快速搭建redis5.0集群
redis主从集群搭建

redis简单主从结构如上图所示,主从结构的redis由主节点负责读写操作,从节点负责读操作,这里做搭建介绍,具体工作原理不分析。
-
下载安装redis压缩包
-
解压压缩包,进入redis-5.0文件夹,运行命令./make install安装redis
-
安装完成进入redis-5.0/src文件夹,执行./redis-server 指定配置文件 即可启动redis
-
redis-cli 默认连接本机6379redis服务器
主从集群的搭建非常简单,要做的有一下的步骤:
-
注释掉redis-conf配置文件的以下配置,并且在redis-5.0/目录下创建一个文件夹6379-6380
# bind 127.0.0.1 #如果想要redis后台运行泽东配置为yes daemonize yes -
根据redis.conf配置文件,复制两份配置文件到文件夹文件夹6379-6380,模拟在同一台机器上启动两个redis实例。复制文件名为master.conf和slave.conf
-
修改slave.conf配置文件端口为6380,增加配置slaveof 127.0.0.1 6379
port 6380 #主节点的主机地址和端口号,这里是本机 slaveof 127.0.0.1 6379 -
在src下执行redis-server命令,分别指定配置文件为刚才配置master和slave配置文件。连接6379的redis服务器,执行info replication,显示如下所示。
# Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=224,lag=0 master_replid:201640b5a63c036087b7a459245a6f6a699b8a36 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:224 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:224
如果执行redis-cli -h 127.0.0.1 -p 6380则是指定连接从节点,执行info replication显示如下
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:462
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:201640b5a63c036087b7a459245a6f6a699b8a36
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:462
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:462
以上搭建起一个简单的主从集群
哨兵主从集群搭建
简单的主从集群有个问题,就是主节点挂了之后,无法从新选举新的节点作为主节点进行写操作,导致服务不可用
。当主节点挂了,尝试执行set命令,报如下错误。
(error) READONLY You can't write against a read only replica.
因此,需要一种机制对主节点挂了的集群进行监控,并且重新选举主节点,这就是哨兵的作用。
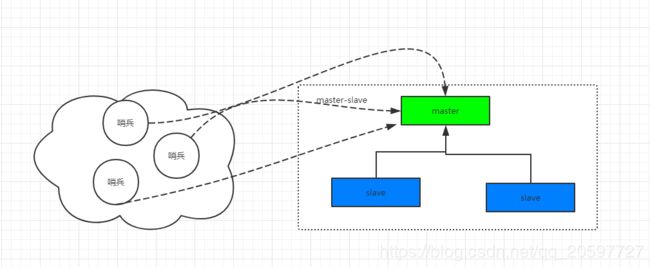
搭建哨兵主从集群,需要做以下几个步骤:
-
主从集群搭建步骤跟上面一样
-
哨兵创建,需要配置哨兵配置文件,复制一份sentinel.conf到6379-6380文件夹下面,编辑如下配置
#配置监视的进群的主节点ip和端口 1表示至少需要几个哨兵统一认定才可以做出判断 sentinel monitor mymaster 127.0.0.1 6380 1 #表示如果5s内mymaster没响应,就认为SDOWN sentinel down-after-milliseconds mymaster 5000 #表示如果15秒后,mysater仍没活过来,则启动failover,从剩下从节点序曲新的主节点 sentinel failover-timeout mymaster 15000 -
然后,就可以执行src目录下的redis-sentinel 指定配置文件 命令,来启动一个哨兵。连接6379端口的主节点,执行shutdown关闭主节点,连接从节点查询状态,过一阵子后,执行info replication,显示如下,编程了主节点
role:master connected_slaves:0 master_replid:7c049957e22948d8c346154422498159fcd371b6 master_replid2:cb6c2d58d978e917cc75ae6b2b278a3ced21fae8 master_repl_offset:2482 second_repl_offset:1130 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:2482 -
哨兵也可以进行集群,只需要修改配置文件的端口,监听的还是同一个主节点,即可实现哨兵集群。哨兵集群保证哨兵的可用性从而保证redis集群选举的可用性。同时多个哨兵监听还涉及到前面说的哨兵投票机制,需要几个哨兵才能判定主节点下线。
redis-cluster搭建
尽管可以使用哨兵主从集群实现可用性保证,但是这种实现方式每个节点的数据都是全量复制,数据存放量存在着局限性,受限于内存最小的节点,因此考虑采用数据分片的方式,来实现存储,这个就是redis-cluster。
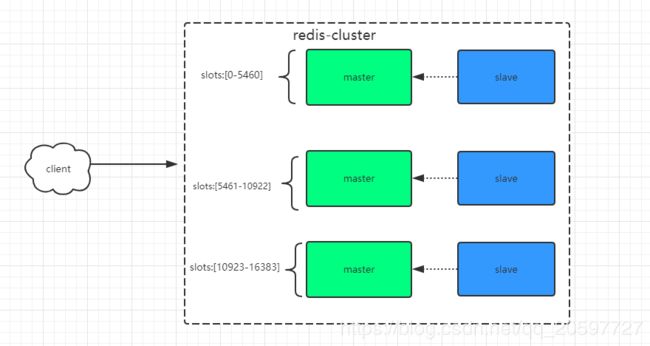
- 基于原来的主从配置,继续下去,首先主从模式的slaveof host port配置会与cluster配置冲突
*** FATAL CONFIG FILE ERROR ***
Reading the configuration file, at line 94
>>> 'slaveof 127.0.0.1 6381'
replicaof directive not allowed in cluster mode
因此配置文件需要做以下改造
# slaveof 127.0.0.1 6379
同时,需要开启redis-cluster配置,配置做以下改造
#配置yes开启redis-cluster
cluster-enabled yes
#配置节点之间超时时间
cluster-node-timeout 15000
#这个配置很重要,cluster开启必须重命名指定cluster-config-file,不能与别的节点相同,否则会启动失败,最好按主机+端口命名
cluster-config-file nodes-6379.conf
cluster-config-file相同时,启动失败,报以下错误
Sorry, the cluster configuration file nodes.conf is already used bySorry, the cluster configuration file nodes.conf is already used by
-
完成以上配置之后,可以使用src下的redis-server命令,逐个启动redis实例。因为redis-cluster需要使用到ruby,所以需要安装ruby,ubuntu下,apt-get install ruby.
-
最后是执行创建集群,这里使用的是5.0版本的redis,创建集群命令都从./redis-trib.rb 迁移到redis-cli,可以使用redis-cli --cluster help来查看命令帮助;
执行以下命令,创建集群。
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
很不幸,报错如下,提示我们redis服务实例上的数据不为空,因此逐个实例连接,执行flushdb,清空数据。
[ERR] Node 127.0.0.1:6379 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
再次执行命令,成功创建cluster,显示如下,虽然成功创建,但是有个error。提示我们不是所有的slot都被节点覆盖到,官方的建议是使用fix修复
[ERR] Not all 16384 slots are covered by nodes.
执行redis-cli --cluster fix,显示了修正结果,槽位重新分配。
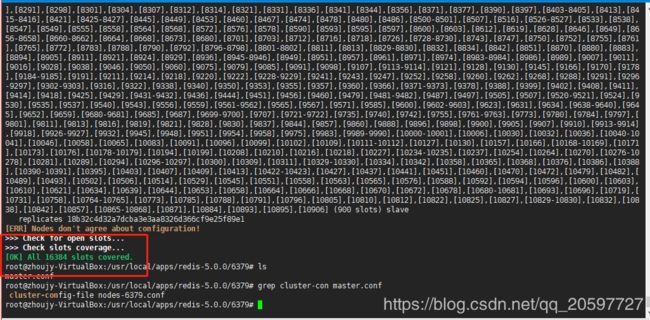
可以执行redis-cli --cluster check host:port检查集群状态slots详细分配。
执行redis-cli --cluster info 127.0.0.1:6382检查集群状态,打印如下,发现redis-cluster自动给节点分配了主从属性,但是6个节点却有四个主节点,导致两个主节点没slave.这样的集群其实是创建失败的,需要删除集群重新创建。
127.0.0.1:6383 (494559b1...) -> 0 keys | 883 slots | 0 slaves.
127.0.0.1:6384 (18b32c4d...) -> 0 keys | 917 slots | 1 slaves.
127.0.0.1:6381 (f2fbb2e0...) -> 0 keys | 6364 slots | 0 slaves.
127.0.0.1:6379 (0c7dd21b...) -> 0 keys | 6401 slots | 1 slaves.
-
关闭所有服务实例
-
找到对应的nodes-port.conf文件,删除
-
重新执行redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
最后正确创建的话会打印如下信息:
creating cluster...... >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 127.0.0.1:6382 to 127.0.0.1:6379 Adding replica 127.0.0.1:6383 to 127.0.0.1:6380 Adding replica 127.0.0.1:6384 to 127.0.0.1:6381 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: e13808e5d468b3e91cf6ef7f06a56a4ab662bde3 127.0.0.1:6379 slots:[0-5460] (5461 slots) master M: 2a79a606f0b378f765ce5b04fb15e16c540d4021 127.0.0.1:6380 slots:[5461-10922] (5462 slots) master M: 1ad280f911c1661f223526cb93b13c8e6dab7a88 127.0.0.1:6381 slots:[10923-16383] (5461 slots) master S: 0b01253b7d5f2927d303545cdd3dd4b774f82e83 127.0.0.1:6382 replicates 1ad280f911c1661f223526cb93b13c8e6dab7a88 S: e07329aea1976dad6d40b936efab920788029252 127.0.0.1:6383 replicates e13808e5d468b3e91cf6ef7f06a56a4ab662bde3 S: 568ac0049c41d93489a1b27aa922215aeb894221 127.0.0.1:6384 replicates 2a79a606f0b378f765ce5b04fb15e16c540d4021 Can I set the above configuration? (type 'yes' to accept):上面可以清楚看到集群的slot分配信息以及主从节点信息
如果需要动态添加或者删除集群中的节点怎么办?
执行redis-cli --cluster help,显示如下信息:
Cluster Manager Commands:
create host1:port1 ... hostN:portN
--cluster-replicas
check host:port
info host:port
fix host:port
reshard host:port
--cluster-from
--cluster-to
--cluster-slots
--cluster-yes
--cluster-timeout
--cluster-pipeline
rebalance host:port
--cluster-weight
--cluster-use-empty-masters
--cluster-timeout
--cluster-simulate
--cluster-pipeline
--cluster-threshold
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id
del-node host:port node_id
call host:port command arg arg .. arg
set-timeout host:port milliseconds
import host:port
--cluster-from
--cluster-copy
--cluster-replace
help
add-node方法可以添加节点,还可以指定是主节点还是从节点。del-node是删除指定节点。还有其它的fix修复命令,reshard重新分配slot等等。