.0
for j in range(self.hidden_n):
total += self.hidden_cells[j] * self.output_weights[j][k]
self.output_cells[k] = sigmoid(total)
#返回输出什么神经元列表
return self.output_cells[:]
#反向传播和更新权值, 并返回最终预测误差
def back_propagate(self, case, label, learn, correct):
# 正向
self.predict(case)
# 得到输出层的误差
output_deltas = [0.0] * self.output_n
for o in range(self.output_n):
error = label[o] - self.output_cells[o]
output_deltas[o] = sigmoid_derivative(self.output_cells[o]) * error
# 得到隐含层误差
hidden_deltas = [0.0] * self.hidden_n
for h in range(self.hidden_n):
error = 0.0
for o in range(self.output_n):
error += output_deltas[o] * self.output_weights[h][o]
hidden_deltas[h] = sigmoid_derivative(self.hidden_cells[h]) * error
# 更新输出权重
for h in range(self.hidden_n):
for o in range(self.output_n):
change = output_deltas[o] * self.hidden_cells[h]
self.output_weights[h][o] += learn * change + correct * self.output_correction[h][o]
self.output_correction[h][o] = change
# 更新输入权重
for i in range(self.input_n):
for h in range(self.hidden_n):
change = hidden_deltas[h] * self.input_cells[i]
self.input_weights[i][h] += learn * change + correct * self.input_correction[i][h]
self.input_correction[i][h] = change
# get global error
error = 0.0
for o in range(len(label)):
error += 0.5 * (label[o] - self.output_cells[o]) ** 2
return error
#训练函数
#case训练数据,labels训练结果,limit训练册数,learn学习率 ,correct校正系数
def train(self, cases, labels, limit=10000, learn=0.05, correct=0.1):
for j in range(limit):
error = 0.0
for i in range(len(cases)):
label = labels[i]
case = cases[i]
error += self.back_propagate(case, label, learn, correct)
def test(self,input_data,lable_data):
global max_time
global min_time
global predict_end_time
global predict_start_time
global future_sum
#print("input_data",input_data)
print("input_data",input_data)
print("lable_data",lable_data)
#归一化输入数据input_data
for i,item in enumerate(input_data):
input_data[i] = normalized(input_data[i],max_time,min_time)
#print("input_data",input_data)
#归一化真实数据lable_data
for i,item in enumerate(lable_data):
lable_data[i] = normalized(lable_data[i],100,0)
#print("lable_data",lable_data)
#将数据变成二维列表
input_data2=[]
lable_data2=[]
for i in input_data:
input_data2.append([i])
for i in lable_data:
lable_data2.append([i])
input_cell_num =1
output_cell_num=1
print("input_data2",input_data2)
print("lable_data2",lable_data2)
#隐含层选择怎么选择? 学习率和校正系数?
self.setup(input_cell_num,3,output_cell_num)
#输入 输出 训练次数 学习率 校正系数
self.train(input_data2, lable_data2, 10000,0.01, 0.0001) ##参数为 10000 3 0.5 效果不错
#检验原来的输入 是否和输出lable 一样
for case in input_data2:
print(self.predict(case))
"""
#预测模型成型后,预测未来数据
inpute_future_data = []
for i in range(predict_start_time,predict_end_time+1):
inpute_future_data.append(i)
#print(max_time,min_time)
print("inpute_future_data",inpute_future_data)
#归一化未来数据
for i,item in enumerate(inpute_future_data):
inpute_future_data[i] = normalized(inpute_future_data[i],max_time,min_time)
print("inpute_future_data",inpute_future_data)
#将未来数据变成二维列表
inpute_future_data2=[]
for i in inpute_future_data:
inpute_future_data2.append([i])
print("inpute_future_data2",inpute_future_data2)
future_num=0.0
for case in inpute_future_data2:
to = fan_normalized(self.predict(case),100,0)
print("----future data----:",to)
future_num +=to
print("future_num",round(future_num))
future_sum+=round(future_num)
return int(round(future_num))
"""
return 0
##########################################################
#函数名 :data_process
#函数功能描述:数据处理
#函数参数 : ecs_lines 历史数据 input_lines 输入文件
#返回值 : 返回预测结果
#作者 ;runfashi
##########################################################
def data_test(ecs_lines, input_lines):
global input_vm_data
global input_vm_species_num
global predict_start
global predict_end
global train_data
global train_spc
global max_time
global min_time
global predict_start_time
global predict_end_time
global result
global need_optimize
global cpu_core_num
global mem_num
global future_sum
if ecs_lines is None:
print 'ecs information is none'
return result
if input_lines is None:
print 'input file information is none'
return result
print(input_lines)
#对输入文件的数据进行切片
line = 1
for item in input_lines:
if line==1:
line1= item.split(" ")
cpu_core_num = line1[0] #CPU核数56
mem_num = line1[1] #内存大小128
disk_num = line1[2] #硬盘大小1200
if line==3:
line3= item.split(" ")
input_vm_species_num = item[0]
if line>=4 and line<=(3+int(input_vm_species_num)):
input_vm_data=input_vm_data+item
if line ==(4+1+int(input_vm_species_num)):
need_optimize = item #CPU
if line ==(5+2+int(input_vm_species_num)):
predict_start = item # 2015-02-20 00:00:00
if line ==(6+2+int(input_vm_species_num)):
predict_end = item #2015-02-27 00:00:00
line+=1
#对开始时间和结束时间化为天数,
predict_start_y_m_d=predict_start.split(" ")[0]
predict_start_time = time_int(predict_start_y_m_d)
predict_end_y_m_d=predict_end.split(" ")[0]
predict_end_time = time_int(predict_end_y_m_d)
max_time=predict_end_time
#得出最大天数
"""
print("predict_end",predict_end)
print("max_time",max_time)
print("predict_end_time",predict_end_time)
print("predict_start_time",predict_start_time)
"""
#将需要预测的规格提取出来
#['flavor2', 'flavor3', 'flavor4', 'flavor5', 'flavor10', 'flavor10', '']
input_vm_data_list=input_vm_data.split("\n")
input_vm_data_list.pop(-1)
for item in input_vm_data_list:
j=item.split(" ")
flavor_spec.append(j[0])
print(flavor_spec)
#建立多个列表,数量由输入文件的规格决定
#flavor1-n = []
for i in range(len(flavor_spec)):
exec("flavor"+str(i+1)+"=[]")
exec("fla_num"+str(i+1)+"=[]")
"""
56498c50-84e4 flavor15 2015-01-01 19:03:32
56498c51-8cb9 flavor15 2015-01-01 19:03:34
56498c52-a50e flavor8 2015-01-01 23:26:04
56498c53-a241 flavor2 2015-01-02 18:25:23
56498c54-8528 flavor8 2015-01-02 21:03:49
"""
#遍历 历史数据并对数据进行切片
for i,item in enumerate(ecs_lines):
values = item.split("\t")
uuid.append(values[0]) #56498c50-84e4
flavorName.append(values[1]) #flavor15
createTime.append(values[2]) # 2015-01-01 19:03:32
num_fla=num_flavor(values[1])
time_y_m_d=values[2].split(" ")[0] #time_y_m_d = '2015-01-01'
item2=time_int(time_y_m_d) #item2 = 78213xx
if i==0:
min_time = item2
#遍历历史数据过程中,判断规格和预测规格是否相等
#如果相等,添加日期到列表当中
for j,it in enumerate(flavor_spec):
if it==values[1]:
exec("flavor"+str(j+1)+".append(item2)")
#对重复数删除
for f,item in enumerate(flavor_spec):
exec("fla"+str(f+1)+"=list(set(flavor"+str(f+1)+"))")
exec("fla"+str(f+1)+".sort(key=flavor"+str(f+1)+".index)")
#历史数据中预测规格的数量
#for i in len(flavor_spec):
for i in range(len(flavor_spec)):
exec("for j in fla"+str(i+1)+""":
fla_num"""+str(i+1)+".append(flavor"+str(i+1)+".count(j))")
"""
#列表变量说明:fla_numx 预测规格的数量 flax:预测规格在历史数据中出现的时间
print(fla_num1)
print(fla_num2)
print(fla_num3)
print(fla_num4)
print(fla_num5)
print(fla1)
print(fla2)
print(fla3)
print(fla4)
print(fla5)
#删除相同天数的时间
print("预测规格在历史中出现的时候")
print(flavor1)
print(flavor2)
print(flavor3)
print(flavor4)
print(flavor5)
"""
#nn = BPNeuralNetwork()
#nn.test(fla2,fla_num2)
predict_vm_data=""
#实例化多个预测模型
for i in range(len(flavor_spec)):
nn = BPNeuralNetwork()
exec("fla_predict_num=nn.test(fla"+str(i+1)+",fla_num"+str(i+1)+")")
#输出每种规格的名称和数量
exec("""predict_vm_data +="flavor"+str(i+1)+" "+str(fla_predict_num)""")
predict_vm_data=predict_vm_data+"\r\n"
#按照规格说明输出预测结果
result.append("%d\r\n"%(int(future_sum)))
result.append("\r\n")
result.append(predict_vm_data)
#按照规格说明输出部署方案
#部署方案说明:采用首次适应算法+最佳适用算法
#通俗理解为,先放最大的规格虚拟机,放到快满了的时候,放最小的规格下去,
#使得cpu利用率到最高(但提前内存不能够超,否则得零分)
physical_source=[int(cpu_core_num),int(mem_num)]
if need_optimize=="CPU\r\n" or need_optimize=="CPU\n":
#print("need_optimize",need_optimize)
#print(predict_vm_data)
place_data = predict_vm_data.split("\r\n")
place_data.pop()
for i,item in enumerate(place_data):
place_data[i]=item.split(" ")
#print(place_data)
#建立列表
list_place = []
for i in place_data:
for j in range(int(i[1])):
list_place.append(i[0])
deployment_data = [] #部署数据
#初始化物理服务器的id数目
#循环放置future_sum这么多次
#有待改进
physical_id =1
for i in range(int(future_sum)):
place_data_len=len(place_data)-1
if len(list_place)>0:
#提取一个规格,然后判断放置的是哪种规格
place_type=judge_vm_spc(list_place[-1])
else:
break
#先放置大的规格
if physical_source[0]>place_type[0] and physical_source[1]>place_type[1]:
deployment_data.append([physical_id,list_place[-1]])#放置
del list_place[-1] #从列表删除一个规格
#资源减少
physical_source[0]=physical_source[0]-place_type[0] #CPU
physical_source[1]=physical_source[1]-place_type[1] #MEM
#如果大规格放不下了,判断是否还有资源
elif physical_source[0]>0 and physical_source[1]>0:
if len(list_place)>0:
##提取最小的规格,然后判断放置的是哪种规格
place_type=judge_vm_spc(list_place[0])
else:
break
#如果可以放下最下的规格,就放置
if physical_source[0]>place_type[0] and physical_source[1]>place_type[1]:
deployment_data.append([physical_id,list_place[0]])#放置
del list_place[0]
#如果放置不了,新建一个物理服务器
else:
physical_id+=1 #id 加1
physical_source=[int(cpu_core_num),int(mem_num)] #物理服务器资源重新变空
#print("deployment_data",deployment_data)
#跟据输出的数据,进行统计和去除重复
###################################################
id0=[]
id1=[]
for i in deployment_data:
id0.append(i[0])
id1 =list(set(id0))
#print(id1)
#需要的物理机的总数
place_phy_sum=len(id1)
#print("place_phy_sum",place_phy_sum)
dd = []
for i,ietm0 in enumerate(id1):
dd.append([ietm0])
for j,item1 in enumerate(deployment_data):
if item1[0]==ietm0:
dd[i].append(item1[1])
#print("dd",dd)
my_dd=[]
my_num=1
for i,item0 in enumerate(dd):
my_dd.append("\r\n")
my_dd.append(i+1)
for j,item1 in enumerate(item0):
if len(str(item1))>5:
if j != len(item0)-1:
if item1==item0[j+1]:
my_num+=1
else :
my_dd.append(item1)
my_dd.append(my_num)
my_num=1
else:
my_dd.append(item1)
my_dd.append(my_num)
my_num=1
##############################################
#列表转换字符串,然后按照格式转换下
#print("--",my_dd)
my_dd2 = [str(i) for i in my_dd]
#print(my_dd2)
my_dd3=""
for i in my_dd2:
if i =="\r\n":
my_dd3+=i
else:
my_dd3+=i+" "
#print(my_dd3)
result.append("\r\n")
result.append(place_phy_sum)
result.append(my_dd3) #将部署数据添加到输出里面
print(result)
if need_optimize=="MEM\r\n":
print("need_optimize",need_optimize)
return result