Hive知识点(持续更新中)
集群安装详细步骤见我的博客:https://blog.csdn.net/qq_25948717/article/details/81054411。
Hive是基于Hadoop的一个数据仓库处理工具,是一种数据库技术,用于查询和管理存储在分布式环境下的大数据集,可以定义数据库和表来分析结构化数据,适合处理相对静态的海量的数据集。可以将结构化的数据映射为一张数据库表,提供简单的SQL的查询功能,将SQL语句转化为MapReduce任务提交到Hadoop集群运行,十分适合数据仓库的统计分析。
Hive并不提供实时的查询和基于行级的数据更新操作,Hive在加载数据的过程中不会对数据进行任何修改,只是将数据
移动到Hive设定(hive-site.xml)的HDFS目录中,将HDFS中的数据变成关系型数据库的逻辑结构,在Hive中创建的数据库其实是假的,所以需要一个映射关系数据(即元数据(metastore)),因此,Hive不支持对数据的改写和添加。Hive的最佳使用场合就是大数据集的批处理操作。
目前Hive将metastore数据存储在RDBMS数据库中,HIve有三种模式可以访问数据库中的metastore内容:
(1)单用户本地模式:使用简单基于内存的数据库derby
(2) 多用户本地模式:使用本地的关系数据库Mysql,提供多用户并发访问
(3) 远程服务器模式:使用单独的机器部署数据库服务器,配置远程访问权限
Hive的体系结构:
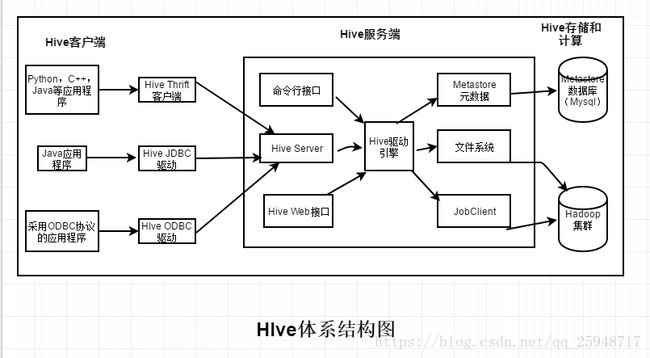
Hive引擎:解释器(将脚本解释成Java代码),编译器(将Java代码编译提交到Hadoop中),优化器(提交过程中优化Java代码-->
mapreduce作业)
HIve syhell运行在Hadoop集群之上,是Hive提供的命令行接口,Hive shell会把HQL查询转化为一系列的MapReduce任务并行进行处理,命令以“;”结束。
注意:HIve并不是存储数据,而是管理在HDFS上的数据,通过HIve表导入数据只是简单地将数据移动或者复制hive表所在的HDFS目录中。Hive不是数据库,也不是服务。可以理解为Hadoop的客户端,安装在任何机器下都行。
HIve管理数据的方式:Managed Table(内部表)、External Table(外部表)、Partition(分区)、Bucket(桶)。
删除外部表时只会删除外部表对应的元数据,其对应的表数据不会删除,而删除内部表都会删除,所以可以看出内部表是由Hivve进行管理的。
在HIve中,表的每一个分区对应表目录下的一个子目录,所分区的数据都是存储在对应的子目录中。
桶是对应列的数据的划分。
=====================================================================
数据库的操作:
CREATE DATABASE yexin; 或者 CREATE SCHEMA yexin; --------------------创建数据库
DROP DATABASE IF EXISTS yexin;或者 DROP SCHEMA yexin--------------------------删除数据库
-
--创建数据库
-
create database if not exists sopdm
-
comment ‘this is test database’
-
with dbproperties(‘creator’=’gxw’,’date’=’2014-11-12’) --数据库键值对属性信息
-
location ‘/my/preferred/directory’;
-
--查看数据库的描述信息和文件目录位置路径信息
-
describe database sopdm;
-
--查看数据库的描述信息和文件目录位置路径信息(加上数据库键值对的属性信息)
-
describe database extended sopdm
-
--删除数据库
-
drop database if exists sopdm;
-
--级联删除数据库(当数据库还有表时,级联删除表后在删除数据库),默认是restrict
-
drop database if exists sopdm cascade;
-
--修改数据库
-
--只能修改数据库的键值对属性值。数据库名和数据库所在的目录位置不能修改
-
alter database sopdm set dmproperties(‘edited-by’=’gaoxianwei’);
-
--创建表
-
--其中tblproperties作用:按照键值对的格式为表增加额外的文档说明,也可用来表示数据库连接的必要的元数据信息
-
--hive会自动增加二个表属性:last_modified_by(最后修改表的用户名),last_modified_time(最后一次修改的时间)
-
create table if not exists sopdm.test1(name string comment ‘姓名’,salary float comment ‘薪水’)
-
comment ‘这是一个测试的表’
-
tblproperties(‘creator’=’me’,’created_at’=’2014-11-13 09:50:33’)
-
location ‘/user/hive/warehouse/sopdm.db/test1’
-
--查看和列举表的tblproperties属性信息
-
show tblproperties table_name;
-
--使用like在创建表的时候,拷贝表模式(而无需拷贝数据)
-
create table if not exists sopdm.test2 like sopdm.test1;
-
--查看表的详细结构信息(也可以显示表是管理表,还是外部表。还有分区信息)
-
describe extended sopdm.test1;
-
--使用formatted信息更多些,可读性更强
-
describe formatted sopdm.test1;
-
--创建外部表
-
--删除表时,表的元数据会被删除掉,但是数据不会被删除
-
--如果数据被多个工具(如pig等)共享,可以创建外部表
-
create external table if not exists sopdm.test1(
-
name string comment ‘姓名’,
-
salary float comment ‘薪水’)
-
comment ‘这是一个测试的表’
-
tblproperties(‘creator’=’me’,’created_at’=’2014-11-13 09:50:33’)
-
location ‘/user/hive/warehouse/sopdm.db/test1’
-
--分区表
-
create table if not exists sopdm.test1(
-
name string comment ‘姓名’,
-
salary float comment ‘薪水’)
-
comment ‘这是一个测试的表’
-
partitioned by(country string,state string)
-
STORED AS rcfile
-
tblproperties(‘creator’=’me’,’created_at’=’2014-11-13 09:50:33’)
-
location ‘/user/hive/warehouse/sopdm.db/test1’
-
--查看表中存在的所有分区
-
show partitions table_name;
-
--查看表中特定分区
-
show partitions table_name partition(country=’US’);
-
--可以在表载入数据的时候创建分区
-
load data local inpath ‘${env:HOME/employees}’
-
into table employees
-
partition(country=’US’,state=’CA’);
-
--删除表
-
drop table if exists table_name;
-
--修改表-表重命名
-
alter table old_table_name rename to new_table_name;
-
--增加分区
-
alter table table_name add if not exists partition(year=2011,month=1,day=1)
-
location ‘/logs/2011/01/01’;
-
--修改分区存储路径
-
alter table table_name partition(year=2011,month=1,day=2)
-
set location ‘/logs/2011/01/02’;
-
--删除某个分区
-
alter table table_name drop if exists partition(year=2011,month=1,day=2);
-
--修改列信息
-
alter table table_name
-
change column old_name new_name int
-
comment ‘this is comment’
-
after severity; --字段移到severity字段之后(移动到第一个位置,使用first关键字)
-
--增加列
-
alter table table_name add columns(app_name string comment ‘application name’);
-
--删除或者替换列
-
alter table table_name replace columns(hms int comment ‘hhh’);
-
--修改表属性
-
alter table table_name set tblproperties(‘notes’=’this is a notes’);
-
--修改存储属性
-
alter table table_name partition(year=2011,month=1,day=1) set fileformat sequencefile;
-
--指定新的SerDe,并指定SerDe属性
-
alter table table_name
-
set serde “com.example.JSONSerDe”
-
with serdeproperties(‘prop1’=‘value1’, ‘prop2’=‘value2’);
-
--增加执行“钩子”——当表中存储的文在hive之外被修改了,就会触发钩子的执行
-
alter table table_name touch partition(year=2012,month=1,day=1);
-
--将分区内的文件打成hadoop压缩包文件,只会降低文件系统中的文件数,减轻NameNode的压力,而不会减少任何的存储空间
-
--使用unarchive替换archive起到反向操作
-
alter table table_name archive partition(year=2012,month=1,day=1);
-
--防止分区被删除和被查询(使用enable替代disable可以起到反向的操作目的)
-
alter table table_name partition(year=2012,month=1,day=1) disable no_drop;
-
alter table table_name partition(year=2012,month=1,day=1) disable offline;
-
--向管理表中装载数据
-
-- inpath为一个目录,而且这个路径下不可以包含任何文件夹
-
load data local inpath ‘${env:HOME}/table_name’
-
overwrite into table table_name
-
partition(country=’US’);
-
--通过查询语句向表中插入数据
-
--overwrite是覆盖,into是追加
-
insert overwrite table table_name
-
partition(country=’US’)
-
select * from table_name2 tn where tn.cnty=’US’
-
--高效方式-查询语句插入多个分区
-
from table_name2 tn
-
insert overwrite table table_name
-
partition(country=’US’,state=’OR’)
-
select * where tn.cnty=’US’ and tn.st=’OR’
-
insert overwrite table table_name
-
partition(country=’US’,state=’CA’)
-
select * where tn.cnty=’US’ and tn.st=’CA’
-
--动态插入分区
-
--hive根据select语句最后2列确定分区字段country和state的值(根据位置)
-
insert overwrite table table_name
-
partition(country,state)
-
select …,se.cnty,se.st
-
from employees se;
-
--动态和静态分区结合
-
--country为静态分区,state为动态分区(静态分区必须在动态分区之前)
-
insert overwrite table table_name
-
partition(country=‘US’,state)
-
select …,se.cnty,se.st
-
from employees se
-
where se.cnty=’US’;
-
--单个查询语句中创建表并加载数据
-
create table table_name1
-
as select name,salary,address from table_name2 where state=’CA’;
-
--导出数据——拷贝文件
-
--如果数据文件恰好是用户需要的格式,那么只需要简单的拷贝文件或文件夹就可以。
-
hadoop fs –cp source_path target_path
-
--导出数据
-
insert overwrite local directory ‘/tmp/employees’
-
select name,salary,address from employees se where se.state=’CA’
-
--导出数据到多个输出文件夹
-
from employees se
-
insert overwrite local directory ‘/tmp/or_employees’
-
select * se where se.cty=’US’ and se.st=’OR’
-
insert overwrite local directory ‘/tmp/ca_employees’
-
select * se where se.cty=’US’ and se.st=’CA’
创建表:
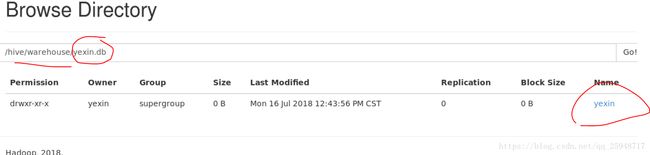
create table if not exists yexin.yexin(name string comment 'name',salary float comment 'money') comment 'this is test table';
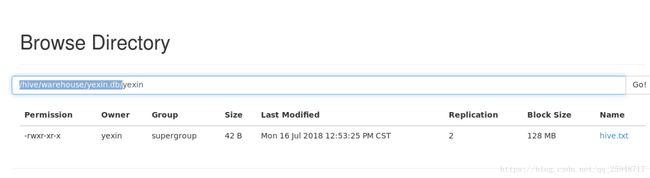
网页中可以看到数据库表的成功:
利用文件导入数据到表:
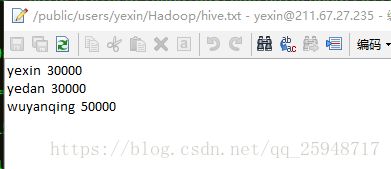 txt文件
txt文件
上传到hdfs的/hive/input,再导入:

LOAD DATA INPATH '/hive/input/hive.txt' OVERWRITE INTO TABLE yexin;
如果是本文件就是:LOAD DATA LOCAL INPATH '/hive/input/hive.txt' OVERWRITE INTO TABLE yexin;
注意:导入之后/hive/input/下就没有hive.txt文件了,因为上传到/hive/warehouse/yexin.db/了: