Istio服务网格实践指南 学习笔记(一) 服务网格介绍
个人学习Istio系列 学习笔记 服务网格介绍篇
原书网址 https://jimmysong.io/istio-handbook/ 本篇仅为个人学习笔记
Istio是由 Google、IBM、Lyft 等共同开源的 Service Mesh(服务网格)框架,Kubernetes 解决了云原生应用的部署问题,Istio 解决是应用的服务(流量)治理问题。
什么是服务网格?
Service mesh 又译作 “服务网格”,作为服务间通信的基础设施层。
服务网格是用于处理服务间通信的专用基础设施层。它负责通过包含现代云原生应用程序的复杂服务拓扑来可靠地传递请求。实际上,服务网格通常通过一组轻量级网络代理来实现,这些代理与应用程序代码一起部署,而不需要感知应用程序本身。
服务网格(Service Mesh)这个术语通常用于描述构成这些应用程序的微服务网络以及应用之间的交互。随着规模和复杂性的增长,服务网格越来越难以理解和管理。它的需求包括服务发现、负载均衡、故障恢复、指标收集和监控以及通常更加复杂的运维需求,例如 A/B 测试、金丝雀发布、限流、访问控制和端到端认证等。
服务网格的特点
1.应用程序间通讯的中间层
2.轻量级网络代理
3.应用程序无感知
4.解耦应用程序的重试/超时、监控、追踪和服务发现
理解服务网格
如果用一句话来解释什么是服务网格,可以将它比作是应用程序或者说微服务间的 TCP/IP,负责服务之间的网络调用、限流、熔断和监控。对于编写应用程序来说一般无须关心 TCP/IP 这一层(比如通过 HTTP 协议的 RESTful 应用),同样使用服务网格也就无须关心服务之间的那些原来是通过应用程序或者其他框架实现的事情,比如 Spring Cloud、OSS,现在只要交给服务网格就可以了。
服务网格的来龙去脉:
1.从最原始的主机之间直接使用网线相连
2.网络层的出现
3.集成到应用程序内部的控制流
4.分解到应用程序外部的控制流
5.应用程序的中集成服务发现和断路器
6.出现了专门用于服务发现和断路器的软件包/库,如 Twitter 的 Finagle 和 Facebook 的 Proxygen,这时候还是集成在应用程序内部
7.出现了专门用于服务发现和断路器的开源软件,如 Netflix OSS、Airbnb 的 synapse 和 nerve
8.最后作为微服务的中间层服务网格出现
服务网格的架构如下图所示:

服务网格如何工作?
下面以 Istio 为例讲解服务网格如何在 Kubernetes 中工作。
1.Istio 将服务请求路由到目的地址,根据中的参数判断是到生产环境、测试环境还是 staging 环境中的服务(服务可能同时部署在这三个环境中),是路由到本地环境还是公有云环境?所有的这些路由信息可以动态配置,可以是全局配置也可以为某些服务单独配置。
2.当 Istio 确认了目的地址后,将流量发送到相应服务发现端点,在 Kubernetes 中是 service,然后 service 会将服务转发给后端的实例。
3.Istio 根据它观测到最近请求的延迟时间,选择出所有应用程序的实例中响应最快的实例。
4.Istio 将请求发送给该实例,同时记录响应类型和延迟数据。
5.如果该实例挂了、不响应了或者进程不工作了,Istio 将把请求发送到其他实例上重试。
6.如果该实例持续返回 error,Istio 会将该实例从负载均衡池中移除,稍后再周期性得重试。
7.如果请求的截止时间已过,Istio 主动失败该请求,而不是再次尝试添加负载。
8.Istio 以 metric 和分布式追踪的形式捕获上述行为的各个方面,这些追踪信息将发送到集中 metric 系统。
服务网格架构
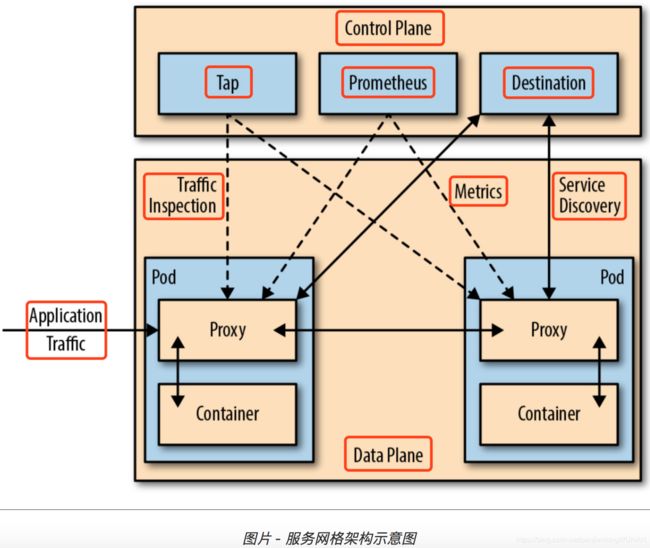
服务网格中分为控制平面和数据平面,Istio控制平面中包括 Mixer、Pilot、Citadel,数据平面默认是用Envoy.
控制平面
控制平面的特点:
1.不直接解析数据包
2.与控制平面中的代理通信,下发策略和配置
3.负责网络行为的可视化
4.通常提供API或者命令行工具可用于配置版本化管理,便于持续集成和部署
数据平面
数据平面的特点:
1.通常是按照无状态目标设计的,但实际上为了提高流量转发性能,需要缓存一些数据,因此无状态也是有争议的
2.直接处理入站和出站数据包,转发、路由、健康检查、负载均衡、认证、鉴权、产生监控数据等
3.对应用来说透明,即可以做到无感知部署
服务网格的实现模式
下图是使用Service Mesh架构的最终形式
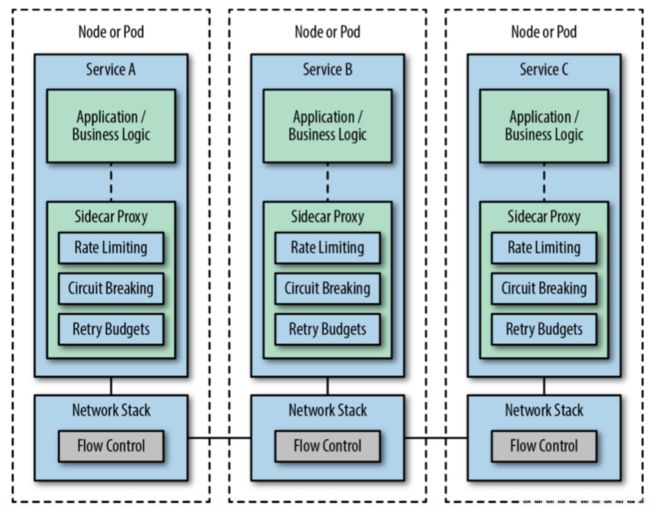
当然在达到这一最终形态之前我们需要将架构一步步演进,下面给出的是参考的演进路线。
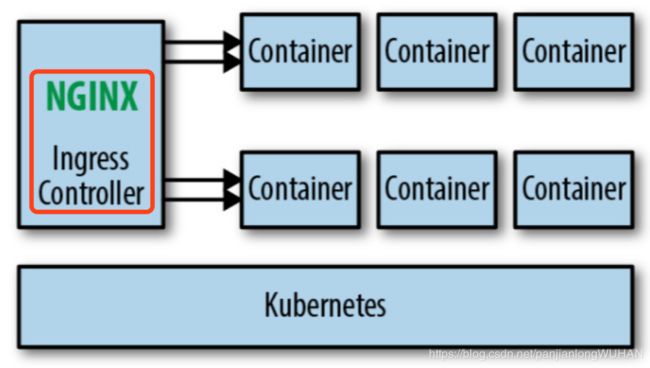
Ingress
如果你使用的是Kubernetes做容器编排调度,那么在进化到Service Mesh架构之前,通常会使用Ingress Controller,做集群内外流量的反向代理,如使用Traefik或Nginx Ingress Controller。
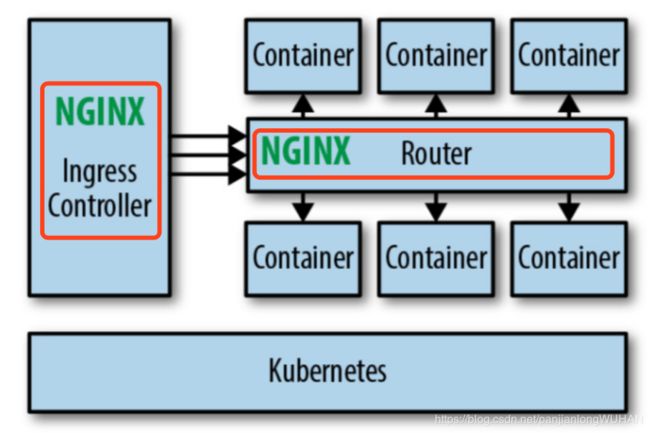
路由器网格
Ingress或者边缘代理可以处理进出集群的流量,为了应对集群内的服务间流量管理,我们可以在集群内加一个Router层,即路由器层,让集群内所有服务间的流量都通过该路由器。这个架构无需对原有的单体应用和新的微服务应用做什么改造,可以很轻易的迁移进来,但是当服务多了管理起来就很麻烦。
Proxy per Node
这种架构是在每个节点上都部署一个代理,如果使用Kubernetes来部署的话就是使用DaemonSet对象,Linkerd第一代就是使用这种方式部署的。
这种架构有个好处是每个节点只需要部署一个代理即可,比起在每个应用中都注入一个sidecar的方式更节省资源,而且更适合基于物理机/虚拟机的大型单体应用,但是也有一些副作用,比如粒度还是不够细,如果一个节点出问题,该节点上的所有服务就都会无法访问,对于服务来说不是完全透明的。
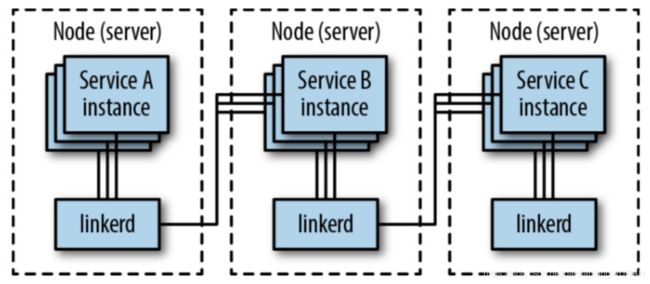
Sidecar代理/Fabric模型
这个一般不会成为典型部署类型,当企业的服务网格架构演进到这一步时通常只会持续很短时间,然后就会增加控制平面。跟前几个阶段最大的不同就是,应用程序和代理被放在了同一个部署单元里,可以对应用程序的流量做更细粒度的控制。
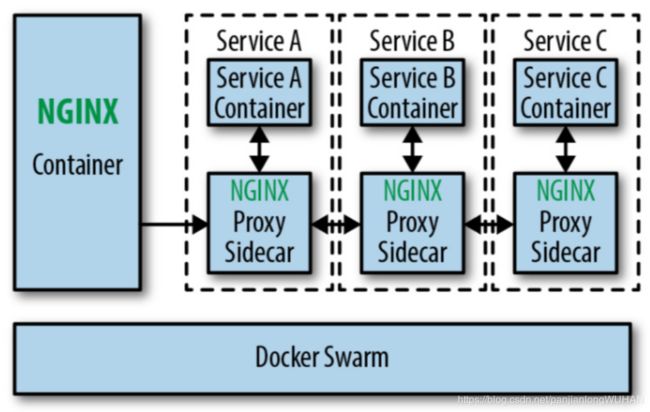
Sidecar代理/控制平面
下面的示意图是目前大多数Service Mesh的架构图,也可以说是整个Service Mesh架构演进的最终形态。
这种架构将代理作为整个服务网格中的一部分,使用Kubernetes部署的话,可以通过以sidecar的形式注入,减轻了部署的负担,可以对每个服务的做细粒度权限与流量控制。但有一点不好就是为每个服务都注入一个代理会占用很多资源,因此要想方设法降低每个代理的资源消耗。
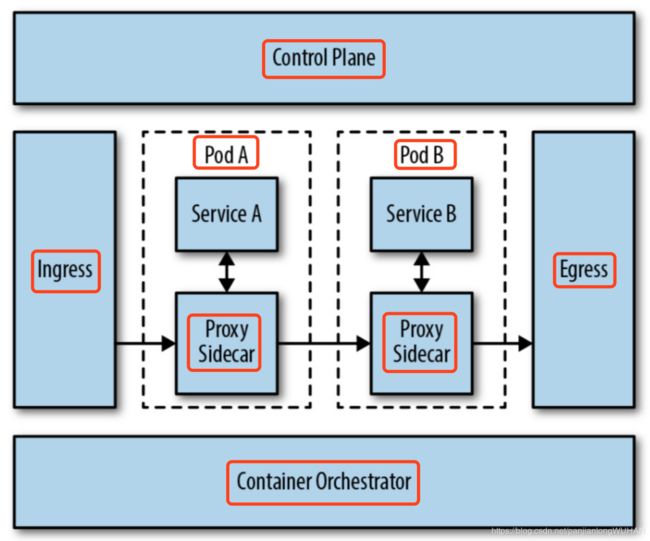
多集群部署和扩展
所有的服务都位于同一个集群中,服务网格管理进出集群和集群内部的流量,当我们需要管理多个集群或者是引入外部的服务时就需要网格扩展和多集群配置。