如何在Kubernetes上玩转TensorFlow ?
女主宣言
该文章出自于ADDOPS团队,是关于如何在K8S上玩转tensorflow的主题,该文章深入浅出的给我们介绍了当前tensorflow的现状和架构特点等,然后介绍了让tensorflow如何基于k8s快速落地,让大家都能简单的上手tensorflow,整体文章脉络清晰,内容适度,所以希望能给大家带来启发。
PS:丰富的一线技术、多元化的表现形式,尽在“HULK一线技术杂谈”,点关注哦!
前言
Tensorflow作为深度学习领域逐渐成熟的项目,以其支持多种开发语言,支持多种异构平台,提供强大的算法模型,被越来越多的开发者使用。但在使用的过程中,尤其是GPU集群的时候,我们或多或少将面临以下问题:
- 资源隔离。Tensorflow(以下简称tf)中并没有租户的概念,何如在集群中建立租户的概念,做到资源的有效隔离成为比较重要的问题;
- 缺乏GPU调度。tf通过指定GPU的编号来实现GPU的调度,这样容易造成集群的GPU负载不均衡;
- 进程遗留问题。tf的分布式模式ps服务器会出现tf进程遗留问题;
- 训练的数据分发以及训练模型保存,都需要人工介入;
- 训练日志保存、查看不方便;
因此,我们需要一个集群调度和管理系统,可以解决GPU调度、资源隔离、统一的作业管理和跟踪等问题。
目前,社区中有多种开源项目可以解决类似的问题,比如yarn,kubernetes。yarn是hadoop生态中的资源管理系统,而kubernetes(以下简称k8s)作为Google开源的容器集群管理系统,在tf1.6版本加入GPU管理后,已经成为很好的tf任务的统一调度和管理系统。
下文是我们公司在tensorflow on kubernetes方面的实践经验。
设计目标
我们将tensorflow引入k8s,可以利用其本身的机制解决资源隔离,GPU调度以及进程遗留的问题。除此之外,我们还需要面临下面问题的挑战:
- 支持单机和分布式的tensorflow任务;
- 分布式的tf程序不再需要手动配置clusterspec信息,只需要指定worker和ps的数目,能自动生成clusterspec信息;
- 训练数据、训练模型以及日志不会因为容器销毁而丢失,可以统一保存;
为了解决上面的问题,我们开发了tensorflow on kubernetes系统。
架构
tensorflow on kubernetes包含三个主要的部分,分别是client、task和autospec模块。client模块负责接收用户创建任务的请求,并将任务发送给task模块。task模块根据任务的类型(单机模式和分布式模式)来确定接下来的流程:
如果type选择的是single(单机模式),对应的是tf中的单机任务,则按照按照用户提交的配额来启动container并完成最终的任务;
如果type选择的是distribute(分布式模式),对应的是tf的分布式任务,则按照分布式模式来执行任务。需要注意的是,在分布式模式中会涉及到生成clusterspec信息,autospec模块负责自动生成clusterspec信息,减少人工干预。
下面是tensorflow on kubernetes的架构图:

接下来将对三个模块进行重点介绍。
client模块
tshell
在容器中执行任务的时候,我们可以通过三种方式获取执行任务的代码和训练需要的数据:
- 将代码和数据做成新的镜像;
- 将代码和数据通过卷的形式挂载到容器中;
- 从存储系统中获取代码和数据;
前两种方式不太适合用户经常修改代码的场景,最后一种场景可以解决修改代码的问题,但是它也有下拉代码和数据需要时间的缺点。综合考虑后,我们采取第三种方式。
我们做了一个tshell客户端,方便用户将代码和程序进行打包和上传。比如给自己的任务起名字叫cifar10-multigpu,将代码打包放到code下面,将训练数据放到data下面。
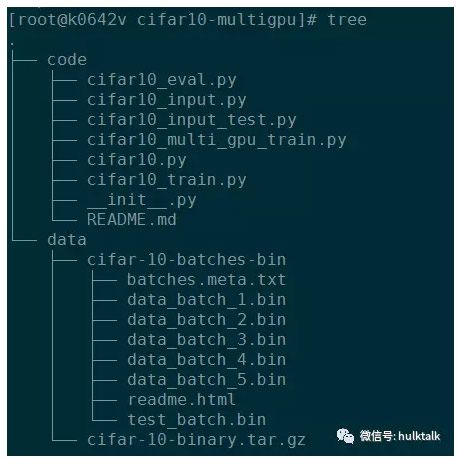
最后打包成cifar10-multigpu.tar.gz并上传到s3后,就可以提交任务。
提交任务
在提交任务的时候,需要指定提前预估一下执行任务需要的配额:cpu核数、内存大小以及gpu个数(默认不提供),当然也可以按照我们提供的初始配额来调度任务。
比如,按照下面格式来将配额信息、s3地址信息以及执行模式填好后,执行send_task.py我们就可以提交一次任务。
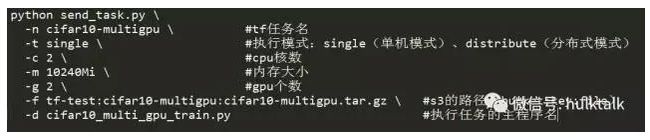 task模块
task模块
单机模式
对于单机模式,task模块的任务比较简单,直接调用python的client接口启动container。container里面主要做了两件事情,initcontainer负责从s3中下载事先上传好的文件,container负责启动tf任务,最后将日志和模型文件上传到s3里,完成一次tf单机任务。
分布式模式
对于分布式模式,情况要稍微复杂些。下面先简单介绍一下tensforlow分布式框架。tensorflow的分布式并行基于gRPC框架,client负责建立Session,将计算图的任务下发到TF cluster上。
TF cluster通过tf.train.ClusterSpec函数建立一个cluster,每个cluster包含若干个job。 job由好多个task组成,task分为两种,一种是PS(Parameter server),即参数服务器,用来保存共享的参数,还有一种是worker,负责计算任务。
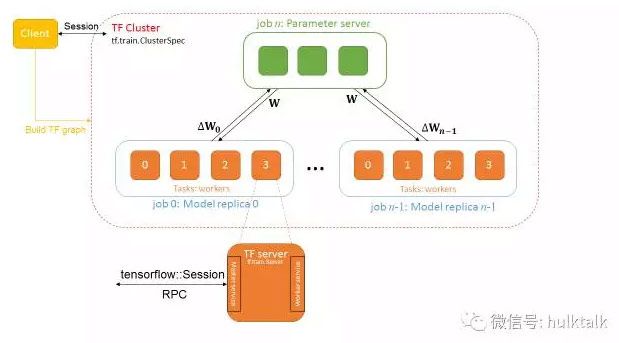
我们在执行分布式任务的时候,需要指定clusterspec信息,如下面的任务,执行该任务需要一个ps和两个worker,我们先需要手动配置ps和worker,才能开始任务。这样必然会带来麻烦。如何解决clusterspec,成为了一个必须要解决的问题。
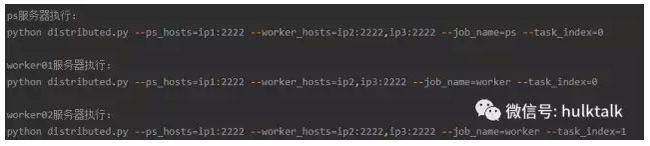
所以在提交分布式任务的时候,task需要autospec模块的帮助,收集container的ip后,才能真正启动任务。所以分布式模式要做两件事情:
- 按照yaml文件启动container;
- 通知am模块收集此次任务container的信息后生成clusterspec;
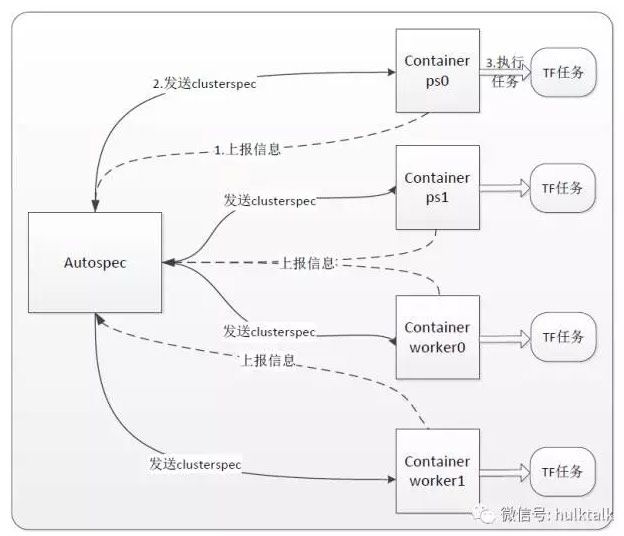
Autospec模块
tf分布式模式的node按照角色分为ps(负责收集参数信息)和worker,ps负责收集参数信息,worker执行任务,并定期将参数发送给worker。
要执行分布式任务,涉及到生成clusterspec信息,模型的情况下,clusterspec信息是通过手动配置,这种方式比较麻烦,而且不能实现自动化,我们引入autospec模型很好的解决此类问题。
Autospec模块只有一个用途,就是在执行分布式任务时,从container中收集ip和port信息后,生成clusterspec,发送给相应的container。下面是autospec模块的工作流程图:
Container设计
tf任务比较符合k8s中kind为job的任务,每次执行完成以后这个容器会被销毁。我们利用了此特征,将container都设置为job类型。
k8s中设计了一种hook:poststart负责在容器启动之前做一些初始化的工作,而prestop负责在容器销毁之前做一些备份之类的工作。
我们利用了此特点,在poststart做一些数据获取的工作,而在prestop阶段负责将训练产生的模型和日志进行保存。我们接下来分单机和分布式两种模式来说明Container的设计思想。
总结
至此,我们已经介绍了tensorflow on kubernetes的主要流程。还有许多需要完善的地方,比如:web端提交任务以及查看运行状况和作业的日志;支持GPU的亲和性等等,总之,这只是我们前期的探索,后面还有许多东西需要完善。