nl2sql_baseline项目解读(待完成)
1.目的
该项目是将自然语言处理转化为mysql语句。
链接:https://github.com/ZhuiyiTechnology/nl2sql_baseline
首届中文NL2SQL挑战赛:https://tianchi.aliyun.com/competition/entrance/231716/introduction?spm=5176.12281949.1003.8.6f802448KX0Rys
2.方法
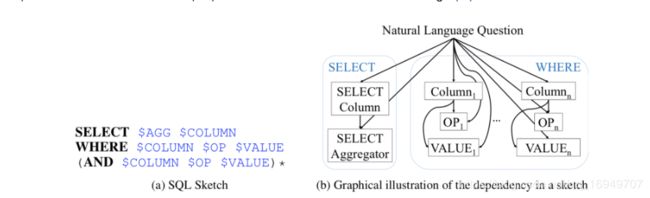
其实也很简单
就是 :
select $agg{0:"", 1:“AVG”, 2:“MAX”, 3:“MIN”, 4:“COUNT”, 5:“SUM”}
$column
where
$column $op{0:">", 1:"<", 2:"", 3:"!="}
conn_sql_dict{0:"", 1:“and”, 2:“or”}
$column $op{0:">", 1:"<", 2:"", 3:"!="}
…
可以将其拆解为4个子项目:
- 1 判定sel_agg,选的是啥
- 2 判定column,该项目又可以分为列个数sel_num和列值sel_pred
- 3 判定cond_pred,也就是where后面条件语句的词。
- 4 判定where_rela_pred,也就是where后面条件的组合关系,and或者or
baseline项目的结果为:
![]()
可以看出,其他效果都比较好了,就是要解决W-Col,where的列,W-Op where后面的op,W-Val where后面的值。
3. 查看一下难点的实现方法
拆解为四个部分
- 条件个数cond_num_score,这个目前效果还可以
- 条件列cond_col_score,这个效果垃圾
- 条件op:cond_op_score这个0.88
- 条件值?cond_str_score这个更垃圾
todo:具体实现log
3.1 有的数据
- 输入
输入文本
输入列columns
- 输出
cond_num_score:个数
cond_col_score:列选择
cond_op_score:操作
cond_str_score:值
其实就是将输入文本embedding,columns的embedding,然后得到输出的各项分数。
3.2 发现有问题
baseline居然没有用列名的embedding?其他求解都用到了,这是啥原因?这个是不是导致精度不高的原因呢?
- col_inp_var: embedding of each header
看看论文:https://arxiv.org/pdf/1711.04436.pdf
3.2.1 论文中预测where后面的个数、列、value、op的方法:
具体实现如下:
- 已经预测出列了,需要决定哪些列是属于where里面的,因为有些列是属于select 后面的列的
- 设置一个网络去取topk个columns,对每个查询项目,优化这个k
- OP slot是一个三分类的问题=,>,<
- VALUE slot是利用一个sequence-to-sequence直接取预测sub-string。
3.2.2 gen_query,根据预测的score生成mysql语句的方法来看具体实现
- 总体:
score拆分:
sel_num_score, sel_score, agg_score, cond_score, where_rela_score = score
B为batchsize - 根据sel_num来选定select后面columns的列和agg
sel_num = np.argmax(sel_num_score[b])
max_col_idxes = np.argsort(-sel_score[b])[:sel_num]
# find the most-probable columns' indexes
max_agg_idxes = np.argsort(-agg_score[b])[:sel_num]
cur_query['sel'].extend([int(i) for i in max_col_idxes])
cur_query['agg'].extend([i[0] for i in max_agg_idxes])
- where_rela_score自力更生
cur_query['cond_conn_op'] = np.argmax(where_rela_score[b])
- cond也就是where后面的数量num,列col,op,value其实也是自力更生。
# 拆分 cond_num_score,cond_col_score,cond_op_score,cond_str_score =\
[x.data.cpu().numpy() for x in cond_score]
# 选择num
cond_num = np.argmax(cond_num_score[b])
# 总体
cond_num = np.argmax(cond_num_score[b])
all_toks = ['' ] + q[b] + ['' ]
max_idxes = np.argsort(-cond_col_score[b])[:cond_num]
for idx in range(cond_num):
cur_cond = []
cur_cond.append(max_idxes[idx]) # where-col
cur_cond.append(np.argmax(cond_op_score[b][idx])) # where-op
cur_cond_str_toks = []
for str_score in cond_str_score[b][idx]:
str_tok = np.argmax(str_score[:len(all_toks)])
str_val = all_toks[str_tok]
if str_val == '' :
break
cur_cond_str_toks.append(str_val)
cur_cond.append(merge_tokens(cur_cond_str_toks, raw_q[b]))
cur_query['conds'].append(cur_cond)
4 预测where后面的个数、列、value、op具体实现
4.1 Predict the number of conditions预测条件的个数
总体思路是将列名和输入语句embedding然后得到预测个数,但是有几点需要注意:
- 输入的时候,假设一个batch为64,由于每一个表的列的个数不一致,每一列的列名的字符串的长度也不一致,他这里现将各个表的列名拼凑成一个整体,然后用lstm算一个embedding,再转化为bacth,max(col_len),feature_size,大小的特征作为输出。
- 列名最后只是作为一个隐藏层的特征,去算一个输入问题的att的隐藏层的特征,最后的输出是结合这个att联合句子的embedding来输出的。
- 输出为(64,5)是啥原因?这个估计得看下输入数据的构造情况了。

下面是输入输出纬度的debug的展示:
col_inp_var.shape
torch.Size([599, 16, 300])
p col_name_len.shape
(599,)
p col_len.shape
(64,)
self.cond_num_name_enc
LSTM(300, 50, num_layers=2, batch_first=True, dropout=0.3, bidirectional=True)
e_num_col.shape
torch.Size([64, 17, 100])
p col_num.shape
(64,)
p self.cond_num_col_att
Linear(in_features=100, out_features=1, bias=True)
p num_col_att_val.shape
torch.Size([64, 17])
p num_col_att.shape
torch.Size([64, 17])
p num_col_att.unsqueeze(2).shape
torch.Size([64, 17, 1])
(e_num_col * num_col_att.unsqueeze(2)).shape
torch.Size([64, 17, 100])
(e_num_col * num_col_att.unsqueeze(2)).sum(1).shape
torch.Size([64, 100])
p K_num_col.shape
torch.Size([64, 100])
p cond_num_h1.shape
torch.Size([4, 64, 50])
p cond_num_h2.shape
torch.Size([4, 64, 50])
p self.cond_num_lstm
LSTM(300, 50, num_layers=2, batch_first=True, dropout=0.3, bidirectional=True)
p h_num_enc.shape
torch.Size([64, 57, 100])
p self.cond_num_att
Linear(in_features=100, out_features=1, bias=True)
p self.cond_num_att(h_num_enc).shape
torch.Size([64, 57, 1])
p self.cond_num_att(h_num_enc).squeeze().shape
torch.Size([64, 57])
p num_att_val.shape
torch.Size([64, 57])
p num_att.shape
torch.Size([64, 57])
p num_att.unsqueeze(2).shape
torch.Size([64, 57, 1])
p h_num_enc.shape
torch.Size([64, 57, 100])
p num_att.unsqueeze(2).expand_as(h_num_enc).shape
torch.Size([64, 57, 100])
p (h_num_enc * num_att.unsqueeze(2).expand_as(h_num_enc)).shape
torch.Size([64, 57, 100])
p (h_num_enc * num_att.unsqueeze(2).expand_as(h_num_enc)).sum(1).shape
torch.Size([64, 100])
p K_cond_num.shape
torch.Size([64, 100])
p self.cond_num_col2hid1
Linear(in_features=100, out_features=200, bias=True)
p self.cond_num_col2hid1(K_num_col).shape
torch.Size([64, 200])
p self.cond_num_col2hid1(K_num_col).view(B, 4, self.N_h/2).shape
torch.Size([64, 4, 50])
p self.cond_num_col2hid1(K_num_col).view(B, 4, self.N_h/2).transpose(0, 1).shape
torch.Size([4, 64, 50])
p self.cond_num_col2hid1(K_num_col).view(B, 4, self.N_h/2).transpose(0, 1).contiguous().shape
torch.Size([4, 64, 50])
p self.cond_num_out
Sequential(
(0): Linear(in_features=100, out_features=100, bias=True)
(1): Tanh()
(2): Linear(in_features=100, out_features=5, bias=True)
)
p cond_num_score.shape
torch.Size([64, 5])
4.2 Predict the columns of conditions预测列
与上面类似
5 数据加载处理
-
q_seq:
: [[‘沪’, ‘宁’, ‘高’, ‘速’, ‘公’, ‘路’, ‘每’, ‘天’, ‘的’, ‘车’, ‘辆’, ‘流’, ‘通’, ‘辆’, ‘是’, ‘9’, ‘5’, ‘0’, ‘6’, ‘9’, ‘辆’, ‘,’, ‘七’, ‘个’, ‘座’, ‘位’, ‘以’, ‘下’, ‘的’, ‘车’, ‘辆’, ‘有’, ‘多’, ‘少’, ‘比’, ‘例’, ‘啊’], [‘麻’, ‘烦’, ‘问’, ‘问’, ‘一’, ‘共’, ‘有’, ‘多’, ‘少’, ‘个’, ‘周’, ‘成’, ‘交’, ‘额’, ‘超’, ‘过’, ‘1’, ‘0’, ‘0’, ‘0’, ‘亿’, ‘元’, ‘的’, ‘板’, ‘块’, ‘?’], [‘你’, ‘知’, ‘道’, ‘歌’, ‘手’, ‘2’, ‘0’, ‘1’, ‘9’, ‘在’, ‘芒’, ‘果’, ‘T’, ‘V’, ‘的’, ‘播’, ‘放’, ‘量’, ‘是’, ‘多’, ‘少’, ‘吗’], [‘你’, ‘知’, ‘道’, ‘杰’, ‘克’, ‘股’, ‘和’, ‘杰’, ‘瑞’, ‘股’, ‘他’, ‘两’, ‘股’, ‘票’, ‘交’, ‘易’, ‘价’, ‘格’, ‘最’, ‘大’, ‘达’, ‘到’, ‘了’, ‘几’, ‘吗’, ‘?’], [‘你’, ‘知’, ‘道’, ‘在’, ‘普’, ‘陀’, ‘区’, ‘中’, ‘海’, ‘紫’, ‘御’, ‘豪’, ‘庭’, ‘这’, ‘个’, ‘项’, ‘目’, ‘他’, ‘们’, ‘的’, ‘开’, ‘盘’, ‘数’, ‘量’, ‘是’, ‘多’, ‘少’, ‘吗’, ‘?’], [‘请’, ‘问’, ‘在’, ‘哪’, ‘个’, ‘时’, ‘间’, ‘锂’, ‘电’, ‘池’, ‘需’, ‘求’, ‘量’, ‘大’, ‘于’, ’ ', ‘3’, ‘0’, ‘G’, ‘W’, ‘h’, ’ ', ‘并’, ‘且’, ’ ', ‘三’, ‘元’, ‘电’, ‘池’, ‘需’, ‘求’, ‘量’, ‘大’, ‘于’, ’ ', ‘1’, ‘0’, ‘G’, ‘W’, ‘h’, ‘?’], [‘我’, ‘知’, ‘道’, ‘上’, ‘海’, ‘在’, ‘1’, ‘1’, ‘年’, ‘5’, ‘月’, ‘它’, ‘的’, ‘成’, ‘交’, ‘面’, ‘积’, ‘超’, ‘过’, ‘了’, ‘1’, ‘0’, ‘,’, ‘那’, ‘均’, ‘值’, ‘呢’, ‘?’], [‘呃’, ‘那’, ‘个’, ‘,’, ‘滚’, ‘动’, ‘市’, ‘盈’, ‘率’, ‘高’, ‘于’, ‘1’, ‘0’, ‘.’, ‘6’, ‘5’, ‘的’, ‘股’, ‘有’, ‘哪’, ‘些’, ‘啊’, ‘,’, ‘分’, ‘别’, ‘对’, ‘应’, ‘的’, ‘代’, ‘码’, ‘又’, ‘是’, ‘多’, ‘少’], [‘请’, ‘问’, ‘一’, ‘下’, ‘哪’, ‘个’, ‘楼’, ‘盘’, ‘名’, ‘称’, ‘的’, ‘5’, ‘月’, ‘平’, ‘均’, ‘价’, ‘格’, ‘小’, ‘于’, ‘两’, ‘万’, ‘四’, ‘而’, ‘且’, ‘月’, ‘环’, ‘比’, ‘涨’, ‘幅’, ‘小’, ‘于’, ‘4’, ‘的’], [‘我’, ‘想’, ‘知’, ‘道’, ‘有’, ‘几’, ‘家’, ‘公’, ‘司’, ‘1’, ‘0’, ‘年’, ‘和’, ‘1’, ‘1’, ‘年’, ‘每’, ‘股’, ‘收’, ‘益’, ‘都’, ‘超’, ‘过’, ‘0’, ‘.’, ‘2’, ‘元’, ‘的’], [‘你’, ‘帮’, ‘我’, ‘查’, ‘一’, ‘下’, ‘哪’, ‘些’, ‘公’, ‘司’, ‘一’, ‘二’, ‘年’, ‘和’, ‘一’, ‘三’, ‘年’, ‘的’, ‘每’, ‘股’, ‘税’, ‘后’, ‘利’, ‘润’, ‘达’, ‘到’, ‘一’, ‘块’, ‘六’, ‘毛’, ‘钱’, ‘以’, ‘上’, ‘的’, ‘吧’], [‘你’, ‘帮’, ‘我’, ‘查’, ‘查’, ‘在’, ‘哪’, ‘个’, ‘时’, ‘间’, ‘锂’, ‘电’, ‘池’, ‘需’, ‘求’, ‘量’, ‘大’, ‘于’, ’ ', ‘3’, ‘0’, ‘G’, ‘W’, ‘h’, ’ ', ‘并’, ‘且’, ’ ', ‘三’, ‘元’, ‘电’, ‘池’, ‘需’, ‘求’, ‘量’, ‘大’, ‘于’, ’ ', ‘1’, ‘0’, ‘G’, ‘W’, ‘h’, ‘?’]] -
gt_sel_num:
: [1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1] -
col_seq:
: [[[‘高’, ‘速’, ‘公’, ‘路’], [‘日’, ‘均’, ‘交’, ‘通’, ‘量’, ‘(’, ‘辆’, ‘/’, ‘日’, ‘)’], [‘7’, ‘座’, ‘以’, ‘下’, ‘(’, ‘%’, ‘)’], [‘8’, ‘-’, ‘1’, ‘9’, ‘座’, ‘以’, ‘下’, ‘(’, ‘%’, ‘)’], [‘2’, ‘0’, ‘-’, ‘3’, ‘9’, ‘座’, ‘以’, ‘下’, ‘(’, ‘%’, ‘)’], [‘4’, ‘0’, ‘座’, ‘以’, ‘上’, ‘(’, ‘%’, ‘)’], [‘1’, ‘0’, ‘-’, ‘1’, ‘5’, ‘吨’, ‘货’, ‘车’, ‘(’, ‘%’, ‘)’], [‘1’, ‘5’, ‘吨’, ‘以’, ‘上’, ‘货’, ‘车’, ‘(’, ‘%’, ‘)’]], [[‘板’, ‘块’, ‘代’, ‘码’], [‘板’, ‘块’, ‘名’, ‘称’], [‘成’, ‘分’, ‘股’, ‘个’, ‘数’], [‘周’, ‘成’, ‘交’, ‘额’, ‘(’, ‘亿’, ‘元’, ‘)’], [‘周’, ‘涨’, ‘跌’, ‘幅’, ‘%’], [‘市’, ‘盈’, ‘率’, ‘P’, ‘E’, ‘(’, ‘T’, ‘T’, ‘M’, ‘)’]], [[‘排’, ‘名’], [‘剧’, ‘集’, ‘名’, ‘称’], [‘播’, ‘放’, ‘量’, ‘(’, ‘万’, ‘)’], [‘播’, ‘出’, ‘平’, ‘台’]], [[‘代’, ‘码’], [‘公’, ‘司’], [‘股’, ‘价’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘1’, ‘8’, ‘E’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘1’, ‘9’, ‘E’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘2’, ‘0’, ‘E’], [‘P’, ‘E’, ‘2’, ‘0’, ‘1’, ‘8’, ‘E’], [‘P’, ‘E’, ‘2’, ‘0’, ‘1’, ‘9’, ‘E’], [‘P’, ‘E’, ‘2’, ‘0’, ‘2’, ‘0’, ‘E’], [‘评’, ‘级’]], [[‘序’, ‘号’], [‘项’, ‘目’, ‘名’, ‘称’], [‘位’, ‘置’], [‘发’, ‘证’, ‘日’, ‘期’], [‘开’, ‘盘’, ‘套’, ‘数’], [‘已’, ‘签’, ‘约’, ‘套’, ‘数’], [‘容’, ‘积’, ‘率’], [‘套’, ‘均’, ‘面’, ‘积’], [‘装’, ‘修’, ‘标’, ‘准’], [‘成’, ‘交’, ‘均’, ‘价’], [‘去’, ‘化’, ‘情’, ‘况’]], [[‘时’, ‘间’], [‘锂’, ‘电’, ‘池’, ‘需’, ‘求’, ‘量’], [‘锂’, ‘电’, ‘池’, ‘Y’, ‘o’, ‘Y’], [‘三’, ‘元’, ‘电’, ‘池’, ‘需’, ‘求’, ‘量’], [‘三’, ‘元’, ‘电’, ‘池’, ‘Y’, ‘o’, ‘Y’], [‘磷’, ‘酸’, ‘铁’, ‘锂’, ‘&’, ‘钴’, ‘酸’, ‘锂’, ‘需’, ‘求’, ‘量’], [‘磷’, ‘酸’, ‘铁’, ‘锂’, ‘&’, ‘钴’, ‘酸’, ‘锂’, ‘Y’, ‘o’, ‘Y’]], [[‘城’, ‘市’], [‘类’, ‘型’], [‘2’, ‘0’, ‘1’, ‘2’, ‘/’, ‘5’, ‘成’, ‘交’, ‘面’, ‘积’], [‘2’, ‘0’, ‘1’, ‘1’, ‘/’, ‘5’, ‘成’, ‘交’, ‘面’, ‘积’], [‘2’, ‘0’, ‘1’, ‘2’, ‘/’, ‘4’, ‘成’, ‘交’, ‘面’, ‘积’], [‘1’, ‘1’, ‘年’, ‘均’, ‘值’], [‘2’, ‘0’, ‘1’, ‘1’, ‘成’, ‘交’, ‘面’, ‘积’, ‘同’, ‘比’], [‘2’, ‘0’, ‘1’, ‘2’, ‘成’, ‘交’, ‘面’, ‘积’, ‘同’, ‘比’], [‘成’, ‘交’, ‘面’, ‘积’, ‘环’, ‘比’], [‘2’, ‘0’, ‘1’, ‘2’, ‘/’, ‘5’, ‘成’, ‘交’, ‘套’, ‘数’], [‘2’, ‘0’, ‘1’, ‘1’, ‘/’, ‘5’, ‘成’, ‘交’, ‘套’, ‘数’], [‘2’, ‘0’, ‘1’, ‘2’, ‘/’, ‘4’, ‘成’, ‘交’, ‘套’, ‘数’], [‘成’, ‘交’, ‘套’, ‘数’, ‘同’, ‘比’], [‘成’, ‘交’, ‘套’, ‘数’, ‘环’, ‘比’]], [[‘股’, ‘票’, ‘代’, ‘码’], [‘股’, ‘票’, ‘简’, ‘称’], [‘P’, ‘E’, ‘-’, ‘T’, ‘T’, ‘M’], [‘P’, ‘B’], [‘P’, ‘S’]], [[‘楼’, ‘盘’, ‘名’, ‘称’], [‘5’, ‘月’, ‘均’, ‘价’, ‘(’, ‘元’, ‘/’, ‘㎡’, ‘)’], [‘月’, ‘环’, ‘比’, ‘涨’, ‘幅’]], [[‘公’, ‘司’, ‘名’, ‘称’], [‘总’, ‘市’, ‘值’, ‘(’, ‘亿’, ‘元’, ‘)’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘1’, ‘0’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘1’, ‘1’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘1’, ‘2’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘1’, ‘3’], [‘P’, ‘E’, ‘2’, ‘0’, ‘1’, ‘0’], [‘P’, ‘E’, ‘2’, ‘0’, ‘1’, ‘1’], [‘P’, ‘E’, ‘2’, ‘0’, ‘1’, ‘2’], [‘P’, ‘E’, ‘2’, ‘0’, ‘1’, ‘3’], [‘P’, ‘B’], [‘R’, ‘N’, ‘A’, ‘V’, ‘P’], [‘折’, ‘价’, ‘率’], [‘评’, ‘级’]], [[‘公’, ‘司’, ‘名’, ‘称’], [‘股’, ‘价’, ‘1’, ‘2’, ‘0’, ‘6’, ‘0’, ‘6’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘1’, ‘2’, ‘E’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘1’, ‘3’, ‘E’], [‘E’, ‘P’, ‘S’, ‘2’, ‘0’, ‘1’, ‘4’, ‘E’], [‘P’, ‘E’, ‘2’, ‘0’, ‘1’, ‘2’], [‘P’, ‘B’, ‘2’, ‘0’, ‘1’, ‘2’, ‘Q’, ‘1’], [‘折’, ‘/’, ‘溢’, ‘价’, ‘2’, ‘0’, ‘1’, ‘2’], [‘评’, ‘价’]], [[‘时’, ‘间’], [‘锂’, ‘电’, ‘池’, ‘需’, ‘求’, ‘量’], [‘锂’, ‘电’, ‘池’, ‘Y’, ‘o’, ‘Y’], [‘三’, ‘元’, ‘电’, ‘池’, ‘需’, ‘求’, ‘量’], [‘三’, ‘元’, ‘电’, ‘池’, ‘Y’, ‘o’, ‘Y’], [‘磷’, ‘酸’, ‘铁’, ‘锂’, ‘&’, ‘钴’, ‘酸’, ‘锂’, ‘需’, ‘求’, ‘量’], [‘磷’, ‘酸’, ‘铁’, ‘锂’, ‘&’, ‘钴’, ‘酸’, ‘锂’, ‘Y’, ‘o’, ‘Y’]]] -
col_num
: [8, 6, 4, 10, 11, 7, 14, 5, 3, 14, 9, 7] -
ans_seq:相当于where后面除了条件值都有了
ans_seq.append(
(
len(sql[‘sql’][‘agg’]),选择的列相应的聚合函数的个数, '0’代表无
sql[‘sql’][‘sel’],列
sql[‘sql’][‘agg’],选择的列相应的聚合函数, '0’代表无
conds_num,
tuple(x[0] for x in sql[‘sql’][‘conds’]),
tuple(x[1] for x in sql[‘sql’][‘conds’]),
sql[‘sql’][‘cond_conn_op’],
))
: [(1, [2], [0], 2, (1, 0), (2, 2), 1), (1, [1], [4], 1, (3,), (0,), 0), (1, [2], [0], 2, (3, 1), (2, 2), 1), (1, [2], [2], 2, (1, 1), (2, 2), 2), (1, [4], [0], 2, (2, 1), (2, 2), 1), (1, [0], [0], 2, (1, 3), (0, 0), 1), (1, [5], [0], 2, (0, 3), (2, 0), 1), (2, [0, 1], [0, 0], 1, (2,), (0,), 0), (1, [0], [0], 2, (1, 2), (1, 1), 2), (1, [0], [4], 2, (2, 3), (0, 0), 1), (1, [0], [0], 2, (2, 3), (0, 0), 1), (1, [0], [0], 2, (1, 3), (0, 0), 1)] -
gt_cond_seq,就是原始的conds,前面两个是列,后面是值
: [[[1, 2, ‘95,069.00’], [0, 2, ‘沪宁高速公路’]], [[3, 0, ‘1000’]], [[3, 2, ‘芒果TV’], [1, 2, ‘歌手2019’]], [[1, 2, ‘杰瑞股份’], [1, 2, ‘杰克股份’]], [[2, 2, ‘普陀区’], [1, 2, ‘中海紫御豪庭’]], [[1, 0, ‘30’], [3, 0, ‘10’]], [[0, 2, ‘上海’], [3, 0, ‘10’]], [[2, 0, ‘10.65’]], [[1, 1, ‘24000’], [2, 1, ‘4’]], [[2, 0, ‘0.2’], [3, 0, ‘0.2’]], [[2, 0, ‘1.6’], [3, 0, ‘1.6’]], [[1, 0, ‘30’], [3, 0, ‘10’]]] -
gt_where_seq,原始提问句前后分别插入了《BEG》和《END》,然后原文如果可以找到答案,就返回[0,答案_start,答案_end,句子长度],原文找不到答案,就返回[0,句子长度]
: [[[[0, 38]], [0, 1, 2, 3, 4, 5, 6, 38]], [[0, 17, 18, 19, 20, 27]], [[0, 11, 12, 13, 14, 23], [0, 4, 5, 6, 7, 8, 9, 23]], [[[0, 27]], [[0, 27]]], [[0, 5, 6, 7, 30], [0, 8, 9, 10, 11, 12, 13, 30]], [[0, 17, 18, 42], [0, 36, 37, 42]], [[0, 4, 5, 29], [0, 21, 22, 29]], [[0, 12, 13, 14, 15, 16, 35]], [[[0, 34]], [0, 32, 34]], [[0, 24, 25, 26, 29], [0, 24, 25, 26, 29]], [[[0, 36]], [[0, 36]]], [[0, 20, 21, 45], [0, 39, 40, 45]]] -
gt_sel_seq,gt_sel_seq = [x[1] for x in ans_seq],就是单独列的id
: [[2], [1], [2], [2], [4], [0], [5], [0, 1], [0], [0], [0], [0]]
附录:
{
"table_id": "a1b2c3d4", # 相应表格的id
"question": "世茂茂悦府新盘容积率大于1,请问它的套均面积是多少?", # 自然语言问句
"sql":{ # 真实SQL
"sel": [7], # SQL选择的列
"agg": [0], # 选择的列相应的聚合函数, '0'代表无
"cond_conn_op": 0, # 条件之间的关系
"conds": [
[1,2,"世茂茂悦府"], # 条件列, 条件类型, 条件值,col_1 == "世茂茂悦府"
[6,0,1]
]
}
}
#其中,SQL的表达字典说明如下:
op_sql_dict = {0:">", 1:"<", 2:"==", 3:"!="}
agg_sql_dict = {0:"", 1:"AVG", 2:"MAX", 3:"MIN", 4:"COUNT", 5:"SUM"}
conn_sql_dict = {0:"", 1:"and", 2:"or"}
# q_seq: char-based sequence of question
# gt_sel_num: number of selected columns and aggregation functions
# col_seq: char-based column name
# col_num: number of headers in one table
# ans_seq: (sel, number of conds, sel list in conds, op list in conds)
# gt_cond_seq: ground truth of conds
6 数据认识
6.1 样例1
question: 二零一九年第四周大黄蜂和密室逃生这两部影片的票房总占比是多少呀
sql_string: {"agg": " SUM", "sel": " 票房占比(%)", "cond_conn_op": "or", "conds": "影片名称==大黄蜂影片名称==密室逃生"}
header: ['影片名称', '周票房(万)', '票房占比(%)', '场均人次']
id_train_tabel: {"rows": [["死侍2:我爱我家", 10637.3, 25.8, 5.0], ["白蛇:缘起", 10503.8, 25.4, 7.0], ["大黄蜂", 6426.6, 15.6, 6.0], ["密室逃生", 5841.4, 14.2, 6.0], ["“大”人物", 3322.9, 8.1, 5.0], ["家和万事惊", 635.2, 1.5, 25.0], ["钢铁飞龙之奥特曼崛起", 595.5, 1.4, 3.0], ["海王", 500.3, 1.2, 5.0], ["一条狗的回家路", 360.0, 0.9, 4.0], ["掠食城市", 356.6, 0.9, 3.0]], "name": "Table_4d29d0513aaa11e9b911f40f24344a08", "title": "表3:2019年第4周(2019.01.28 - 2019.02.03)全国电影票房TOP10", "header": ["影片名称", "周票房(万)", "票房占比(%)", "场均人次"], "common": "资料来源:艺恩电影智库,光大证券研究所", "id": "4d29d0513aaa11e9b911f40f24344a08", "types": ["text", "real", "real", "real"]}
- agg SUM
可以通过语句和列名直接得到 - sel 票房占比
可以通过语句和列名直接得到 - cond_conn_op or
可以通过语句直接判别 - conds 影片名称大黄蜂,影片名称密室逃生
这个个数可以很准了
columns不准:因为它不知道大黄蜂是属于电影名称还是票房还是啥,和加入列下的字符串来优化(取set就行),数字的统一用一个字表示,然后来分类。
values不准:把中文加尽量,数字用其他字符代替,数字需要分组。
op不准:这个为啥不准?
6.2 样例2
question: 你好,我要查询一下涨跌幅超过20%的证券名称以及证券代码,谢谢
sql_string: {"agg": " ", "sel": " 证券名称 证券代码", "cond_conn_op": "", "conds": "涨跌幅(%)>20"}
header: ['证券代码', '证券名称', '涨跌幅(%)']
id_train_tabel: {"rows": [["300010.SZ", "立思辰", 13.13], ["300079.SZ", "数码科技", 5.56], ["002602.SZ", "世纪华通", 5.3], ["002640.SZ", "跨境通", 5.25], ["002555.SZ", "三七互娱", 5.19], ["600652.SH", "游久游戏", 23.31], ["002354.SZ", "天神娱乐", 23.21], ["601811.SH", "新华文轩", 21.15], ["300148.SZ", "天舟文化", 20.47], ["000673.SZ", "当代东方", 20.0]], "name": "Table_4d24aa113aaa11e9baa9f40f24344a08", "title": "图表1. A股传媒板块本周涨跌幅排行(2019.01.28-2019.02.01)", "header": ["证券代码", "证券名称", "涨跌幅(%)"], "common": "资料来源:万得,中银国际证券", "id": "4d24aa113aaa11e9baa9f40f24344a08", "types": ["text", "text", "real"]}
- agg “”
可以通过语句和列名直接得到 - sel 证券名称 证券代码
可以通过语句和列名直接得到 - cond_conn_op “”,一个的话就为空
可以通过语句直接判别 - conds 涨跌幅(%)>20
这个个数可以很准了
columns不准:涨跌幅(%)根据列名和语句可以搞出来。
values不准:20%。总感觉数字可以编码,然后再得到。
op不准:根据列名和语句可以搞出来