性能优化——记高性能MySQL
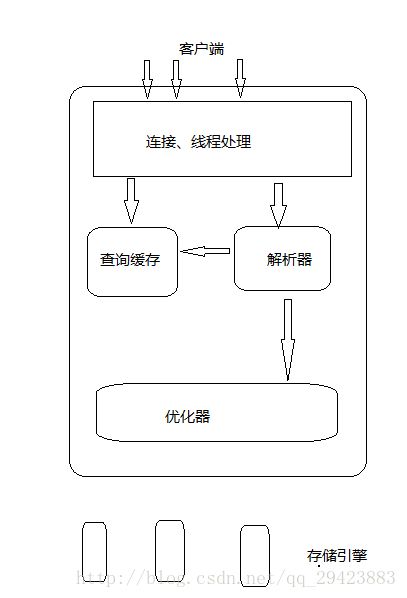
MySQL服务器逻辑架构
第一层,客户端/服务器。负责连接,授权,安全等。每个客户端连接都会在服务器拥有一个线程。解析器解析查询并创建解析树,然后优化(重写查询,选择索引等)节奏执行,select语句在解析之前先会先查询缓存若存在,直接返回结果。
第二层,核心服务。如查询解析,优化,缓存,内置函数,存储过程,触发器,视图…
第三层,存储引擎。负责数据存储和提取。
事务
ACID
- 原子性(atomicity):一个事务是不可分割的最小工作单元,要么全部提交成功,要么全部提交失败
- 一致性(consistency):数据库总是从一个一致性的状态转换到另外一个一致性的状态。
- 隔离性(isolation):一个事务所做的修改在最终提交之前,对其他事务不可见。
- 持久性(durability):一旦事务提交,所做的修改就会永久保存到数据库中。
隔离级别
较低级别的隔离可以执行更高的并发,系统开销也低 - 未提交读(READ UNCOMMITTED)。事务中的修改,即使没有提交,其他事务都是可见的(脏读)。很少用。
- 提交读(READ COMMITTED)。事务从开始到提交之前,所做的修改对其他事务不可见。一般用。
- 可重复读(REPEATABLE READ)。MySQL默认的。
- 可串行化(SERIALIZABLE)。强制事务串行执行,最高隔离,行级加锁。很少用。
Schema与数据类型优化
优化数据类型
1.尽量使用可以正确存储数据的最小数据类型。原因:占用更少磁盘,内存,cup。
2.使用简单的。整型比字符操作代价低,原因:字符集和校队规则。
3.避免null。原因:可为null的列索引统计更复杂,更多存储空间,如果确实需要才使用。
4.时间类型。int 可以记录大范围的时间,datetime类型(范围1001-9999)适合用来记录数据的原始的创建时间,timestamp(范围1970-2038)类型适合用来记录数据的最后修改时间,只要修改记录,timestamp字段的值都会被自动更新。
5.小数类型。float和double近似小数,decimal精确小数,尽量只在对小数精确计算时使用,数据量大时使用bigint替代。
6.字符型。varchar可变长字符串适合长的字符串(需要额外的1或2个字节记录长度),char定长的,长度不够用空格填充,适合短的字符串及定值的如MD5值,或者经常变更的。
7.存储很大的字符串数据。使用blob(二进制方式)和text(字符方式,有排序规则和字符集),性能低下,尽量避免。
8.存储IPv4使用整型而不是varchar(15),因为它实际就是32位无符号整数,加小数点只是方便阅读。
数据库设计注意
1.设计表非常宽,如果只有一小部分用到,转换代价就非常高,尽量避免。
2.太多关联。
索引优化
在MySQL中索引在存储引擎层,所以不同的存储引擎有不同的工作方式。一般情况都是指B-Tree索引,索引的优点:减少服务器需要扫描的数据量;帮助服务器避免排序和临时表;将随机I/O变为顺序I/O。
- Tree索引
意味着索引的值都是按顺序存储的,之所以加快访问数据的速度,因为存储引擎不再需要全表扫描,而是从索引的根节点开始搜索。
- 哈希索引
基于哈希表实现,只有精确匹配索引所有列的查询才有效。冲突越多代价越大,只适用于特定场合,如url等。
- 使用
- 独立的列。是指索引列不能是表达式的一部分,也不能是函数的参数。
- 前缀索引和索引选择性。如果索引需要很长的字符列,通常可以选择索引开始的部分字符,从而节约索引空间,提高效率,但会降低选择性。当然MySQL无法使用前缀索引做排序
- 多列索引。在多个列上建立独立的单列索引大部分情况不能提高查询性能。MySQL可以使用索引合并策略
- 选择合适的索引列顺序。当不需要考虑排序和分组时,将选择性最高的列放在前面,这时候索引的作用只是用于优化where条件的查找。
- 聚族索引。它并不是一种索引类型,而是一种数据存储方式。表示数据行和相邻键值紧凑的存储在一起,故一个表只能有一个聚族索引。
- 顺序主键。使用InnoDB尽可能的按主键顺序插入数据,尽可能使用单调增加的聚簇键的值插入新行,但对于高并发工作负载,会造成间隙锁竞争。
- 覆盖索引。是指索引包含(覆盖)所有需要查询的字段的值。优秀的索引不应该只考虑到where条件,而应该考虑整个查询,因为MySQL的索引可以直接获取列的数据,这样就不需要读取数据行,回表查询。如果索引不能覆盖查询的所有列,或者查询中有like操作,那么索引将无法覆盖查询,这时候就需要重写查询
//重写前
select * from ta1 where a='**' and b like '**%';
//重写后
select * from tal
join(
select id from tal where a='**' b like '**%'
) as t2 on (t2.id=tal.id);使用延迟关联,这样就能覆盖第一阶段的查询
- 重复索引,MySQL允许同一列上创建多个索引
create table test(
id int not null primary key,
a int not null,
unique(id),
index(id)
)这样id上就有三个索引了,因为MySQL唯一和主键限制都是通过索引来实现的。
- 不用的索引。留着占位置,删除就好。
查询优化
- 查询的过程。客户端–服务端–解析–生成执行计划–执行–返回结果
- 不要查询不需要的记录。分页操作使用limit,而不是全部查出来再分页。
- 不能select * from …。
- 如果查询需要扫描大量的数据但只返回少数的行,可以使用索引覆盖扫描,或者使用单独的汇总表,或者重写查询。
- 拆分查询。一条复杂拆分成几条简单的查询
- 切分查询。比如一次删除10万行,切分成一次删除一万行。
- 分解关联查询。多表关联,可以对每一个表单查,将结果在应用程序中关联。
MySQL优化器 - 重新定义关联表的顺序(即关联并不是按查询中指定的顺序)
- 将外连接转化为内连接
- 使用等价变换规则,合并和减少一些比较。
- 优化count min max
- 预估并转化为常数表达式。
- 覆盖索引扫描
- 子查询优化
- 提前终止查询。例如limit
- 等值传播
- 列表in()的比较。在MySQL中不等同于多个or条件,而是先将in中的数据先排序,然后通过二分查找来确定值是否满足条件。
优化器局限性 - in中有子查询如
select * from A where id in(select id from B)。性能很糟,不建议使用
MySQL关联查询 - 对任何关联都执行嵌套循环关联操作。
- 遇到子查询时,先执行并将结果放在临时表中;遇到右外连接时,会先改成等价的左外连接,故不能使用全外连接。
- MySQL不会生成查询字节码来执行,而是生成查询的一颗指令树,通过存储引擎执行并返回结果。
- 排序优化。排序是一个成本很高的操作,尽量避免。MySQL排序算法:单次传输排序(先读取查询所需要的所有列,再根据给定列排序,最后直接返回结果),再查询到第一条数据时就开始逐步返回。
- 对于关联子查询,尽可能使用左外连接代替。当然当返回结果只有一个表中的某些列的时候,关联查询会有重复结果集需要使用distinct,通常会产生中间表,这时候子查询可能更好。
- 最大值和最小值,mysql会做全表扫描。
- 在同一个表上查询和更新
需求;查询tab表的总记录,并设置到id=4的col字段中
//错误写法
UPDATE tab set col=(
select count(*) from lawyer_mediation
)
where id=4
//正确方法
update tab INNER JOIN(
select count(*) cnt from tab
) as der
set tab .col=der.cnt
where id =4优化count()
- count(*)用来行数,count(column)统计该列(值非空)数量。
- 当没有where时使用count(*)会非常快。
- 简单优化–
1.需求如查找统计id>5的记录
//优化前
select count(*)from city where id>5;
//优化后,先查询小于等于5,再相减
select (select count(*) from city) - count(*) from city where id<=52.同一个查询中统计同一列的不同值的数量
//统计tab表中color为蓝和红的数量
select count(color='blue' or null)as blue,count(color='red' or null) as red from tab;3.更复杂的应该考虑增加汇总表
优化关联查询
1.确保on或者using字句中列上有索引,ON子句的语法格式为:table1.column_name = table2.column_name。
当当两个表采用了相同的命名列时,就可以使用 USING 来简化,格式为:USING(column_name)。
2.确保任何的group by 和order by的表达式只涉及到一个表中的列。
3.如果需要对关联查询做分组,并且按照表中的某个列分组,那么通常采用查找表的标识发列分组效率更高。select a ,count(*) from tab ... group by id
优化limit分页
需求:对于偏移量很大的查询如limit 1000,10。会抛弃前面的大量记录会被抛弃,就需要优化.
-- 需要优化的sql
select id ,name from user order by phone limit 50,5方案一:延迟关联
select lim.id ,name
from user INNER JOIN(
select id from user order by phone limit 50,5
)as lim using(id)分析:这里的延迟关联将大大提升查询效率,让MySQL扫描尽可能少的页面,获取需要访问的记录后再根据关联列回原表查询需要的所有列,也可以用于优化关联查询中的分页。
方案二:转换为已知位置查询
select id,name from user where position between 50 and 54 order by position;分析:前提能够转换,该列上有索引,并且计算边界值,扫描更少的记录。
方案三:向前翻页
select id,name from user where id<10040 order by id desc limit 5分析:前提是id主键是单调增长的。好处就是无论怎样往后翻页,性能都很好。
实际问题优化
需求:计算两点之间的距离,如附近的人,附近的服务等功能。现有表tab和属性name,lat纬度,lon经度。
-- 计算公式
ACOS(
COS(latA)*COS(latB)*COS(lonA-lonB)
+SIN(latA)*SIN(latB)
)这算是一个比较精确的计算公式了,但实际上没有必要,不仅消耗cup而且无法使用索引
优化:在表中添加两个列,lat_floor和lon_floor作为范围的近似值,并且在程序中计算出指定范围内的所有点的范围(经度,纬度的最大值和最小值)
如计算结果为
--------------------------------------------------
fl_lat | ce_lat | fl_lon | ce_lon
--------------------------------------------------
36 | 40 | -80 | -77
--------------------------------------------------通过范围来生成in()列表,作为where的字句
--不精确的查询
select * from tab
where lat between 38.03 - degrees(0.02) and 38.03 + degrees(0.02)
and lon between 78.48 - degrees(0.02) and 78.48 + degrees(0.02)
and lat_floor in(36,37,38,39,40) and lon_floor in(-80,-79,-78,-77)当然,也可以使用前面的圆周公式精确计算,因为过滤了大量的数据,所有速度会很快。
3959是地球半径,radians是弧度
-- 根据毕达哥拉斯定理计算
select * from tab
where lat_floor in(36,37,38,39,40) and lon_floor in(-80,-79,-78,-77)
and 3959*ACOS(
COS(RADIANS(lat)) * COS(RADIANS(38.03) * COS(RADIANS(lon)-RADIANS(-78.48))
+SIN(RADIANS(lat)) * SIN(RADIANS(38.03))
)<=100优化建议
1.限制结果集(行和列)
2.避免全表扫描,主要有在where子句中使用!= > <操作符,使用xx is null语句(使用默认值代替),使用or链接如...where a=1 or a=2 替换为...where a=1 union all ...where a=2;前置%,如...like '%a%';in 和not in(如果是连续的数值,可以用between and代替);在where中使用表达式操作,..where num/2=100,可替换为num=100*2;在where子句中使用函数操作;
3.使用exists代替in
select n from a where n in(select n from b)替换为select n from a where exists(select 1 from b where n=a.n)
4.尽量使用数字型字段,在比较的时候只比较一次。