【机器学习】从RNN到Attention 下篇 Transformer与Self-Attention
在上一篇【机器学习】从RNN到Attention 中篇 从Seq2Seq到Attention in Seq2Seq中我们介绍了基于RNN结构的Attention机制,Attention机制通过encoder和注意力权重可以观察到全局信息,从而较好地解决了长期依赖的问题,但是RNN的结构本身的输入依赖于前一时刻模型的输出,因此无法并行化。既然Attention机制本身就具有捕捉全局信息的能力,那么我们是否可以抛开RNN结构,只使用Attention机制,从而既能捕捉全局信息,又能并行化呢?Transformer模型就使用了这样一种思路。
从一个例子看Self-Attention
Self-Attention的核心在于学习序列中其他部分对于该部分的权重值,比如
The animal didn't cross the street because it was too tired
其中的“it”代指的是 the street还是The animal呢?self-attention的神奇之处在于可以让模型更关注于The animal,以便更好地解读句子的含义,如下图所示

模型的整体结构
Transformer本质上是一个encoder-decoder的结构,如下图所示:
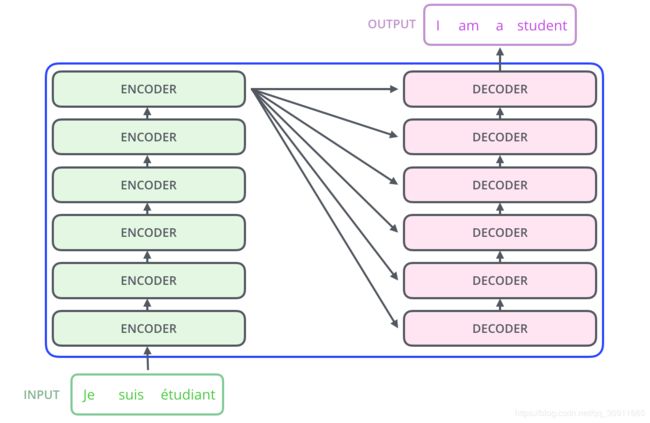
如上图,图左的encoder部分由6个相同的子encoder组成,图右的encoder部分也是由6个相同的子decoder组成。
其中的6个子encoder包含self-attention和FFN(前馈神经网络)两部分,6个子decoder包含self-attention,Encoder-Decoder Attention和FFN三部分。如下图所示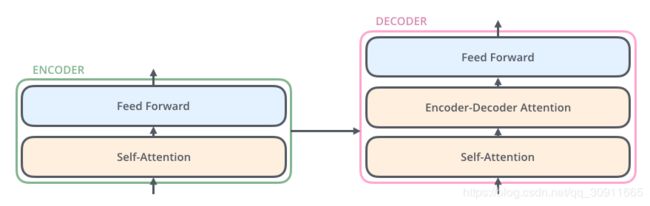
Self-Attention结构
我们先来看self-attention部分
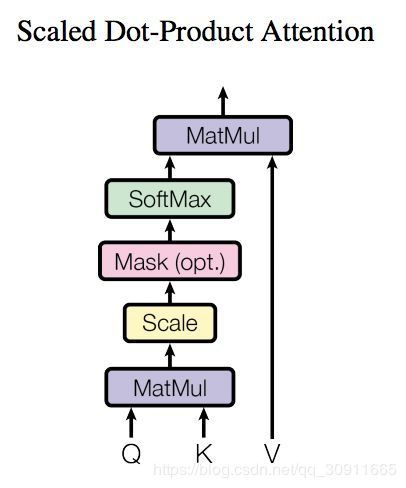
self-attention主要由三个矩阵Q,K,V构成,Q(Query), K(Key), V(Value)三个矩阵均来自于输入X

图中的 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV为模型参数,可以通过优化算法学习得到,输入X与 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV进行矩阵乘法后得到矩阵Q(Query), K(Key), V(Value),三者经过Attention操作后得到注意力矩阵,公式为 Z = A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Z=Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Z=Attention(Q,K,V)=softmax(dkQKT)V

有点复杂,我们来看一个例子,假如要翻译一个词组Thinking Machines,其中用 x 1 x_1 x1 表示Thinking的输入的embedding vector,用 x 2 x_2 x2表示Machines的embedding vector。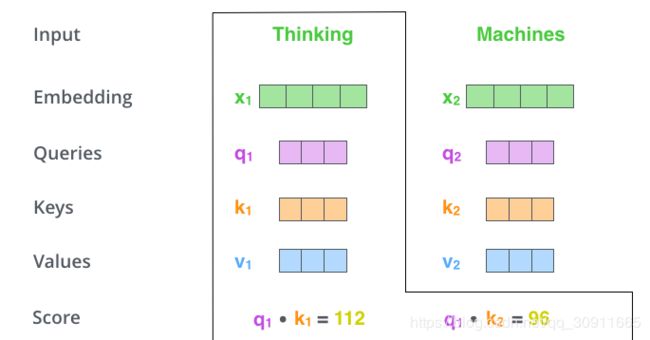
我们来计算Thinking这个词与其他词的Attention Score,Attention Score的物理含义就是将当前的词(Thinking)作为搜索的query,来表示和句子中包含自身在内的所有词(key)的相关性,如上图中的q1k1和q1k2分别表示Thinking与Thinking自身的相关性以及Thinking与Machines的相关性,当前单词与其自身的attention score最大,其他单词与当前单词相关性通过attention score。然后我们在用这些attention score与value vector相乘,得到加权的向量。
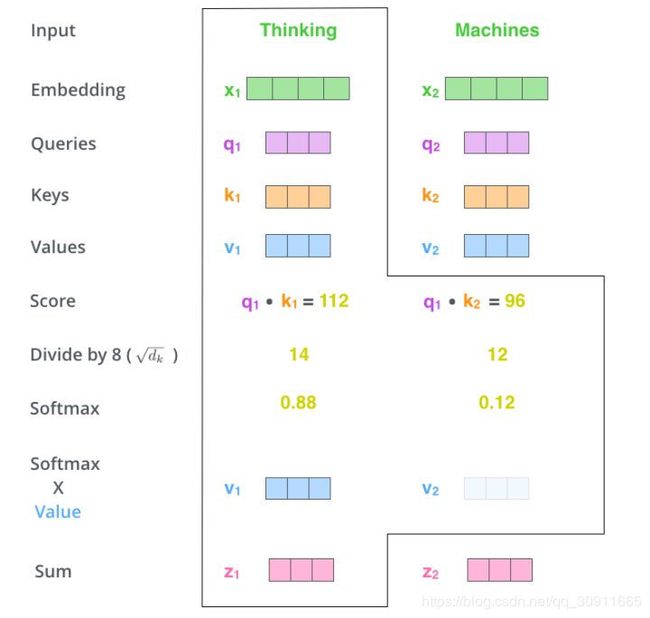 d k \sqrt{d_k} dk的作用在于放缩,从上例看112和96如果不做放缩直接进行softmax,则Thinking与Machines的Attention Score趋近于0,放缩后则略平衡一些。之所以选择 d k \sqrt{d_k} dk是基于假设:如果q和k的每一维满足均值0,方差1的随机变量,则它们的点乘 q ⋅ k = ∑ q i k i q\cdot k=\sum q_ik_i q⋅k=∑qiki满足均值为0,方差为 d k d_k dk,除以它相当于对数据做标准化。
d k \sqrt{d_k} dk的作用在于放缩,从上例看112和96如果不做放缩直接进行softmax,则Thinking与Machines的Attention Score趋近于0,放缩后则略平衡一些。之所以选择 d k \sqrt{d_k} dk是基于假设:如果q和k的每一维满足均值0,方差1的随机变量,则它们的点乘 q ⋅ k = ∑ q i k i q\cdot k=\sum q_ik_i q⋅k=∑qiki满足均值为0,方差为 d k d_k dk,除以它相当于对数据做标准化。
源码表示如下:
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
注意这里其实是可以带dropout层的,而masked_fill的作用在于让我们在decoder中,只能关注到到当前单词之前的、已经翻译过的输出的单词,当前单词之后的单词则不被关注到。
FFN(前向传播网络)结构
self-attention的输出后接入的是一个FFN(前向传播网络)结构,如下图所示

F F N ( x ) = m a x ( 0 , x W 0 + b 0 ) W 1 + b 1 FFN(x)=max(0,xW_0+b_0)W_1+b_1 FFN(x)=max(0,xW0+b0)W1+b1
先经过一个relu然后再过一个线性加权,可以看到无论是self-attention还是FFN都不再依赖于前一时刻的输入,因此transformer的整个计算过程是可以并行的。
源码表示如下
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
同样,这里可以带dropout操作
Multihead attention结构
所谓Multihead attention结构就是同一输入对应的self-attention层具有多个Q,K,V的组合,如下图所示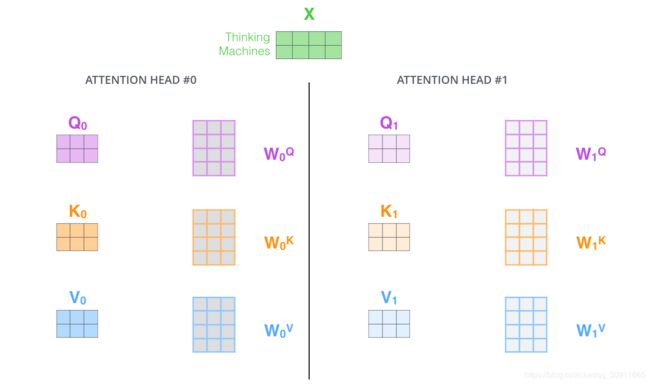
Multihead attention结构的主要作用在于:提高了模型的表达能力,一组Q,K,V可以只捕捉句中单词的一组相关关系,也就是“表达子空间”,多组Q,K,V则可以捕捉句中单词的多组相关关系。在一层self-attention中共有八组Q,K,V,经过计算得到的 z 1 , z 2 , . . . , z 7 z_1,z_2,...,z_7 z1,z2,...,z7,显然,这个计算过程也是可以并行的。

那么问题来了,下一层FFN并不能直接处理8个矩阵输入,而是需要一个矩阵,这8组z该如何处理呢?答案是将它们链接(concat)起来后,再送入FFN,如下图所示

根据上面“The animal didn’t cross the street because it was too tired”的例子,此时的Multihead结构可以捕捉到单词间的如下关系

位置编码
从上面的介绍我们发现transformer可以取代RNN结构并且可以进行并行计算,但却丢失了句子之前的顺序关系,为了解决这个问题,引入了位置编码(Position Encoding)。如下图所示
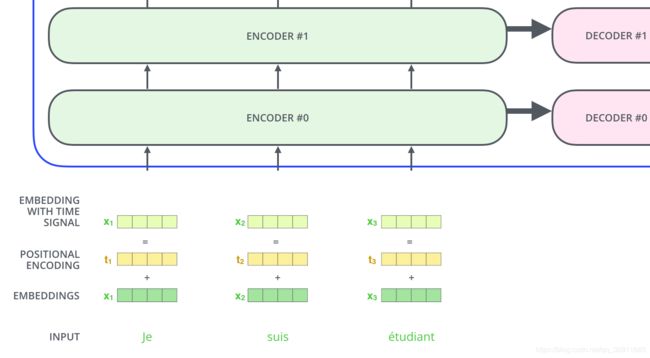
假设位置变量有4维,则位置编码的过程为:
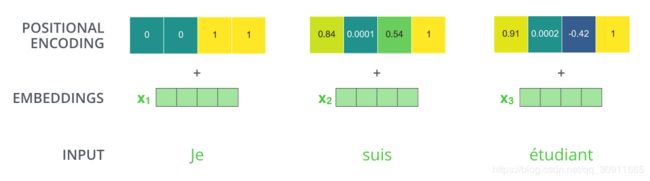
具体的计算公式为
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)}=sin(pos/10000^{2i/dmodel}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)}=cos(pos/10000^{2i/dmodel}) PE(pos,2i)=cos(pos/100002i/dmodel)
设计的思想是考虑的单词的的绝对位置和相对位置,大意和 s i n ( α + β ) = s i n α c o s β + s i n β c o s α sin(\alpha+\beta)=sin\alpha cos\beta+sin\beta cos\alpha sin(α+β)=sinαcosβ+sinβcosα和 c o s ( α + β ) = c o s α c o s β − s i n β s i n α cos(\alpha+\beta)=cos\alpha cos\beta-sin\beta sin\alpha cos(α+β)=cosαcosβ−sinβsinα这两个公式有关,具体为什么笔者没有深究,大家有兴趣可以了解下。
残差结构与层归一化
一个完整的encoder结构还包含两个残差结构(residual)和一层层归一化(layer norm),代码表示如下
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
可以发现其中的残差结构 x + self.dropout(sublayer(self.norm(x))),如下图所示
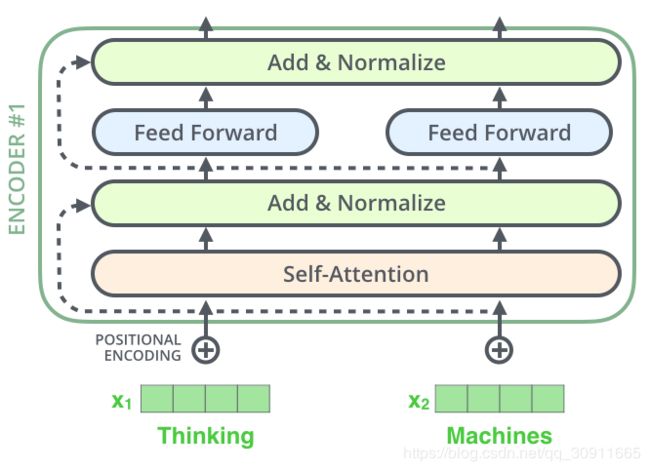

这种层结构在decoder中同样存在,以一个两层的encoder和decoder为例,如图所示
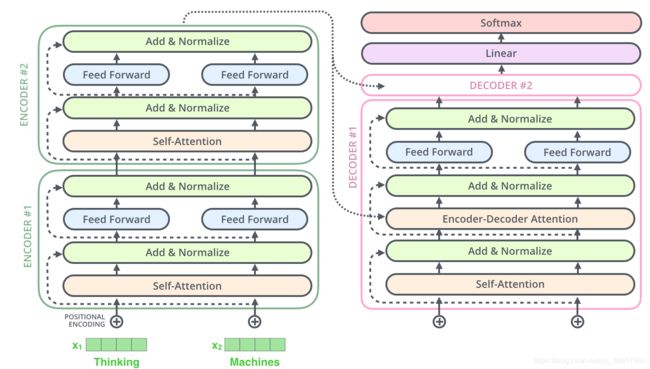
我们可以发现相比较于encoder,decoder中还包含了一个encoder-decoder attention结构。
decoder结构
从上一张图我们可以看到,相比较于encoder层已有的Self-Attention模块、前馈网络(FFN)模块、残差结构和归一化部分,decoder层多了一个Encoder-Decoder Attention模块,那么这个模块是怎么构成的呢?
我们先来看一个整个模型的输入输出过程
我们从图中可以看到,encoder的输出在decoder中是作为K,V而存在的,这就是decoder中encoder-decoder层的来源:decoder前一层的输入作为当前层的Query,而Key和Value则来源于encoder层的输出。代码表示如下:
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
注意代码中的memory就是指encoder层的输出,在decoder层中self.src_attn的参数分别为Q,K,V,mask,mask的作用我们在self-attention结构中有提及过,它的存在是为了使网络只能获取到当前时刻之前的输入,即只对当前时刻 t 之前的时刻输入进行attention计算。
我们从代码中可以看出:
- 在decoder层的传播过程中,输入x先经过self-attention操作得到一个中间变量x
- encoder-decoder层同样是一个self-attention结构,以Q,K,V为输入
- 中间变量x作为encoder-decoder层中的Query变量,而Key和Value则来源于encoder层的输出memory,最后经过FFN计算得到decoder层的输出。
总结
- Transormer结构是以self-attention结构作为基础,self-attention结构主要由Q,K,V三个输入,Self-Attention的核心在于学习序列中其他部分对于该部分的权重值
- encoder最顶层的输入是embedding得到的向量X,X通过 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv三个得到Q,K,V,之后经过Attention操作后得到注意力矩阵
Z = A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Z=Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Z=Attention(Q,K,V)=softmax(dkQKT)V , d k \sqrt{d_k} dk的作用在于放缩 - Multihead attention结构的主要作用在于:提高了模型的表达能力,一组Q,K,V可以只捕捉句中单词的一组相关关系,也就是“表达子空间”,多组Q,K,V则可以捕捉句中单词的多组相关关系,并且这种计算是可以并行加速的。
- 残差结构、FFN层和layer-Norm稍微关注一下~
- 基于上述结构的self-attention表达能力强、可以并行,但是丢失了位置信息,位置编码部分弥补了这一缺点,但这种方式是否可以改进值得商榷
- decoder相比于encoder层,多了一个 encoder-decoder,它同样是一个self-attention结构,以Q,K,V为输入,Key和Value来源于encoder层的输出,而Query则来源于self-attention层的输出。
最后大家可以欣赏一下transformer在翻译任务的整个操作过程。
参考资料:
模型部分:http://jalammar.github.io/illustrated-transformer/
代码部分:http://nlp.seas.harvard.edu/2018/04/03/attention.html#position-wise-feed-forward-networks