李宏毅学习笔记21.RNN Part II
文章目录
- 前言
- 训练
- Loss Function
- BPTT
- 训练技巧Clipping
- 悬崖形成原因简析
- 解决方案
- LSTM
- GRU
- Clockwise RNN
- Structurally Constrained Recurrent Network (SCRN)
- Fun Fact
- RNN其他应用
- Many to one
- Sentiment Analysis
- Key Term Extraction
- Many to Many (output is shorter)
- Speech Recognition
- Many to Many (No Limitation)
- Machine Translation
- Beyond Sequence
- Syntactic parsing
- Sequence-to-sequence Auto-encoder
- Text处理
- Speech处理
- Speech处理的应用实例
- 实例结果分析
- DEMO:Chat-bot圈霸
- Attention-based Model
- Attention-based Model应用:阅读理解(Reading Comprehension)
- Attention-based Model应用:看图说话(Visual Question Answering)
- Attention-based Model应用:人机对话(Speech Question Answering)
- RNN v.s. Structured Learning
- 整合案例:Speech Recognition
- 整合案例:Semantic Tagging:
前言
接上节内容:李宏毅学习笔记21.RNN Part I
继续来看RNN,上节虽然了解了RNN的构架,以及如何计算(前向传播过程),但是RNN如何训练(学习)的呢?我们一起来学习吧。
公式输入请参考:在线Latex公式
训练
Loss Function
先来看Loss Function,下面是RNN的Learning Target图:
1、图中输入的句子是有先后顺序的,不然就不知道memory中存的东西是什么;
2、输出就是上节课提到的slot
Cost就是每一个时间点的RNN的output和参考vector的交叉熵的和,就是要最小化的对象

BPTT
在DNN里面训练是使用GD,RNN当然也是一样,假设RNN的损失函数为 L L L,那么某个参数的计算公式如下图所示:

在DNN里面为了计算上图中的偏导,采用的方式的BP算法,在RNN对这个算法做了改进,变成了BPTT(Backpropagation through time),两个算法差不多的,但是RNN是运行在时序数据上的,所以在计算偏导过程中需要考虑时间的因素。
但是RNN不好train,如果训练RNN发现绿色的损失率曲线,并不意味程序有BUG。原因如下图所示:

训练技巧Clipping
Total Loss对于参数的偏导的曲面是很不平整的,有很多断崖,因此会出现好几种情况:
第一种:1→2→3跳跃到悬崖上
第二种:1→2→4踩到墙脚
第三种:1→2→4→5加大学习率后直接飞出去
解决方案在蓝字作者的博士论文中提出来的(这里有一段八卦),就是Clipping,给学习率设置上限,例如15,那么路径为1→2→4后加大学习率,但是只能加到15,这个时候就飞到6点继续训练6→7→8

为什么RNN会有这样的特性?是不是因为sigmoid函数会造成梯度消失?换成ReLU会不会解决这个问题?
答案是:sigmoid函数不是造成不平整的原因,且ReLU在RNN上表现并不如sigmoid。
悬崖形成原因简析
如果有详细讲或学习BPTT,会比较容易知道偏导曲面为什么会不平整,现在我们只需要简单的观察输入的变化对输出变化的影响,感性认识一下悬崖形成原因。先构建一个最最简单的RNN,它只有一个神经元,且使用线性函数做激活函数,input不考虑bias,input和output的weight都是1,transition(从memory接到input)部分的weight是w,现在的输入是100000…000,输出是什么?
秒算: y 1000 = w 999 y^{1000}=w^{999} y1000=w999

现在 w w w是我们要学习的参数,我们需要知道它的gradient,即改变 w w w的值对output有多大的影响。
现假设 w = 1 w=1 w=1则 y 1000 = w 999 = 1 y^{1000}=w^{999}=1 y1000=w999=1
若 w = 1.01 w=1.01 w=1.01则 y 1000 = w 999 ≈ 20000 y^{1000}=w^{999}≈20000 y1000=w999≈20000
从这里看到 w w w有很大的gradient,就是 ∂ L ∂ w \frac{\partial L}{\partial w} ∂w∂L很大,需要设置很小的learning rate。
若 w = 0.99 w=0.99 w=0.99则 y 1000 = w 999 ≈ 0 y^{1000}=w^{999}≈0 y1000=w999≈0
若 w = 0.01 w=0.01 w=0.01则 y 1000 = w 999 ≈ 0 y^{1000}=w^{999}≈0 y1000=w999≈0,就是在 w < 1 w<1 w<1的时候 ∂ L ∂ w \frac{\partial L}{\partial w} ∂w∂L很小,需要设置很大的learning rate。
可以明显看到设置learning rate很不方便,gradient也是时大时小。在很小的区域里面(1附近)gradient就会有很大的变化,当w小于1的时候gradient就会很平滑,都是0。
归根结底就是RNN把同样的东西在transition的时候反复使用。
解决方案
LSTM
LSTM Can deal with gradient vanishing (not gradient explode),这里由于没有平坦的地方,所以learning rate可以设置小一点。
面试题强行插入:为什么用LSTM替换RNN?
答:可以解决 gradient vanishing
问:为什么?
LSTM和RNN在处理memory cell里面的值的方式不一样。
RNN每次都吧新的值存到memory cell里面,旧的值被替换;
LSTM则用了input gate的计算结果与输入相乘后的值累加到memory cell里面。
重要思想RNN每次都替换旧的值,旧的值没有办法对最后的值有所影响,LSTM则采用累加策略,旧的值的还在memory cell里面,也就意味旧的值还持续影响最后输出。(The influence never disappears unless forget gate is closed.意味着:No Gradient vanishing, If forget gate is opened.)
早期的LSTM是没有forget gate的,就是要解决Gradient vanishing问题,现在的LSTM也有说法是要给forget gate比较大的bias确保forget gate打开。
GRU
Gated Recurrent Unit (GRU): simpler than LSTM
GRU([Cho, EMNLP’14])只有两个gate,参数量比较少。如果LSTM的overfitting比较严重,可以尝试使用GRU不详细讲,只给了大概思想,GRU中input gate和forget gate是联动关系,当input gate打开的时候,forget gate就会关闭,当input gate关闭的时候,forget gate就会打开,意思是只要新的值进来,就会把旧的值洗掉。
Gated Recurrent Unit (GRU)
还有其他几种解决方案,只有图和出处。
Clockwise RNN
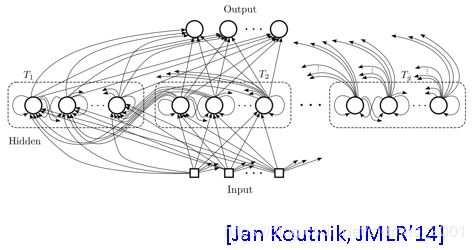
Structurally Constrained Recurrent Network (SCRN)

Fun Fact
hinton提出的:Vanilla RNN Initialized with Identity matrix + ReLU activation function [Quoc V. Le, arXiv’15]
和之前说的观点:ReLU在RNN上表现并不如sigmoid相悖。这里要注意hinton的前提是使用Identity matrix当做初始化。最后得到结果:Outperform or be comparable with LSTM in 4 different tasks
RNN其他应用
在之前的slot filling的例子里面RNN的input和output都是序列,且长度一样。这里再举一些别的实例。
Many to one
Input is a vector sequence, but output is only one vector
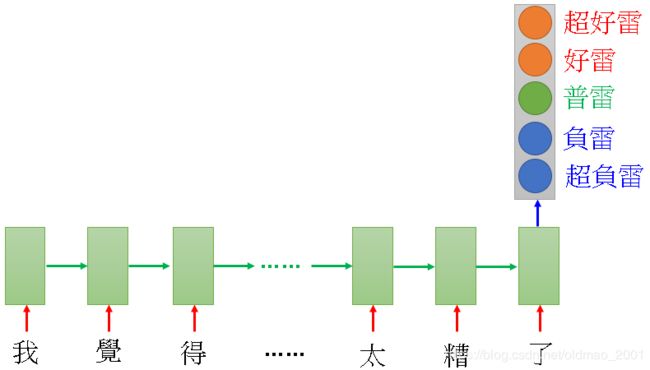
Sentiment Analysis
例如爬某个产品的评论,然后分类判断哪些评论是好的,哪些是坏的。

输入是character sequence,RNN把输入读一遍,在最后一个时间点,把hidden layer拿出来,再通过几个transform,得到最后的prediction
Key Term Extraction
输入是document的word sequence,然后通过embedding layer(上半部分),然后用RNN把结果读一次,把最后一个时间点的output拿出来(右上角的 O T O_T OT)做attention(这个玩意没有讲),做完attention后把重要的information抽出来,再丢入FNN得到最后的output。

Many to Many (output is shorter)
Both input and output are both sequences, but the output is shorter.
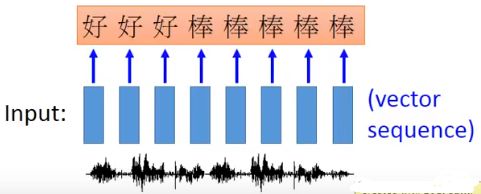
Speech Recognition
输入是一段acoustic sequence,如果用之前的slot filling方法来识别,就会输出如下信息。
可以做trimming

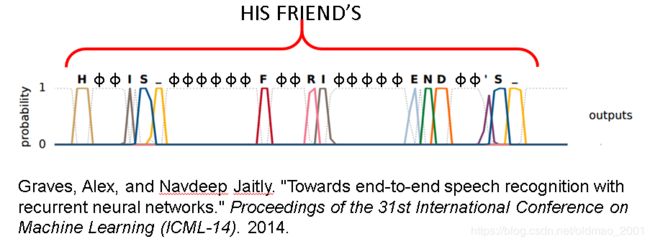
但是如果说的是三个字:好棒棒,(这里有个笑话没get到笑点。。。)解决这个问题可以用CTC
Connectionist Temporal Classification (CTC)
![]()
原理就是在输出中文之外还会输出φ代表null值

CTC训练:
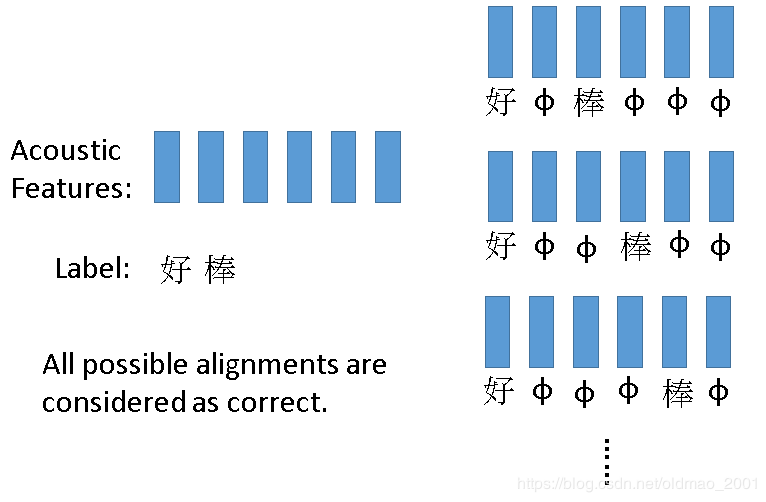
右边的穷举有专门的巧妙的算法,老师没有展开。论文实例:
Many to Many (No Limitation)
Both input and output are both sequences with different lengths. → Sequence to sequence learning
Machine Translation
输入英文word sequence输出中文word sequence,二者的长度不一样。例如:machine learning翻为:机器学习。
把输入machine learning用RNN读一遍,在最后一个时间点的memory里面就存了整个input sequence的information。

然后先输出第一个character:

然后把第一个character当做memory中的值(怎么把输出接到memory有很多技巧,挖个大坑),输出第二个character:
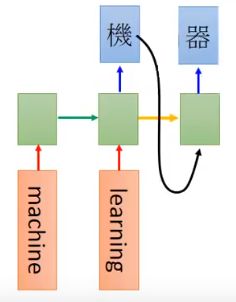
然后就不停往下走:

这样停不下来就好比在玩词语接龙:

停下来的方法就是有个标志,如上图中的“断”字。

在翻译上用这个方法已经达到了SOA的结果!但是在语音翻译上还差点火候(语音识别+翻译+文字输出)。
论文控给出了当时谷歌放出来的论文,意思是听英文,直接label为中文,然后train好后直接做语音翻译,结果还不错。

这个有是没用?例如台语翻英文,台语没有相应的文字做标签,根本不好做语音识别,现在可以直接用英文做标签,然后直接做语音翻译(不需要台语的文字就可以做台语转英语的翻译)。
Beyond Sequence
Syntactic parsing
语法校验,语法树可以转换为时序数据,就可以用RNN来处理

论文来源:Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, Geoffrey Hinton, Grammar as a Foreign Language, NIPS 2015
LSTM有很好的记忆,不会忘记加括号这个事。
Sequence-to-sequence Auto-encoder
Text处理
词袋的方式处理文本忽略了语序信息,会造成语义理解不准确的现象,例如:
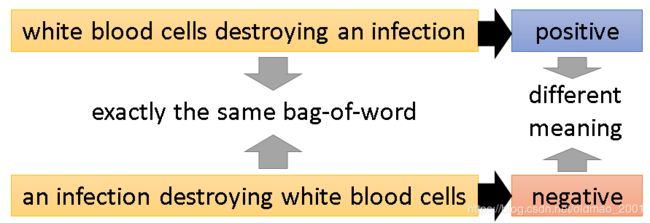
里面就加了编码和解码模块:

出处:Li, Jiwei, Minh-Thang Luong, and Dan Jurafsky. “A hierarchical neural autoencoder for paragraphs and documents.” arXiv preprint arXiv:1506.01057(2015).
整个结构还可以是层次结构:

出处:同上
Speech处理
把一段声音讯号变成Word vector
Dimension reduction for a sequence with variable length
audio segments (word-level) →→Fixed-length vector
会把发音相近的词放一起,例如:dog和dogs、never和ever的vector比较接近

出处:Yu-An Chung, Chao-Chung Wu, Chia-Hao Shen,
Hung-Yi Lee, Lin-Shan Lee, Audio Word2Vec: Unsupervised Learning of Audio Segment Representations using Sequence-to-sequence Autoencoder, Interspeech 2016
Speech处理的应用实例
应用场景:随便说一个词:“找朋友”,然后就在数据库中找到对应语音片段。
将语音存储在数据库中,然后把数据库做segmentation,然后用上面讲的Audio Segment to vector的技术把它们统统变成vector;
使用者讲一句话或词,然后把这个话或词变成vector,然后到数据库中计算它们的相似程度,最后得到结果。

把audio segment 变成vector的具体做法:

先把audio的segment抽成acoustic feature sequence,然后输入RNN,这个RNN相当于一个encoder,它在读完数据之后,它的最后一个时间点的memory的值就代表了整个audio segment,这个值是一个vector:

但是只有RNN Encoder是没有办法训练的,因此同时我们还要训练一个RNN的Decoder,其作用就是把之前Encoder存在memory的vector的值当做input,然后产生一个acoustic feature sequence, y 1 y_1 y1。然后再根据 y 1 y_1 y1产生 y 2 y_2 y2,依次下去。
训练的target就是希望 y 1 y_1 y1和 x 1 x_1 x1, y 2 y_2 y2和 x 2 x_2 x2.。。。越接近越好。
注意:Encoder和Decoder是一起训练的(joint)

实例结果分析
Visualizing embedding vectors of the words

可以看到,fear和near,fame和name两组词的word vector方向是一样的,原因是他们后边发音一样就是辅音不同,可以结合之前讲。
但是这个实例中没有考虑语义的信息
DEMO:Chat-bot圈霸
训练数据如图中所示,Encoder输入对话上句,Decoder对应下句。

Attention-based Model
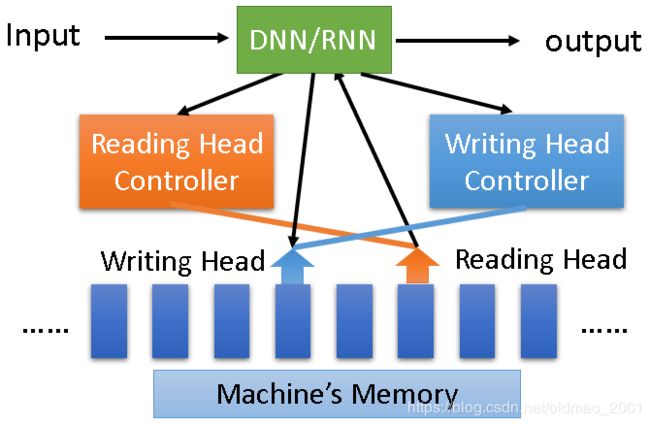
相当于RNN的进阶版本,先给出了人类脑袋可以记忆很多东西,从今天的早餐,到10年前的夏天,还可以根据记忆进行归纳整理知识。

机器也可以做类似的事情,大体结构如下图所示,输入经过DNN或RNN(相当于CPU),然后操控读写头,读取相应位置的数据(整个过程类似电脑读取硬盘),具体不展开,可以看这个:Attention-based Model李宏毅精讲

当然还可以写,相当于Attention-based Model 2.0,就是鼎鼎大名的:Neural Turing Machine(14年底左右提出)
Attention-based Model应用:阅读理解(Reading Comprehension)
读入一个document,把里面每一句话变成一个vector,这个vector代表了某句话的语义,然后提问,经过CPU,然后读取信息,这个过程可以在多处读取,最后输出答案。

Attention-based Model应用:看图说话(Visual Question Answering)
过程和上面类似
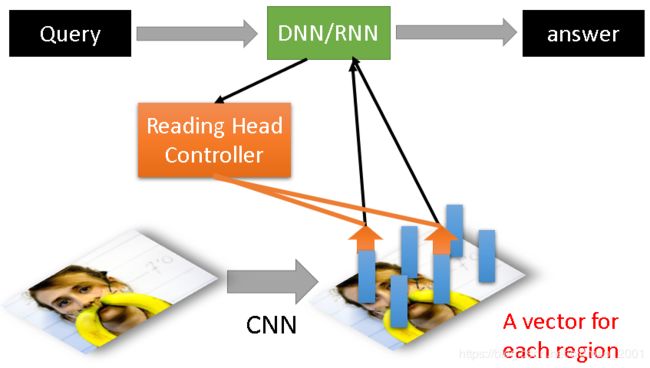
Attention-based Model应用:人机对话(Speech Question Answering)
典型的例子就是让计算机做听力测试

过程和上面例子差不多

但是我感觉有些听力没有这么简单,例如原文说一个人早上8点上班下午4点下班,提问是这个人work了多久。估计计算机就蒙了。
实验结果分析(略)
RNN v.s. Structured Learning
| RNN, LSTM | HMM, CRF, Structured Perceptron/SVM |
|---|---|
| Unidirectional RNN does not consider the whole sequence | Using Viterbi, so consider the whole sequence |
| Cost and error not always related | How about Bidirectional RNN? |
| Deep胜 | Can explicitly consider the label dependency胜 |
| 总体强 | Cost is the upper bound of error胜 |
整体来说DNN参数多,函数复杂,可拟合的模型涵盖范围大,因此整体比Structured Learning强,但是二者可以结合。
整合案例:Speech Recognition
CNN/LSTM/DNN + HMM

汗,这里跟不上了,先记下来。。。
整合案例:Semantic Tagging:
Bi-directional LSTM + CRF/Structured SVM
