进阶的爬虫系列 ——不得不说的贴吧爬取术
进阶的爬虫系列
——不得不说的贴吧爬取术
感谢各位能点开我的这篇博文,才开始写,这个算是很简单的爬虫,文中如有错误和不足欢迎各位大神多多包涵指正,大家的建议是我不断前行的动力,废话不多说我们直接进入主题。
目标:爬取贴吧数据
步骤:
首先我们进入百度贴吧的页面,通过进入不同的贴吧以及翻页解析其url的变化规律
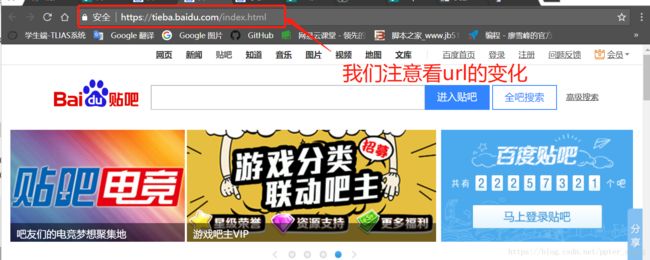
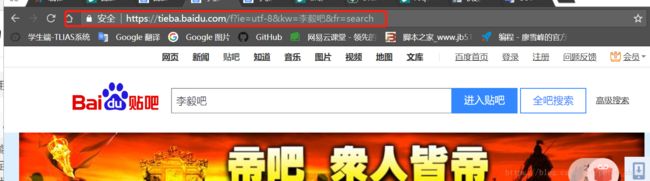
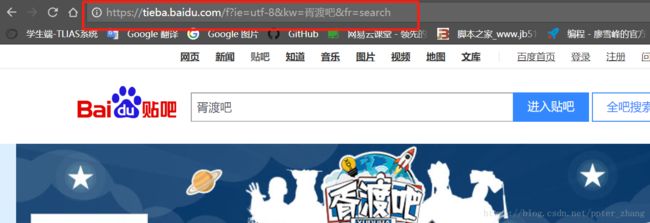
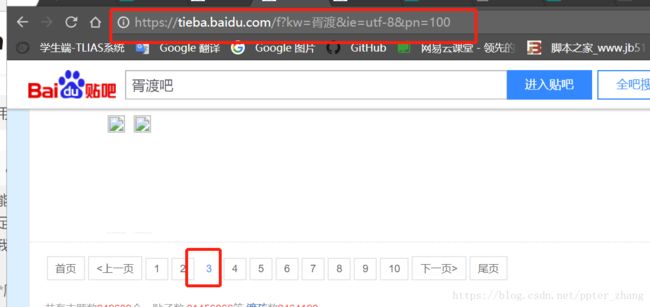
通过观察我们可以看出 “kw=”的后面是接的贴吧的名字,而“pn=”的后面是接的页数,从0开始,每翻一页pn对应的数值会加50。发现规律以后我们就可以通过url中贴吧名字及页数这两个点用循环遍历爬取页面数据。
然后我们明确业务逻辑:
定义一个类——>初始化——>构造url列表——>遍历,发送请求,获取响应——>保存
根据业务逻辑构建初始代码如下:
# coding=utf-8
class Tieba:
def __init__(self,tieba_name):
self.url_temp ="https://tieba.baidu.com/f?kw=" + tieba_name + "&ie=utf-8&pn={}"
self.headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
}
def get_url_list(self):
# 构造url列表
pass
def parse_url(self,url):
# 发送请求,获取响应
pass
def save_html(self,html_str,page_num):
# 保存html字符串
pass
def run(self):#实现主要逻辑
#1.构造url列表
#2.遍历,发送请求,获取响应
#3.保存
pass
if __name__ == '__main__':
tieba = Tieba('李毅')
tieba.run()1.初始化url路径,和请求头
def __init__(self,tieba_name):
self.tieba_name = tieba_name
self.url_temp ="https://tieba.baidu.com/f?kw=" + tieba_name + "&ie=utf-8&pn={}"
self.headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
}2.构造url列表
def get_url_list(self):
# 构造url列表
return [self.url_temp.format(i*50)for i in range(100)]这边是以列表的方式将遍历出来的100页的url的路径保存,通过调用get_url_list这个方法使用
3.发送请求,获取响应
def parse_url(self,url):
# 发送请求,获取响应
print(url)
response = requests.get(url,headers = self.headers)
return response.content.decode()4.将爬取的页面以吧名+第几页命名,并保存,保存的时候一定要加encoding=’utf-8’,不然会因为编码问题报错
def save_html(self,html_str,page_num):
file_path = "{}-第{}页.html".format(self.tieba_name,page_num)
with open(file_path,"w",encoding='utf-8') as f:
f.write(html_str)5 将定义的方法根据业务逻辑,开始调用
def run(self):#实现主要逻辑
#1.构造url列表
url_list = self.get_url_list()
#2.遍历,发送请求,获取响应
for url in url_list:
html_str = self.parse_url(url)
#3.保存
page_num = url_list.index(url) + 1 #页码数
self.save_html(html_str,page_num)6.运行,这里传的是李毅吧,大家也可以传入其他吧名,都可以爬取
if __name__ == '__main__':
tieba = Tieba('李毅')
tieba.run()