【手把手AI项目】六、Caffe实现MobileNetSSD以及各个文件的具体解释,利用自己的数据集dataset训练MobileNetSSD建立模型
前提
- 安装win10+linux-Ubuntu16.04的双系统(超细致)
- ubuntu16.04+caffe+CUDA10.0+cudnn7.4+opencv2.4.9.1+python2.7 (超超细致)
- Caffe_ssd安装以及利用VOC2012,VOC2007数据集测试VGG_SSD网络
全部搞定来接下来的步骤
一、下载MobileNetSSD,测试demo
1.下载以及大致说明文件包含内容
$ git clone https://github.com/chuanqi305/MobileNet-SSD.git
把下载的MobileNetssd包放在caffe/examples/中
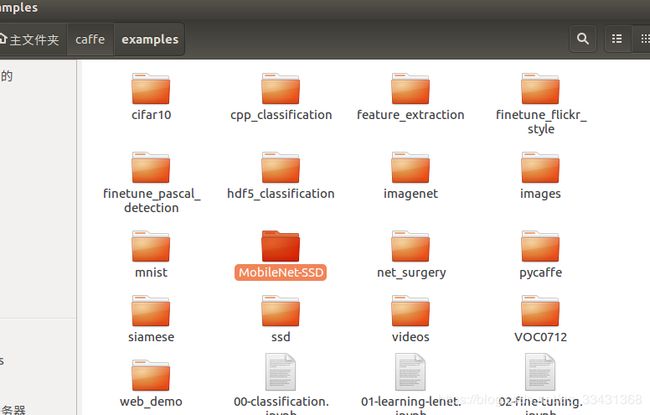
文件中的各个文件
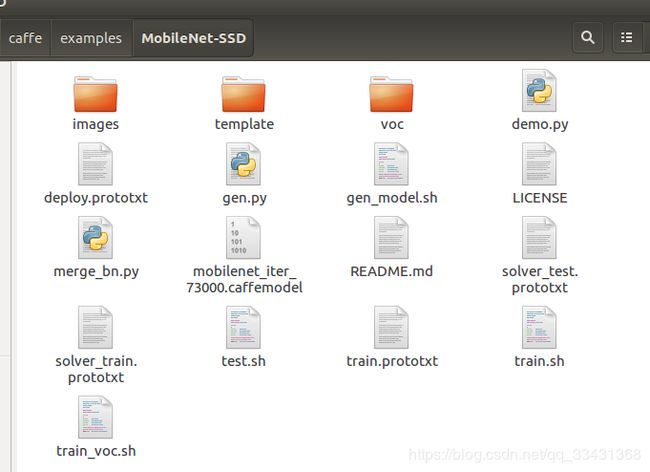
- images 测试图片所存放位置
- template 存放网络定义的公用模板train/test/deploy.protoxt,由gen.py脚本修改并生成,主要是因为label个数不一样所以这里的网络结构的前面几层和后面几层少许不同,这个需要我们后续训练自己数据集的时候利用gen_model.sh脚本生成。
- voc 存有三个根据VOC数据集生成的网络文件和一个网络超参数train文件
- demo.py 实际检测脚本(图片存于images文件夹)只针对单张图片,做成视频就是一帧帧图片遍历
- deploy.prototxt 运行网络定义文件,demo.py中调用.
-(和template/MobileNetSSD_deploy_template.prototxt相似) - gen.py 生成公用模板脚本(没有用到)
- gen_model.sh 生成自定义网络脚本---生成template中类似的文件(训练自己的数据集时需要用到)
- merge_bn.py 合并bn层脚本,用于生成最终的caffemodel(因为mobilenet有两个层最后需要合并才能得到deploy.caffemodel)
- mobilenet_iter_73000.caffemodel 预训练模型
- solver_test.prototxt 网络测试超参数定义文件
- solver_train.prototxt 网络训练超参数定义文件
- test.sh 网络测试脚本
- train.sh 网络训练脚本
- train.prototxt 训练网络定义文件 和template中的train定义网络文件相似
- train_voc.sh 针对voc文件里的超参数文件和网络文件的训练脚本
2.测试demo
下载训练好的model,testmodel一下 依然需要外网才可以
deploy_model网址如下:
https://drive.google.com/file/d/0B3gersZ2cHIxRm5PMWRoTkdHdHc/view
下载好放的MobileNetSSD_deploy.caffemodel放到MobileNetSSD文件中即可
修改demo.py文件中的路径

文件中的deploy.prototxt网络和这个caffemodel应该不是一致的所以需要再下载一个
MobileNetSSD_deploy.prototxt 下载在 https://download.csdn.net/download/qq_33431368/10850770
import numpy as np
import sys,os
import cv2
caffe_root = '/home/che/caffe/'
sys.path.insert(0, caffe_root + 'python')
import caffe
net_file= 'MobileNetSSD_deploy.prototxt'
caffe_model='MobileNetSSD_deploy.caffemodel'
test_dir = "images"
执行python文件
cd caffe/examples/MobileNet-SSD
python demo.py
显示结果


二、参数文件和网络文件的详细说明
1.solver_train.prototxt(和solver_test.prototxt类似)
train_net: "example/MobileNetSSD_train.prototxt" #训练的网络由gen_model.sh脚本生成
test_net: "example/MobileNetSSD_test.prototxt" #测试网络由gen_model.sh脚本生成
test_iter: 673 #等于测试集图片数量/batchsize
test_interval: 10000
base_lr: 0.0005 # 基本学习率
display: 10 # 10步显示一次相当于10步print一次
max_iter: 120000 # 总共的迭代步数
lr_policy: "multistep" # 下降的学习率的下降方式
gamma: 0.5 #
weight_decay: 0.00005 #
snapshot: 1000 #每次迭代1000步之后产生一个当前的caffemodel和状态文件,存入于snapshot文件夹中
snapshot_prefix: "snapshot/mobilenet"
solver_mode: GPU #GPU训练方式
debug_info: false
snapshot_after_train: true #训练的时候是否存入中间模型,如果为false,则snapshot没有用处了
test_initialization: false
average_loss: 10
stepvalue: 20000 #呼应于lr的下降方式而设定的,迭代多少步设定再下降
stepvalue: 40000 #呼应于lr的下降方式而设定的,再迭代多少步设定再下降
iter_size: 1
type: "RMSProp" #优化算法
eval_type: "detection" #评估方式为目标检测
ap_version: "11point"
2.MobileNetSSD_train_template.prototxt 网络定义文件(test和deploy类似)
截取一段 进行说明 其他以此列推
name: "MobileNet-SSD"
#训练的网络输入层
layer {
name: "data"
type: "AnnotatedData" #输入数据类型
top: "data"
top: "label"
include {
phase: TRAIN #训练层
}
#相当于数据预处理层
transform_param {
#以下0.007834和127.5为图片归一化处理,这个很关键(后面移植和显示等操作都需要和这个对应)
scale: 0.007843
mirror: true
mean_value: 127.5
mean_value: 127.5
mean_value: 127.5
#图片resize操作 300*300 (这个直接影响速度和精度,一般分辨率越小速度越快,但是精度也随之下降)
resize_param {
prob: 1.0
resize_mode: WARP
height: 300
width: 300
interp_mode: LINEAR
interp_mode: AREA
interp_mode: NEAREST
interp_mode: CUBIC
interp_mode: LANCZOS4
}
emit_constraint {
emit_type: CENTER
}
distort_param {
brightness_prob: 0.5
brightness_delta: 32.0
contrast_prob: 0.5
contrast_lower: 0.5
contrast_upper: 1.5
hue_prob: 0.5
hue_delta: 18.0
saturation_prob: 0.5
saturation_lower: 0.5
saturation_upper: 1.5
random_order_prob: 0.0
}
expand_param {
prob: 0.5
max_expand_ratio: 4.0
}
}
#输入数据来源和格式lmdb格式
data_param {
source: "trainval_lmdb/"
batch_size: 24
backend: LMDB
}
annotated_data_param {
batch_sampler {
max_sample: 1
max_trials: 1
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.1
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.3
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.5
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.7
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.9
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
max_jaccard_overlap: 1.0
}
max_sample: 1
max_trials: 50
}
label_map_file: "labelmap.prototxt"
}
}
##这才刚刚开始Mobilenet网络第一层
layer {
name: "conv0"
type: "Convolution" # 卷积层
bottom: "data"
top: "conv0"
param {
lr_mult: 0.1 # 学习率
decay_mult: 0.1
}
convolution_param {
num_output: 32 #卷积核的个数
bias_term: false
pad: 1 #卷积核是否补全
kernel_size: 3 #卷积核的大小
stride: 2 #卷积核的步数
weight_filler {
type: "msra" #卷积核权值初始化方法
}
}
}
#bn层
layer {
name: "conv0/bn"
type: "BatchNorm"
bottom: "conv0"
top: "conv0"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
}
##scale层
layer {
name: "conv0/scale"
type: "Scale"
bottom: "conv0"
top: "conv0"
param {
lr_mult: 0.1
decay_mult: 0.0
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
scale_param {
filler {
value: 1
}
bias_term: true
bias_filler {
value: 0
}
}
}
#激活函数层,一般是卷积层之后加一个Relu激活函数层
layer {
name: "conv0/relu"
type: "ReLU"
bottom: "conv0"
top: "conv0"
}
3.train.sh文件 / test.sh文件
train
#!/bin/sh
##判断网络结构文件是否存在 这里需要修改成 此时 数据集对应的网络文件(gen_model生成)
if ! test -f example/MobileNetSSD_train.prototxt ;then
echo "error: example/MobileNetSSD_train.prototxt does not exist."
echo "please use the gen_model.sh to generate your own model."
exit 1
fi
mkdir -p snapshot
../../build/tools/caffe train -solver="solver_train.prototxt" \ ##训练超参数用的时候这里可能需要更改
-weights="mobilenet_iter_73000.caffemodel" \ ##预训练模型可能需要更改
-gpu 0
test
#!/bin/sh
#latest=snapshot/mobilenet_iter_73000.caffemodel
##定义latest为snapshot(存放模型的文件)中的最后生成的一个即训练完merge_bn的deploy.caffemodel
latest=$(ls -t snapshot/*.caffemodel | head -n 1)
if test -z $latest; then
exit 1
fi
../../build/tools/caffe train -solver="solver_test.prototxt" \
--weights=$latest \ ##用的时候直接改成你要test的caffemodel也可以
-gpu 0
4. demo.py文件 这个文件以后需要按照自己的要求更改(例如修改成视频的)
源文件的大致说明
##导入包
import numpy as np
import sys,os
import cv2
##这里需要修改 caffe的根目录
caffe_root = '/home/che/caffe/'
sys.path.insert(0, caffe_root + 'python')
import caffe
#网络文件 模型名称 测试图片文件夹 需要修改
net_file= 'MobileNetSSD_deploy.prototxt'
caffe_model='MobileNetSSD_deploy.caffemodel'
test_dir = "images"
##判断是否存在模型和网络文件
if not os.path.exists(caffe_model):
print(caffe_model + " does not exist")
exit()
if not os.path.exists(net_file):
print(net_file + " does not exist")
exit()
##生成网络
net = caffe.Net(net_file,caffe_model,caffe.TEST)
##类别定义
CLASSES = ('background',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
##图片预处理,即归一化,resize 的300以及减去的127.5以及乘上的0.007834都和上面网络文件相对应一致
def preprocess(src):
img = cv2.resize(src, (300,300))
img = img - 127.5
img = img * 0.007843
return img
##网络输出的整理
def postprocess(img, out):
h = img.shape[0]
w = img.shape[1]
box = out['detection_out'][0,0,:,3:7] * np.array([w, h, w, h])
cls = out['detection_out'][0,0,:,1]
conf = out['detection_out'][0,0,:,2]
return (box.astype(np.int32), conf, cls)
##主函数 目标检测
def detect(imgfile):
origimg = cv2.imread(imgfile)
img = preprocess(origimg)
img = img.astype(np.float32)
img = img.transpose((2, 0, 1))
net.blobs['data'].data[...] = img
out = net.forward() ## 前向推理
box, conf, cls = postprocess(origimg, out)##产生box为边框的值,conf为概率 cls为类别
##进行逐一画图标注产生最后的显示结果
for i in range(len(box)):
p1 = (box[i][0], box[i][1])
p2 = (box[i][2], box[i][3])
cv2.rectangle(origimg, p1, p2, (0,255,0)) ##画框
p3 = (max(p1[0], 15), max(p1[1], 15))
title = "%s:%.2f" % (CLASSES[int(cls[i])], conf[i])
cv2.putText(origimg, title, p3, cv2.FONT_ITALIC, 0.6, (0, 255, 0), 1) ##画标注
cv2.imshow("SSD", origimg)
k = cv2.waitKey(0) & 0xff
#Exit if ESC pressed
if k == 27 : return False
return True
for f in os.listdir(test_dir):
if detect(test_dir + "/" + f) == False:
break
三、利用自己的数据集训练自己的MobileNetSSD model
首选在caffe/data中新建一个MyDataSet文件夹,数据集最好都放到data中统一管理。
我的数据集是做项目时候已经做好了,这边就不公布了这里主要是讲一下流程
1.制作数据集具体做法请看我另一篇博文即可
自己制作图像VOC数据集–用于Objection Detection(目标检测)
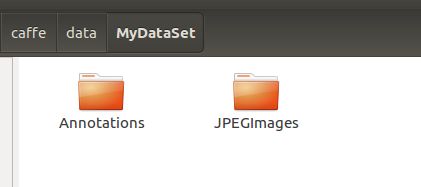
此时此刻你的MyDataSet中应该有以下两个文件,因为多生成的labels这边目标检测用不到所以没有拷贝进来,文件如下所示
- Annotations 利用标注软件 生成对应的xml文件
- JPEGImages 原始图片
2.生成索引txt文件
利用以下代码,生成ImageSet文件夹,此文件夹目录下包含Main文件下,在ImageSets\Main里有四个txt文件:test.txt train.txt trainval.txt val.txt; 分别是测试数据集索引(也就是各个测试图片的名称,相对路径)、训练数据集、训练验证数据集、验证数据集
创建CreateImageSets.py文件,代码如下,这里注释简单说明
import os
import random
trainval_percent = 0.9 #训练验证数据集占总共的数据集的多少
train_percent = 0.9 #训练数据集占trainval的多少
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
os.makedirs(txtsavepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv) #随机采取训练验证训练集集合
train=random.sample(trainval,tr)
#写文本
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
#写入每一个
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
#关闭
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
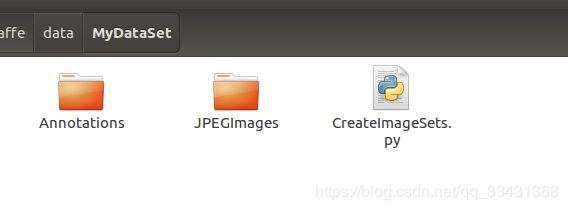
执行这个文件得到四个txt文件,结果如下:
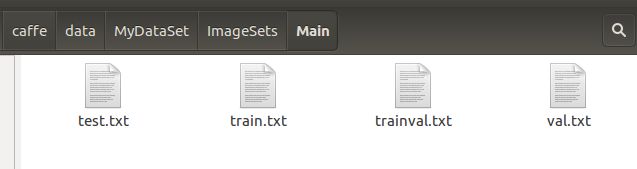
3.生成lmdb格式文件(caffe输入格式)
首先先把以下几个文件拷贝到MyDataSet中
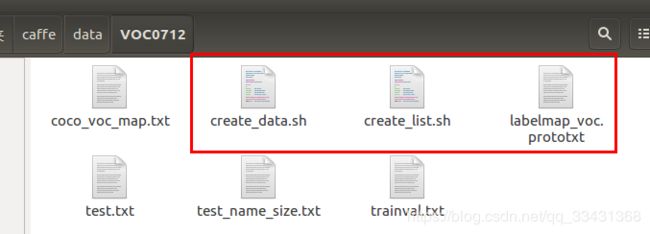
cd caffe/data
cp VOC0712/create_list.sh MyDataSet/
cp VOC0712/create_data.sh MyDataSet/
cp VOC0712/labelmap_voc.prototxt MyDataSet/
此时数据集的文件情况为
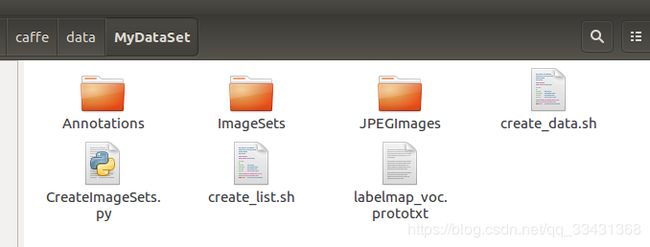 更改这三个文件
更改这三个文件
create_list.sh 更改为以下代码形式(已更改之后的)
cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
root_dir=$cur_dir/../..
cd $root_dir
redo=1
data_root_dir="$HOME/caffe/data" ## 更改你的路径
dataset_name="MyDataSet" ##更改你的dataset的名称
mapfile="$root_dir/data/$dataset_name/labelmap_voc.prototxt"
...............(这里不用改,省略)
done
create_data.sh更改为以下代码形式(已更改之后的)
#!/bin/bash
root_dir=$HOME/caffe/data ## 更改你的路径
sub_dir=ImageSets/Main
bash_dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
for dataset in trainval test
do
dst_file=$bash_dir/$dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in MyDataSet ##更改成你的dataset的名称
do
# if [[ $dataset == "test" && $name == "VOC2012" ]]
#then
# continue
#fi
echo "Create list for $name $dataset..."
..............(这里不用改,省略)
done
labelmap_voc.prototxt更改(仿照形式更改成自己的label) 以下举个例子两个label形式
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "cat"
label: 1
display_name: "cat"
}
item {
name: "dog"
label: 2
display_name: "dog"
}
item {
name: "bear"
label: 3
display_name: "bear"
}
依次执行(执行之前,把我所写的##注释最好都删掉,去掉)
cd caffe/data/MyDataSet
create_list.sh
create_data.sh
执行create_data.sh 提示如下所示

即可生成
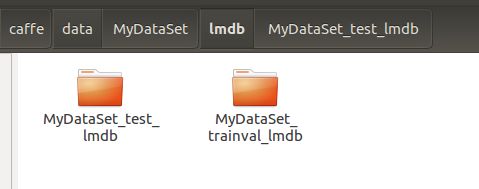
两个文件里都为lmdb文件
其次发现在examples中有个与MobileNetSSD平级的目录MyDataSet
里面为lmdb文件夹的超链接文件,后续训练使用。

4.利用MobileNetSSD进行训练
①首先在MobileNetSSD文件中建立自己的labelmap.prototxt(内容和上述labelmap_voc.prototxt一样)
②建立自己对应label个数的train/test/deploy网络文件
gen_model.sh 4 #4对应label 的个数,加上backgroud 就四个label
文件中生成一个example文件,里面就是所生成的网络定义文件

③建立数据集的超链接
ln -s PATH_TO_YOUR_TRAIN_LMDB trainval_lmdb
ln -s PATH_TO_YOUR_TEST_LMDB test_lmdb
以我的路径操作,在MobileNetSSD中执行上述两句命令
ln -s /home/che/caffe/data/MyDataSet/lmdb/MyDataSet_trainval_lmdb trainval_lmdb
ln -s /home/che/caffe/data/MyDataSet/lmdb/MyDataSet_test_lmdb test_lmdb
 则在MobileNetSSD下出现两个超链接文件
则在MobileNetSSD下出现两个超链接文件
 这一步也可以将上面在example中生成的MyDataSet文件里面的两个超链接全部复制到MobileNetSSD中去,并且将名字改成如上图所示的名称
这一步也可以将上面在example中生成的MyDataSet文件里面的两个超链接全部复制到MobileNetSSD中去,并且将名字改成如上图所示的名称
④修改超参数、指定预训练模型,开始model训练
按照自身要求修改solver_test.prototxt和solver_train.prototxt中的超参数
修改预训练模型
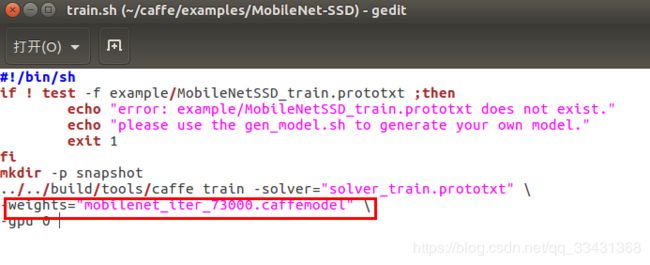 开始训练
开始训练
train.sh
可能出现以下错误
Check failed: mdb_status == 0 (2 vs. 0) No such file or directory
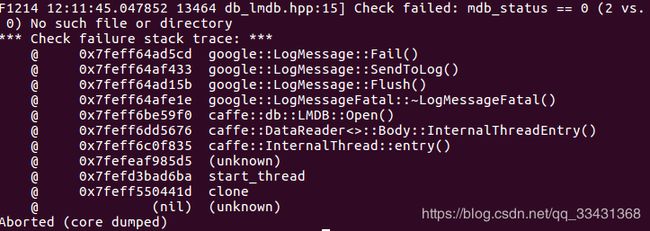
解决方案减小batchsize即可,因为GPU内存不够
重新run脚本成功
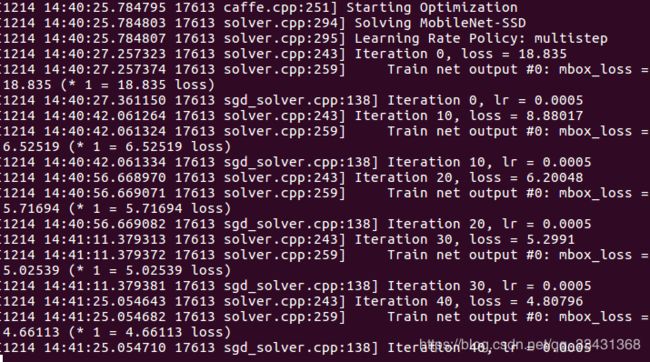
训练中途也可以不断调节参数,能看来随着迭代次数的增多loss正在减小,经过一段时间的训练,最后几万步之后loss差不多1.0上下浮动。
5.合并成最终的model,以及如何测试
差不多五万多步之后
文件中多了一个snapshot文件
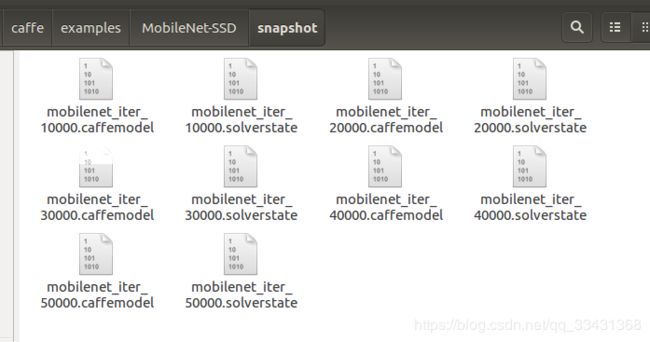
可以看出我们是按照每一万步生成一个caffemodel文件和一个实时训练状态文件这个就是solver.prototxt文件中可以进行设定
①合并出最终的caffemodel
因为MobileNet中有bn和scale层,最后生成deploy需要进行一步操作,此处运用merge_bn.py文件,需要作出以下修改(因为现在重新git clone的这个文件的代码已经改变,我还没有来得及看,或者说用上,这边我还是按我以前clone的代码来讲,大家可以复制粘贴以下使用)
merge_bn.py
import numpy as np
import sys,os
caffe_root = '/home/che/caffe/' ##改成你的路径即可
sys.path.insert(0, caffe_root + 'python')
import caffe
train_proto = 'example/MobileNetSSD_train.prototxt' ##改成你的训练网络 ,如果不做其他操作就是这个路径
train_model = 'snapshot/mobilenet_iter_50000.caffemodel' ##改成你想合并成deploy的caffemodel这里我想用我训练最后得到的跌倒5万步的
deploy_proto = 'example/MobileNetSSD_deploy.prototxt' ##改成你的deploy网络 如果不做其他操作就是这个路径
save_model = 'snapshot/MobileNetSSD_deploy.caffemodel' #最后生成最终的caffemodel的存入路径
#下面不需要改动,只需要改动路径即可
def merge_bn(net, nob):
'''
merge the batchnorm, scale layer weights to the conv layer, to improve the performance
var = var + scaleFacotr
rstd = 1. / sqrt(var + eps)
w = w * rstd * scale
b = (b - mean) * rstd * scale + shift
'''
for key in net.params.iterkeys():
if type(net.params[key]) is caffe._caffe.BlobVec:
if key.endswith("/bn") or key.endswith("/scale"):
continue
else:
conv = net.params[key]
if not net.params.has_key(key + "/bn"):
for i, w in enumerate(conv):
nob.params[key][i].data[...] = w.data
else:
bn = net.params[key + "/bn"]
scale = net.params[key + "/scale"]
wt = conv[0].data
channels = wt.shape[0]
bias = np.zeros(wt.shape[0])
if len(conv) > 1:
bias = conv[1].data
mean = bn[0].data
var = bn[1].data
scalef = bn[2].data
scales = scale[0].data
shift = scale[1].data
if scalef != 0:
scalef = 1. / scalef
mean = mean * scalef
var = var * scalef
rstd = 1. / np.sqrt(var + 1e-5)
rstd1 = rstd.reshape((channels,1,1,1))
scales1 = scales.reshape((channels,1,1,1))
wt = wt * rstd1 * scales1
bias = (bias - mean) * rstd * scales + shift
nob.params[key][0].data[...] = wt
nob.params[key][1].data[...] = bias
net = caffe.Net(train_proto, train_model, caffe.TRAIN)
net_deploy = caffe.Net(deploy_proto, caffe.TEST)
merge_bn(net, net_deploy)
net_deploy.save(save_model)
python merge_bn.py
在snapshot中可以发现一个MobileNetSSD_deploy.caffemodel
②对于caffemodel进行test
将测试图片放到image中
对demo.py中的路径和文件名进行修改执行demo.py即可
这里就不演示了,因为数据集保密
也可以利用test.sh进行测试以下总体的acc
这里可能需要修改下solver_test.prototxt文件中的对应路径
例如这个地方solver_train.prototxt文件中的路径默认为example/ 而solver_test没有需要自行修改为以下形式
train_net: "example/MobileNetSSD_train.prototxt"
test_net: "example/MobileNetSSD_test.prototxt"
执行脚本
test.sh
执行测试py文件(根据demo.py进行更改)
OVER
Reference
https://blog.csdn.net/yu734390853/article/details/79481660
https://blog.csdn.net/zhang_shuai12/article/details/52346878
https://blog.csdn.net/Jesse_Mx/article/details/78680055
Batchnorm层:
https://blog.csdn.net/qq_25737169/article/details/79048516
https://blog.csdn.net/wangkun1340378/article/details/77161243
np.transpose用法
https://blog.csdn.net/xiongchengluo1129/article/details/79017142
卷积核
https://zm8.sm-tc.cn/?src=l4uLj4zF0NCIiIjRnJGdk5CYjNGckJLQporSuZqWuZqW0J6Ni5ack5qM0MnHz8%2FKzsbRl4uSkw%3D%3D&uid=6ddd1a57ac6d39a2fd15083871fed492&hid=99f3e47feb675bdd11f130781b4670e3&pos=4&cid=9&time=1539675448322&from=click&restype=1&pagetype=0020004002000402&bu=ss_doc&query=%E5%8D%B7%E7%A7%AF%E6%A0%B8&mode=&v=1&force=true&wap=false&uc_param_str=dnntnwvepffrgibijbprsvdsdichei