redis(8)-内部编码
Redis针对每种数据类型(type) 可以采用至少两种编码方式来实现。如下如图

注意3.2版本之后的redis list类型的数据内部都是通过quicklist实现的。
了解编码和类型对应关系之后, 我们不禁疑惑Redis为什么对一种数据结构实现多种编码方式?
主要原因是Redis作者想通过不同编码实现效率和空间的平衡。 比如当我们的存储只有10个元素的列表, 当使用双向链表数据结构时, 必然需要维护大量的内部字段如每个元素需要: 前置指针, 后置指针, 数据指针等, 造成空间浪费, 如果采用连续内存结构的压缩列表(ziplist) , 将会节省大量
内存, 而由于数据长度较小, 存取操作时间复杂度即使为O(n2) 性能也可满足需求。
编码类型转换在Redis写入数据时自动完成, 这个转换过程是不可逆的, 转换规则只能从小内存编码向大内存编码转换。其中Redis之所以不支持编码回退, 主要是数据增删频繁时, 数据向压缩编码转换非常消耗CPU, 得不偿失。 以上示例用到了list-max-ziplist-entries参数, 这个参数用来决定列表长度在多少范围内使用ziplist编码。 当然还有其他参数控制各种数据类型的编码,如下图。

掌握编码转换机制, 对我们通过编码来优化内存使用非常有帮助。 下面以hash类型为例, 介绍编码转换的运行流程。
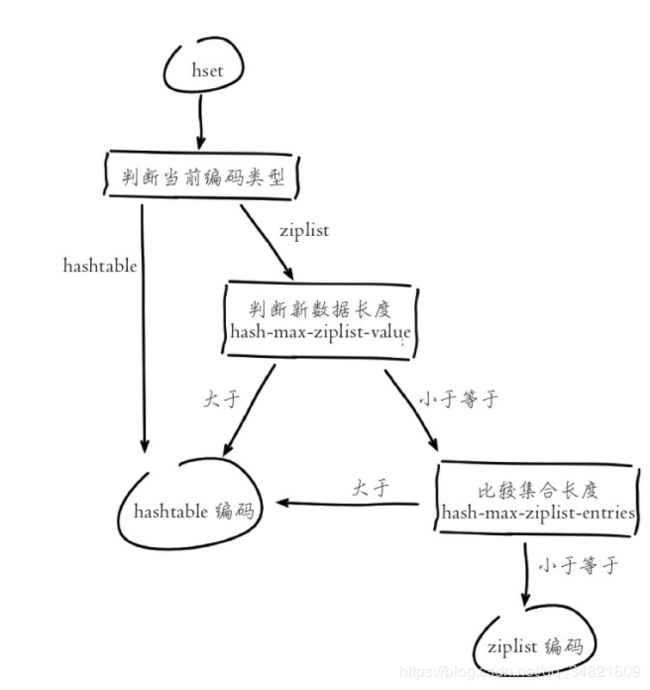
理解编码转换流程和相关配置之后, 可以使用config set命令设置编码相关参数来满足使用压缩编码的条件。 对于已经采用非压缩编码类型的数据如hashtable、 linkedlist等, 设置参数后即使数据满足压缩编码条件, Redis也不会做转换, 需要重启Redis重新加载数据才能完成转换。
下面将介绍着6中内部数据结构(sds,ziplist,hashtable,intset,skiplist,linkedlist)
1.sds
Redis没有采用原生C语言的字符串类型而是自己实现了字符串结构, 内部简单动态字符串(simple dynamic string, SDS)
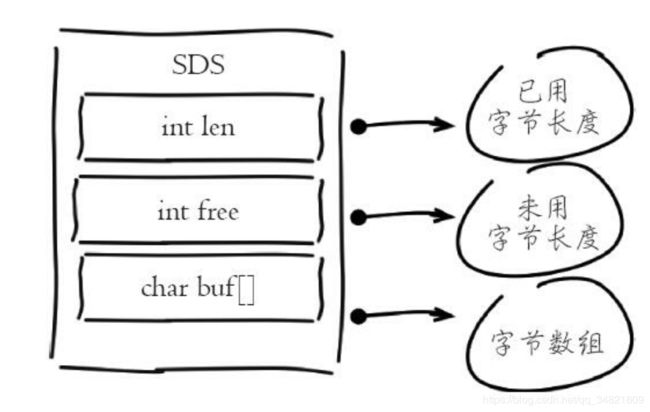
Redis自身实现的字符串结构有如下特点:
·O(1) 时间复杂度获取: 字符串长度、 已用长度、 未用长度。
·可用于保存字节数组, 支持安全的二进制数据存储。
·内部实现空间预分配机制, 降低内存再分配次数。
·惰性删除机制, 字符串缩减后的空间不释放, 作为预分配空间保留。
字符串对象的编码可以是 INT、RAW 或 EMBSTR,对于8个字节以下的int类型,采用INT方式,当字符串值得长度大于44字节使用RAW,小于等于44字节使用EMBSTR。
Redis在3.0引入EMBSTR编码,这是一种专门用于保存短字符串的一种优化编码方式,这种编码和RAW编码都是用sdshdr简单动态字符串结构来表示。RAW编码会调用两次内存分配函数来分别创建redisObject和sdshdr结构,而EMBSTR只调用一次内存分配函数来分配一块连续的空间保存数据,比起RAW编码的字符串更能节省内存,以及能提升获取数据的速度。
不过要注意!EMBSTR是不可修改的,当对EMBSTR编码的字符串执行任何修改命令,总会先将其转换成RAW编码再进行修改;而INT编码在条件满足的情况下也会被转换成RAW编码。
2.ziplist
ziplist编码主要目的是为了节约内存, 因此所有数据都是采用线性连续的内存结构。 ziplist编码是应用范围最广的一种, 可以分别作为hash、 list、zset类型的底层数据结构实现。 首先从ziplist编码结构开始分析, 它的内部结构类似这样: <…>
。 一个ziplist可以包含多个entry(元素) , 每个entry保存具体的数据(整数或者字节数组)。
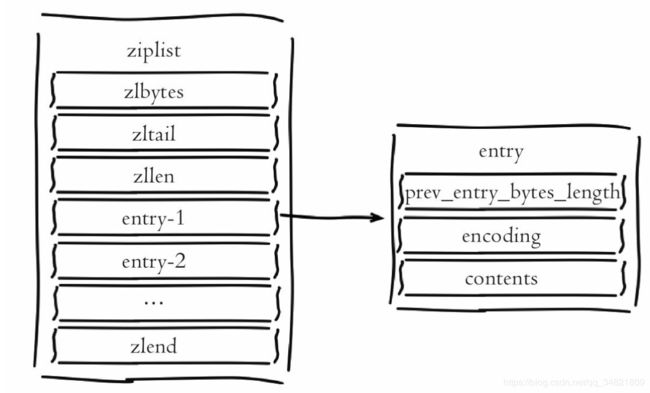
ziplist结构字段含义:
1) zlbytes: 记录整个压缩列表所占字节长度, 方便重新调整ziplist空间。 类型是int-32, 长度为4字节。
2) zltail: 记录距离尾节点的偏移量, 方便尾节点弹出操作。 类型是int-32, 长度为4字节。
3) zllen: 记录压缩链表节点数量, 当长度超过216-2时需要遍历整个列表获取长度, 一般很少见。 类型是int-16, 长度为2字节。
4) entry: 记录具体的节点, 长度根据实际存储的数据而定。
a) prev_entry_bytes_length: 记录前一个节点所占空间, 用于快速定位上一个节点, 可实现列表反向迭代。
b) encoding: 标示当前节点编码和长度, 前两位表示编码类型: 字符串/整数, 其余位表示数据长度。
c) contents: 保存节点的值, 针对实际数据长度做内存占用优化。
5) zlend: 记录列表结尾, 占用一个字节。
根据以上对ziplist字段说明, 可以分析出该数据结构特点如下:
·内部表现为数据紧凑排列的一块连续内存数组。
·可以模拟双向链表结构, 以O(1) 时间复杂度入队和出队。
·新增删除操作涉及内存重新分配或释放, 加大了操作的复杂性。
·读写操作涉及复杂的指针移动, 最坏时间复杂度为O(n2) 。
·适合存储小对象和长度有限的数据。
3.hashtable
hashtable的实现和java的hashmap实现几乎一致,提供O(1)时间复杂度的查询和新增操作。对于redis的基础数据类型。ziplist提供O(N^2)的查找,新增操作(查找时遍历整个entry对于每个key都进行比较),而hashtable提供了o1。所以当少量的数据和小key时可以采用ziplist来提高空间利用率,小数据的稿时间复杂度操作并不会太影响性能。大量数据和的key需要用hashtable来提高速度,尽管hashtable空间利用率不高。
4.intset
intset结构由encoding、length 、contents 3个属性构成,而且内部的数据结构排列紧密,类似于ziplist,但是intset里面存的全都是顺序排列的整数。由于是顺序排列的整数,所以查找可用二分查找,时间复杂度o(logn)。因为是紧凑的数据结构,所以插入元素涉及到数据的复制,时间复杂度为
o(n)。因为需要有序来提供二分查找,所以需要内部元素都是数字。因为查找和新增,删除时间复杂度都不是o1,所以当存在大量数据是需要转成hashtable。set的两种内部实现和之间的转换关系由此可见。
5.quicklist
考虑到链表的附加空间相对太高,prev 和 next 指针就要占去 16 个字节 (64bit 系统的指针是 8 个字节),另外每个节点的内存都是单独分配,会加剧内存的碎片化,影响内存管理效率。后续版本对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist。下面看旧版本redis的list内部编码实现:
linkedlist
双向链表在表的两端进行push和pop操作十分的便节,但是它的内存开销比较大。
首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;
其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
ziplist
ziplist由于是一整块连续内存,所以存储效率很高。
首先,它不利于修改操作,每次数据变动都会引发一次内存的realloc。
其次,当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,进一步降低性能。
Redis基于空间和时间的考虑,于是quicklist结合双向链表和ziplist的优点。
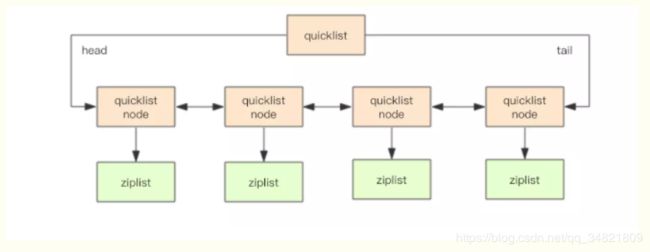
可见 quicklist的实现是每个节点都是ziplist的linkedlist。并且ql持有head和tail的ziplist。方便头尾节点的push,pop(linkedlist的优点)。节点采用ziplist从而减少了每个节点元素头尾引用和内存空间碎片。每个ziplist长度的控制减少了ziplist中的新增删除操作的时间复杂度,所以,quicklist集合了ll和zl的优点。
list-max-ziplist-size
每个quicklist节点上的ziplist越短,则内存碎片越多。内存碎片多了,有可能在内存中产生很多无法被利用的小碎片,从而降低存储效率。这种情况的极端是每个quicklist节点上的ziplist只包含一个数据项,这就蜕化成一个普通的双向链表了。
每个quicklist节点上的ziplist越长,则为ziplist分配大块连续内存空间的难度就越大。有可能出现内存里有很多小块的空闲空间(它们加起来很多),但却找不到一块足够大的空闲空间分配给ziplist的情况。这同样会降低存储效率。这种情况的极端是整个quicklist只有一个节点,所有的数据项都分配在这仅有的一个节点的ziplist里面。这其实蜕化成一个ziplist了。
可见,一个quicklist节点上的ziplist要保持一个合理的长度。那到底多长合理呢?Redis提供了一个配置参数list-max-ziplist-size,就是为了让使用者可以来根据实际应用场景进行调整优化。
list-compress-depth
其表示一个quicklist两端不被压缩的节点个数。注:这里的节点个数是指quicklist双向链表的节点个数,而不是指ziplist里面的数据项个数。实际上,一个quicklist节点上的ziplist,如果被压缩,就是整体被压缩的。
当表list存储大量数据的时候,最容易被访问的很可能是两端的数据,中间的数据被访问的频率比较低(访问起来性能也很低)。如果应用场景符合这个特点,那么list还提供了一个选项,能够把中间的数据节点进行压缩,从而进一步节省内存空间。Redis的配置参数list-compress-depth就是用来完成这个设置的。
6.skiplist
SkipList是一种有序的数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均O(logN),最坏O(N)负责度的节点查找。还可以通过顺序性操作来批量处理节点,在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且跳跃表的实现比平衡树来的更为简单,所以有不少程序使用跳跃表来代替平衡树。
Redis中的有序集合键使用跳跃表作为底层的实现之一,如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时,Redis会使用跳跃表来作为有序集合的底层实现。

skiplist与平衡树、哈希表的比较
skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
从算法实现难度上来比较,skiplist比平衡树要简单得多。
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
这两个参数是指 什么情况下一个zset的内部编码会从ziplist转为skiplist,可见ziplist几个操作都是高时间复杂度的操作,但是内存利用率高,而skiplist操作时间复杂度更小(需要更多的内存)。
Redis为什么用skiplist而不用平衡树?
在前面我们对于skiplist和平衡树、哈希表的比较中,其实已经不难看出Redis里使用skiplist而不用平衡树的原因了。现在我们看看,对于这个问题,Redis的作者 @antirez 是怎么说的:
There are a few reasons:
-
They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
内存利用率比平衡数高 -
A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
zset经常用于ZRANGE 和ZREVRANGE 操作,最坏情况下skiplist和平衡树的性能差不多好。 -
They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
skiplist实现简单。
这里从内存占用、对范围查找的支持和实现难易程度这三方面总结的原因,我们在前面其实也都涉及到了。