李宏毅机器学习笔记——16. Conditional Generation by RNN&Attention(RNN条件生成与注意力机制)
摘要:本章内容是讲解了Generation,Attention,Tips for Generation,一是围绕用RNN实现Generation(生成)的方法与基本原理,先应用生成句子去介绍生成的基本原理,接着举例无条件的生成图片,其不同的是:将图片上的每个像素点看成一个word,并需要考虑各像素之间的几何关系,所以我们需要借助3D-LSTM完善了Generation图片功能。但是在实际应用中,我们的生成一般都是有Conditional Generation(条件生成)的,不然随机生成的没有实际意义。条件生成下,我们首先用一个CNN/RNN模型将输入的图片/句子转化为一个vector(Encoder编码器),之后用相同的外部条件的vector在每个时间点都输入另一个RNN(Decoder解码器)。
二是主要围绕 Attention注意力机制,如果外部条件很复杂且包含很多无用信息时,是很没效率的,然后引入了 Dynamic Conditional Generation(动态条件生成),计算出对应时间点最有效的信息接入,很大的提高了效率和准确率。
三是主要讲解了Tips for Generation(关于生成的技巧),首先说明attention是可以调节的,一个好的attention需要每个component(组成图片)有相近的attention权重,以及用正则项去解决。其次是关于 Mismatch between Train and Test,先提出问题,会有一个现象,Exposure Bias(曝光偏差),接着提出了Modifying Training Process,Scheduled Sampling(定时采样), Beam Search(集束搜索)去解决上述问题。
四是最后讲解了由于衡量结果好坏是根据句子不是词汇,所以我们要用优化目标级准则而不是组件级交叉熵,具体做法要用强化学习的思路去解。
文章目录
- 1. generation(生成)
-
- 1.1 生成句子
- 1.2 生成图片
- 2. Conditional Generation(条件生成)
-
- 2.1 插图说明
- 2.2 机器翻译
- 2.3 Chat—bot (智能对话)
- 3. Attention(注意力机制)
-
- 3.1 Dynamic Conditional Generation(动态条件生成)
- 3.2 Machine Translation(机器翻译实例)
- 3.3 Image Caption Generation(图片字幕生成)
- 3.4 Memory Network(在Memory上做attention)
-
- 3.4.1 具体做法
- 3.4.2 Memory network的复杂版本
- 4. Tips for Generation(关于生成的技巧)
-
- 4.1 Attention的正则化
- 4.2 Mismatch between Train and Test
-
- 4.2.1 question(问题)
- 4.2.2 solution(解决办法)
-
- 4.2.2.1. Modifying Training Process
- 4.2. 2.2 Scheduled Sampling
- 4.2.2.3 Beam Search(集束搜索)
- 4.3 Better idea?(输入的再讨论)
- 4.4 object level vs component level
- 5.总结与展望
1. generation(生成)
模型通过学习一些数据,然后生成类似的数据。我们可以生成一个句子,文章,图片,声音等。
1.1 生成句子
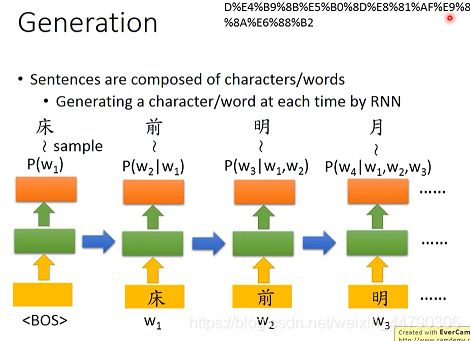
如上图中以生成句子为例:通过RNN生成一个句子
做法:我们将特殊字符BOS(begin of sentence)输入(BOS是经过机器训练得到的一个vector),在第一个RNN的输出中得到一个character distribution(词的概率分布),根据它我们sample出’床’字,将该输出作为下一个RNN的输入,以此类推,最后生成得到一篇诗(句子)。
但是在训练RNN模型的时候,并不是拿上一时刻的输出当作下一时刻的输入,而是拿真正的句子序列当作输入的。
1.2 生成图片
如果想生成一张图片,我们可以把图片的每个pixel像素看成一个character词,从而像组成一个sentence句子,比如下图中蓝色pixel就表示blue,红色的pixel表示red等,看成九个词,然后按照生成句子的原理,去生成一个图片即可。如下图:
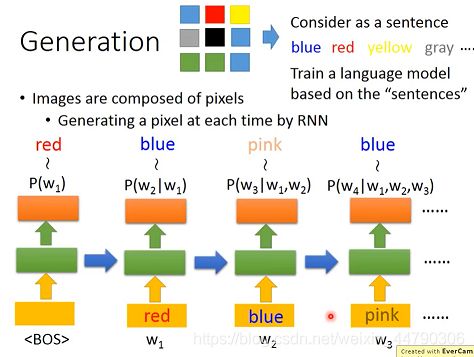
我们直接将每个像素转换成词,然后直接丢入语言模型中也会得到一个较好的结果。
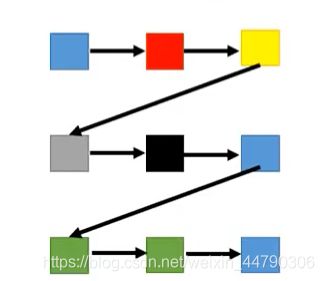
但是呢,上述生成图片的方法是只考虑的各个像素点的顺序关系(如下图),没考虑到各个像素点位置关系,这也会影响生成的图片。
另外一个比较理想的生成图像方法,需要考虑各个像素pixel之间的几何关系,如下图所示:
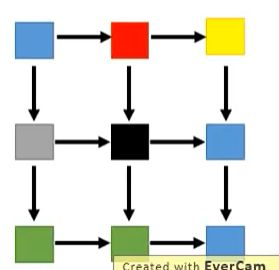
那么该怎样去做呢? 这里需要用到3D-LSTM来实现!(自己去复习一下LSTM)
首先从下图的左上角,该LSTM块输入了三组参数,也输出了三组参数,把这些方块叠起来就可以达到右侧位置图像的效果。

在生成3*3的图片时,根据周围的像素点得到要输出的像素点,采用的是2X2的卷积filter,去通过模型得到一个生成图片。
2. Conditional Generation(条件生成)
随机的生产句子和图片是没有意义的,如果仅仅是随机生成一些句子,是没有太大的实际作用,我们希望根据特定的情景来生成我们的句子,图片。比如插图说明,即根据图片去生产我们的描述;智能对话系统,根据问题来生成我们的答案;以及翻译系统,我们要根据给出的句子得到对应的翻译。

2.1 插图说明
如果要对一张图片进行解释,先将image输入一个已经训练好的CNN模型中,转化为一个vector(红色方框),再将该 image vector丢入上面用来Generation的RNN,在每一个RNN输出之前,都输入该image vector,不然RNN可能会忘记image的一些信息。如下图:
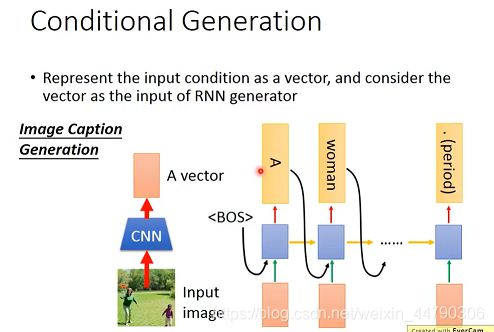
2.2 机器翻译
用RNN来做机器翻译:
- 首先将输入的句子转化成一个vector,具体做法是将各个词分别输入一个RNN中,最后一个时间节点的输出(红色方框)就包含了整个sentence的information,这个过程称之为Encoder(编码器)。
- 再把encoder编码器的information(vector),再作为另外一个RNN的input,再进行output(重复上面RNN生成的步骤),这个过程称之为Decoder(解码器)。
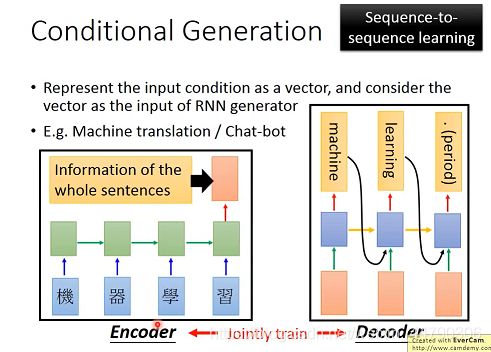
注意:这两个RNN可以是一样的,也可以是不一样的,(即encoder和decoder是jointly train联合训练的,这两者的参数可以是一样的,也可以是不一样的),这个方法就是sequence-to-sequence learning。
2.3 Chat—bot (智能对话)
上述同样的方法也可以实现Chat-bot,但是对话时machine是需要考虑上下文情景对话,所以需要用到多层Encoder。将之前所说过的话都通过RNN转化为一个个vector,然后又通过第二层RNN全部考虑之前的对话,将结果再丢给Decoder(解码器)。如下图:
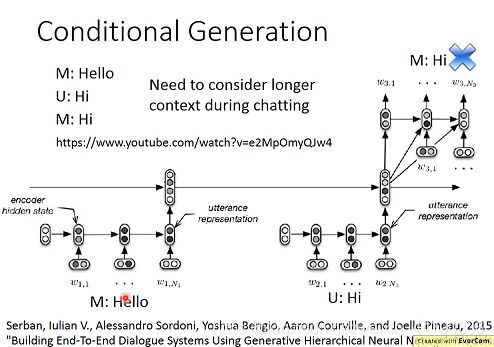
3. Attention(注意力机制)
3.1 Dynamic Conditional Generation(动态条件生成)
在之前的生成过程中,我们都是将整个句子得到的信息Encoder(编码器),每次都将全部信息输入Decoder(解码器)。这样做的话,如果当整个句子太复杂,无法用一个vector表示,即使可以表示也无法包含全部信息,如果decoder每次input的都还是同一个vector,则会产生不好的结果。
在注意力机制中,我们将每个时间点输入不同的信息c(vector),它将是一个动态变化的,这样做的好处是避免无法将整个句子信息表示成vector,也会使我们的结果更加高效与准确。
3.2 Machine Translation(机器翻译实例)
首先将 ”机器学习“ 每个字的vector作为输入,接下来有一个初始的vector z0,根据z0、h1通过match函数得到α01(0代表时间点0,1代表输入的是h1)。
这个match函数可以是自己设计的,常见的有下图右侧三种情况:
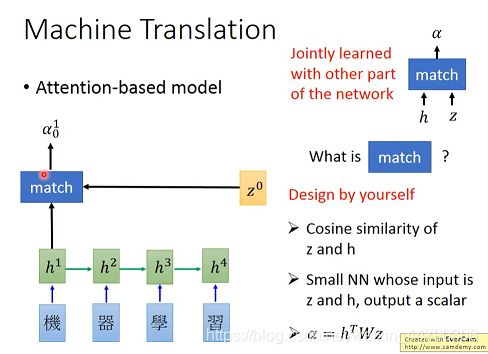
之后将得到α做softmax处理(这一步不是必要的),然后用求到的α(利用下图公式)计算c0。再将c0作为decoder的输入,得到z1,是RNN中间层的输出。(下图例子中的数据表示c0中只包含“机器”的信息,也就是h1和h2)

接着后面是在重复之前的操作,将z1与每个h做match函数处,并做softmax函数处理得新的α,之后求c1再输入给decoder中,然后中间层输出z2。如下图: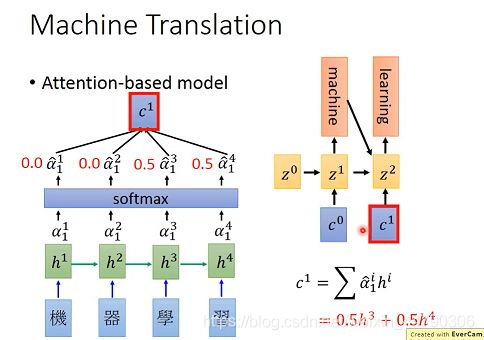
上述过程不断重复,直到句子结束为止!
3.3 Image Caption Generation(图片字幕生成)
先将image可以分成多个region,然后找一组filter对图片进行卷积,得到一组vector。之后就是重复上述翻译例子的过程,即可得到结果。
3.4 Memory Network(在Memory上做attention)
应用在做阅读理解上,给机器一篇文章,根据具体提问,机器将会给出一个正确的答案。
3.4.1 具体做法
文章可以分为N个句子,每个句子可以表示为一个向量: x 1 , x 2 , x 3 , . . . , x N x^1,x^2,x^3,...,x^N x1,x2,x3,...,xN;
问题可以表示成一个vector: q q q;
之后再将q与每个句子的vector做match函数处理,得到 α 1 , α 2 , α 3 , . . . , α N α^1,α^2,α^3,...,α^N α1,α2,α3,...,αN;
接着将match score与每个向量做加权和处理,得到一个信息vector ,将得到的信息vector与Query问题一起输入DNN中,得到问题答案。(如下图)
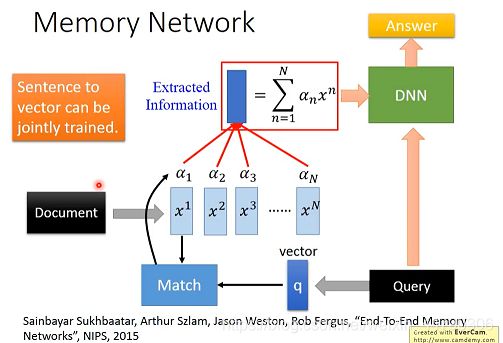
注意:Sentence to vector can be jointly trained.(句子转化为向量的NN可以与其他的NN联合训练)
3.4.2 Memory network的复杂版本
将文章中的句子分成两组不同的vector(x和h),用x这组vector计算attention,但是用h表示每个句子的信息,就是将计算match score和抽取句向量两部分分开。如下图:
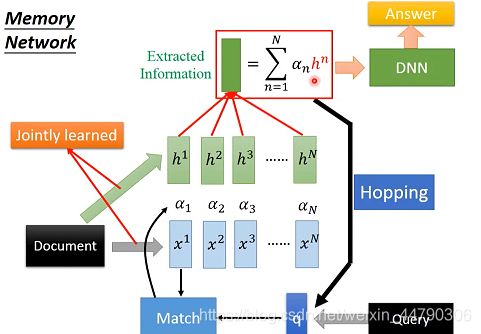
之后将得到的vector,直接丢入DNN就可以得到问题答案;然而我们也可以把这个vector ,丢给q向量(将vector与q相加),得到一个新的q;接着又重复上面的操作。即这件事叫做Hopping,就意味着机器在反复的思考答案是否正确。
4. Tips for Generation(关于生成的技巧)
4.1 Attention的正则化
α下表代表次序,上标代表专注的图片。
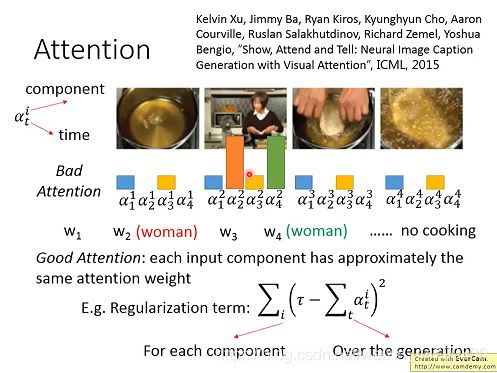
其实attention是可以调节的,因为有时会出现一些bad attention,在产生第二个word(woman)时,focus到第二个component,在产生第四个word时,也focus到第二个component上,也是woman,多次attent在同一个frame上,就会产生一些很奇怪的结果。
如上图中,一个好的attention:要求每个component(组成图片)有相近的attention权重(即至少要包含input的每一个frame,每个frame都应该attention一下,每个frame进行attention的量也不能太多,这个量最好是同等级的)。
那要怎么做呢?
例如,用正则化去处理: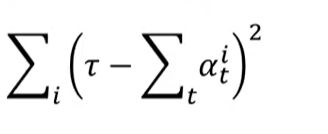
可以通过这个正则项,使每个图片中∑α与τ的差的平方尽可能变小,达到每一个component的attention weight就会相近一些。
4.2 Mismatch between Train and Test
4.2.1 question(问题)
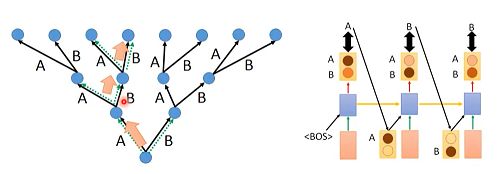
在训练阶段: 我们在生成第一个A的时候考虑的是初始标签和条件(粉色块),输出第二个B的时候,考虑的是之前的标签A和条件,输出第三个B的时候,考虑的是之前的标签B和条件,整个模型要使得所有生成结果与标签之间的交叉熵的差异越小越好。如下图:

在生成阶段:我们不知道具体的标签,所以我们只能把RNN生成的结果接过来。在生成结果的时候应该是生成一个分布,然后从这个分布里面进行sample得到生成结果。

训练时,输入是reference标签,而测试时,输入是上一个时间点的输出结果,这样的现象叫做:Exposure Bias(曝光偏差)。
这两个setting不一致会导致误差累积(error accumulate)。误差累积是因为,你在测试的时候,如果前面单元的输出已经是错的,那么你把这个错的输出作为下一单元的输入,那么理所当然就是“一错再错”,造成错误的累积。
下面看一个正常的训练过程:
这里如果训练出错:

上图训练中将第一个A,错误的选成B。对训练阶段来说,只是错了一小部分。但是在测试(生成)时,如果将A错选成B,那么根据错误的结果继续走下去,整个答案就全都错了(一步错步步错)。如下图案例:
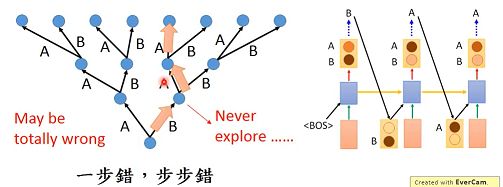
4.2.2 solution(解决办法)
针对上面的这种问题,我们也有如下几种解决方案:
4.2.2.1. Modifying Training Process
那么我们如何解决这种mismatch问题呢?可以尝试modify训练process。 在训练时,如果输出的结果与reference不一样,也要把输出的结果传给下一个时间点的输入,这样training和test就会是match的。但是这样在实际操作中是train不起来的。
在训练时,如果输出的结果与reference不一样,也要把输出的结果传给下一个时间点的输入,这样training和test就会是match的。但是这样在实际操作中是train不起来的。
4.2. 2.2 Scheduled Sampling
由于使用Modifying Training Process很难train,现在我们就使用Scheduled Sampling(定时采样)。
在上述两种方案中,最大的区别在于训练过程中,下一个时间点的输入是取reference还是取上一个时间点的输出 ?

在Scheduled Sampling(定时采样)的方案中,我们综合考虑上述两个方案的方法,将这个问题可以给一个几率,如果铜板是正面,就使用model的output,如果是反面,就用reference作为训练的输入。
下图中,纵轴表示from reference的几率,一开始只看reference,reference的几率不断变小,model的几率不断增加!

并且有数据表明,scheduled sampling的效果是比只看reference和只看model的效果要更好的!
4.2.2.3 Beam Search(集束搜索)
贪心搜索:直接选择每个输出的最大概率
暴力搜索:枚举当前所有出现的情况,从而得到需要的情况
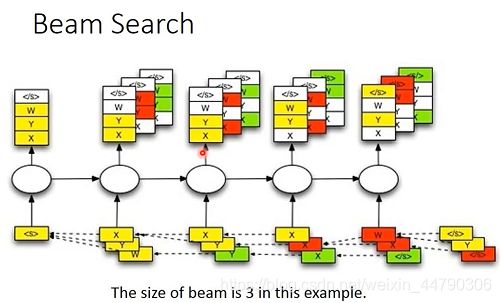
beam search是一个介于greedy search(贪心搜索)和暴力搜索之间的方法。第一个时间点都看,然后保留分数最高的两个,一直保留两个。
beam search:在搜索的时候,设置beam size=2,就是每一次保留分数最高的两条路径,走到最后的时候,哪一条分数最高,就输出哪一条。如下图:

下面是Beam size=3的例子,注意颜色对应,保留最好的三个,假设一个句子丢进去只有三个单词和一个表示句末的符号(共4个),输出分数最高的三个X,Y,W,再分别将三个丢进去,比如将X丢进去得到X,Y。。。将Y丢进去得到W,Y。。。将W丢进去得到。。。这样就得到三组不同的distribution(一共4*3条路径),选出分数最高的三条放入…直到最后。如下图:
4.3 Better idea?(输入的再讨论)
上面讨论的是用模型训练的结果或者标签作为下一个预测的输入。能不能直接用得到的分布作为输入?
如下图所示:(左侧是将结果做为输入,右侧是将分布做为输入)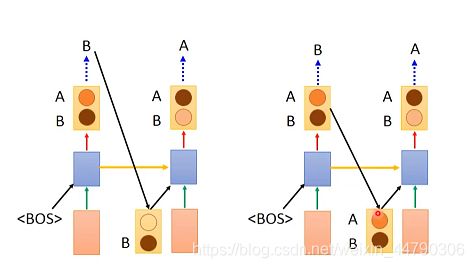
结论:将分布直接传给下一个时间点并不好。
问题:你觉得如何? 机器应该回答:高兴想笑或者难过想哭
在下图中左边的方案中,第一个时间点 A代表难过,B代表高兴,它们的概率可能是很接近的。输出A或B都可以,这里选择输出B。将B输入给下一个时间点,“高兴”后面接着“想笑”的概率很大(比“想哭”大),这时候输出就是想笑。
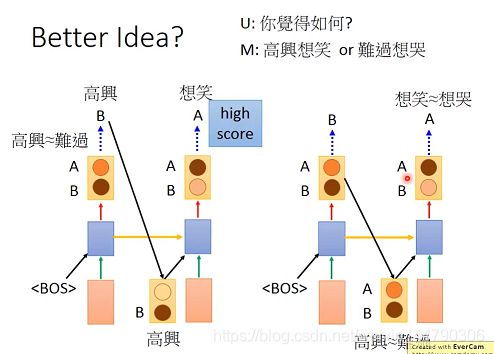
然而右侧方案中,由于传给第二个时间的的是概率分布,而且两个概率是近似的,这时候第二个时间的输出,想笑和想哭的概率也是近似的,得到的可能就是“高兴想哭”,“难过想笑”,句子杂糅了。
4.4 object level vs component level
Component level 是从每个单词是否接近图片目标词汇中的内容,来评价训练的结果好坏。从下图中可以看出the dog is is fast 的cross-entropy本身就比较小了,但是它的结果表现并不好,训练出来的并不是一个句子,不符合语法。

因为衡量好坏是根据句子不是词汇,所以我们要用Optimize object-level criterion instead of component-level cross-entropy(优化目标级准则而不是组件级交叉熵)。如下图:

用整体的效果来衡量损失。object-level criterion: R ( y , y ^ ) R(y,\hat{y}) R(y,y^),
其中: y y y: generated utterance, y y y^: ground truth
上述R是衡量两个句子之间的差异,但是不可以做gradient descent,而cross entropy是可以gradient descent的。
但是可以转换思路,用强化学习的思路来解决这个问题:(这里没有理解透彻,强化学习是怎么样的?)

前面的r都是0,只有最后一个参数通过调整得到一个reward,把生成的句子和最后的标签做比较,生成reward,然后目标是最大这个reward。
5.总结与展望
本章主要是讲解了不同情况下的生成,与生成的基本原理与方法,以及过程中会产生的一系列问题,与解决方案等。总体来讲信息量较大,从实际举例与论文的结果去展开介绍,其中特别需要注意的有,Generation图片时用3D-LSTM可以考虑到各个像素点的几何位置,结果更准确;在做机器翻译、Image Caption Generation等时当外部条件输入很复杂如翻译大段文字时,Dynamic Conditional Generation可以有效的提高效率;在生成中的问题现象,Exposure Bias(曝光偏差),可以使用Scheduled Sampling和Beam Search等方法来解决,Scheduled Sampling就是train到后面,不用reference用model来train,可以防止出现没有的数据集。最后需要对强化学习有详细了解,并结合传统方法去解决生成过程中的问题。