【实战】利用python爬虫爬取中国大学慕课课程视频及文件
完整项目地址:https://github.com/CyrusRenty/MOOC-Download
1 背景
我们在看中国大学慕课上的资源时候会很明显的发现网易的线上播放器做的很不友好,也经常卡顿。而且有时候想要视频和资料对照着看时候也很不方便,所以写了这样一个爬虫,可以一键爬取课程中所有的视频资料,并且下载所有的pdf文件。
2 技术栈说明
本爬虫在实现时主要就用了request和re两个库,相对比较简单。由于MOOC上的页面都不是静态页面,所以我们不能直接抓取页面的内容,需要从http请求入手。
简单的判断是否为静态页面的方法:针对一个页面,按下CTRL+U,在弹出的源码页面查找原页面中的数据字段,如果没有那么一定是动态页面。
对于动态加载的部分,也就是Ajax请求,在network中为特殊的请求类型,叫做xhr。同时在该请求的Request Headers中有一个信息为X-Reauest-With:XMLHttpRequest,即代表了这是一个Ajax请求。
在分析网站时,我们主要使用fiddler进行数据抓包。
3 慕课网逻辑分析
此处主要记录我在分析时的思路,这一块内容我参考了这位博主的博文,但是他写的比较简略,所以我稍微补充一下我的思路。
3.1 寻找资源列表如何传递的
首先,一般慕课网的章节划分都是章节为一级目录,以及目录下有很多二级目录,每个二级目录中又有很多的具体资源项。
我们进入任意课程,可以发现一般我们在课件页面可以在选择任意子资源进入开始学习,故可以推测在进入这个页面之前一定有发送相关的课程信息(比如课程id什么的)来进行获取资源列表。

利用fiddler分析在进入这个页面的时候都有哪些请求(为了尽量少不必要的请求,我们可以先点到比如评分标准,然后清空fiddler里面所有请求,再点回课件,这样可以少处理比如头部一些不是这里我们需要的请求。)可以看到一共只有6个请求,这里只有一个post请求,而且数据量相比于其他的大了很多,所以我们着重分析这个请求。
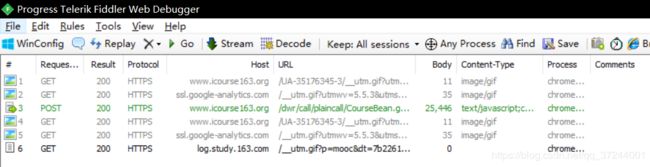
复制该请求返回的数据到Nodepad++分析,可以发现里面的数据非常有规律,但是由于编码原因,里面的中文数据都是乱码,非常不利于我们分析,所以我们可以先复制这些字符,然后通过 encode('utf-8').decode('unicode_escape') 方法进行两次转译,然后就会将乱码中文字符转换成中文。
转译前:
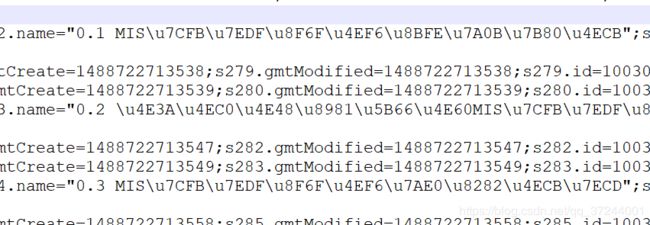
转译后:

通过分析这个文本我们可以对整个目录的结构都有一个大体的了解。比如每个章节标题的id是和下面子章节的charpterId对应的。具体需要什么信息我们可以一会再分析。
现在我们再来看看这个请求的发送时候需要发送什么信息,同样是在fiddler中查看row中信息(红框中的即为post请求发送的信息):

单独一个课程的请求可能让我们无法清晰的认识到哪些字段是不变的,那些是变化的,所以建议多试几个不同课程的请求,然后我们就可以很明显的发现这些字段是有规律的,其中大部分字段是不变的,一些可能变化的字段的说明
| 所需字段 | 字段说明 |
|---|---|
| c0-param0 | number:某一特定的id。 |
| batchId | 时间戳,可以指定一个固定的。 |
所以现在我们的关键就是如何找到课程的唯一id了。
3.2 寻找课程唯一id
我们如果有注意到话会看到其实这个id和我们在现在地址栏出现的tid是一致的。

所以我们可以推测这个id应该是在进入课程介绍界面时候获取的。因为在课程介绍页面是没有这个id的,我们再次通过fiddler
抓取进入课程介绍界面时候的请求,根据经验一般这种id都会在第一个请求时候获得,通过查看第一个第一个get请求,在返回数据中,我们的确可以检索到相应的id字段。
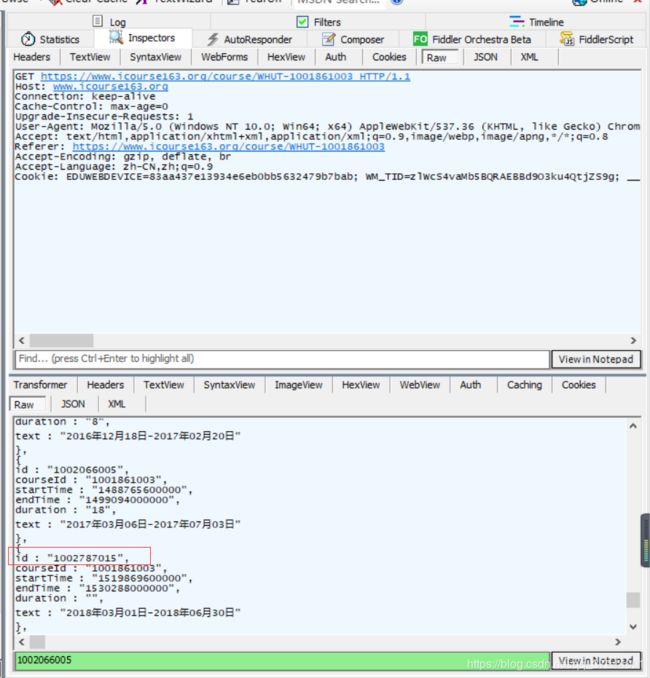
现在有了唯一id,也就可以获得这个课程的所有资源列表了,回过头再去看一次我们3.1中获得的资源列表文件,可以看到里面只有数据字段并没有下载链接,所以我们还需要进一步到具体的视频或文件界面去分析。
3.3 寻找资源下载方式
同样的,我们用fiddler截取时,可以先进入到具体播放页面,然后清空fiddler记录,再次跳转,这样保证了除了中心部分内容,其他部分文件不会再次请求。通过分析我们可以看到这次同样只有一个post请求,而且体积最大,随意着重对其分析。
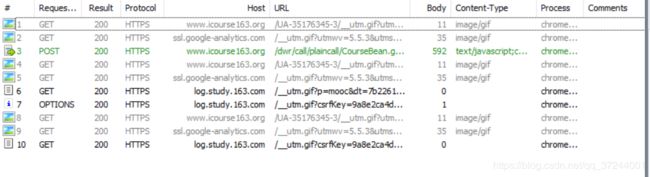
如果是文件资源,那么可以直接在fiddler中查看返回的json格式数据,在里面我们可以非常容易的发现有一个下载地址,这样我们就已经确定了如何下载pdf。

如果是视频资源,那么fiddler中不能直接转换成json格式,我们继续到notepad++中打开,可以看到里面有非常多的下载链接,根据字段可以推测应该是用于不同的播放器以及不同的清晰度,这也为我们之后选择选择视频的格式有了可能性。

下面来看一下post请求的请求体中都有哪些内容,如果对比不同的视频及文档请求,可以发现其中同样有很多是固定不变的,会变化的请求列出如下:

| 所需字段 | 字段说明 |
|---|---|
| c0-param0 | number: 二级目录id |
| c0-param1 | number: 判定文件还是视频 |
| c0-param3 | number: 这一内容id |
| batchId | 时间戳,可以指定一个固定的。 |
根据请求需要的信息,就告诉我们需要再次回到之前返回资源列表中去寻找相应的信息。
3.4 寻找下载所需字段
首先,一般慕课网的章节划分都是章节为一级目录,以及目录下有很多二级目录,每个二级目录中又有很多的具体资源项。
通过自己查看之前转译过的资源列表信息,我们可以发现一些重要的字段含义:
| 所需字段 | 字段说明 |
|---|---|
| contentType | 资源属于什么类型。(1为视频,3为文档,一级目录同样为1) |
| id | 每个资源(或一二级目录)对应的唯一绝对id。 |
| lessonId | 在资源项中出现,对应的二级目录id |
| chapterId | 在二级目录出现,对应一级目录id |
有了以上的分析,我们就可以来正式写这个爬虫的代码了。
4 代码实现
有了之前的逻辑分析,代码实现就比较简单了。在实现代码之前,再梳理一遍获取慕课资源的流程图。

整体代码实现的逻辑也是上面这几点,下面只对部上述几个步骤关键代码进行说明,具体实现可以下载源码自行查看。
4.1 获取课程ID及基本信息
在获取课程ID之前,我们需要让用户自行输入课程显性id,也就是之前在浏览器上看到的以学校缩写和一串数组组成的id,比如 WHUT-1001861003 。在这里创建一个course类,并在其中定义获取课程具体信息的方法:
class Course(object):
'''
存储课程相关信息
'''
def __init__(self, *args, **kwargs):
self.course_page_url = 'http://www.icourse163.org/learn/'
def set_course(self, course):
self.course = course
def get_course_info(self):
'''
获取课程基本信息
获取课程id用于发送post请求
'''
course_page_url = self.course_page_url + self.course
course_page = requests.get(course_page_url, headers=HEADER)
id_pattern_compile = re.compile(r'id:(\d+),')
# 获取课程名称
basicinfo_pattern_compile = re.compile(
r')
basic_set = re.search(basicinfo_pattern_compile, course_page.text)
self.course_title = basic_set.group(1)
self.course_collage = basic_set.group(2)
self.course_id = re.search(id_pattern_compile,
course_page.text).group(1)
4.2 获取资源列表并遍历到具体资源
通过上一步获取到的课程id,这里我们采用循环遍历的方式,依次用上一级的id作为下一级的正则表达式标识符,遍历到具体的资源信息,从中将我们在获取下载地址是需要的字段提取出来。同时在这里,在每一级遍历是,将慕课文档结构记录在名为TOC.txt的文档中,方便查阅文档目录。
在方法内部,我们对所有的文件进行了重命名,一是因为有一些pdf中,会有< >这样无法存储的符号出现,所以我们要对这些符号进行删除。其次将一些无效的第一章、第一部分等等字段删除。(因为我们已经进行了统一的编号)
def get_course_all_source(course_id):
'''
通过解析的course_id获取当前所有可下载的资源信息
'''
# 选择下载视频的清晰度
video_level = select_video_level()
# c0-param0:代表课程id
# batchId:可以为任意时间戳
# 其他字段为固定不变字段
post_data = {
'callCount': '1',
'scriptSessionId': '${scriptSessionId}190',
'c0-scriptName': 'CourseBean',
'c0-methodName': 'getMocTermDto',
'c0-id': '0',
'c0-param0': 'number:' + course_id,
'c0-param1': 'number:1',
'c0-param2': 'boolean:true',
'batchId': '1492167717772'
}
source_info = requests.post(
SOURCE_INFO_URL, data=post_data, headers=HEADER)
# 对文档内容进行解码,以便查看中文
source_info_transcoding = source_info.text.encode('utf-8').decode(
'unicode_escape')
# 这里的id是一级目录id
chapter_pattern_compile = re.compile(
r'homeworks=.*?;.+id=(\d+).*?name="(.*?)";')
# 查找所有一级级目录id和name
chapter_set = re.findall(chapter_pattern_compile, source_info_transcoding)
with open('TOC.txt', 'w', encoding='utf-8') as file:
# 遍历所有一级目录id和name并写入目录
for index, single_chaper in enumerate(chapter_set):
file.write('%s \n' % (single_chaper[1]))
# 这里id为二级目录id
lesson_pattern_compile = re.compile(
r'chapterId=' + single_chaper[0] +
r'.*?contentType=1.*?id=(\d+).+name="(.*?)".*?test')
# 查找所有二级目录id和name
lesson_set = re.findall(lesson_pattern_compile,
source_info_transcoding)
# 遍历所有二级目录id和name并写入目录
for sub_index, single_lesson in enumerate(lesson_set):
file.write(' %s \n' % (single_lesson[1]))
# 查找二级目录下视频,并返回 [contentid,contenttype,id,name]
video_pattern_compile = re.compile(
r'contentId=(\d+).+contentType=(1).*?id=(\d+).*?lessonId='
+ single_lesson[0] + r'.*?name="(.+)"')
video_set = re.findall(video_pattern_compile,
source_info_transcoding)
# 查找二级目录下文档,并返回 [contentid,contenttype,id,name]
pdf_pattern_compile = re.compile(
r'contentId=(\d+).+contentType=(3).+id=(\d+).+lessonId=' +
single_lesson[0] + r'.+name="(.+)"')
pdf_set = re.findall(pdf_pattern_compile,
source_info_transcoding)
name_pattern_compile = re.compile(
r'^[第一二三四五六七八九十\d]+[\s\d\._章课节讲]*[\.\s、]\s*\d*')
# 遍历二级目录下视频集合,写入目录并下载
count_num = 0
for video_index, single_video in enumerate(video_set):
rename = re.sub(name_pattern_compile, '', single_video[3])
file.write(' [视频] %s \n' % (rename))
get_content(
single_video, '%d.%d.%d [视频] %s' %
(index + 1, sub_index + 1, video_index + 1, rename),
video_level)
count_num += 1
# 遍历二级目录下pdf集合,写入目录并下载
for pdf_index, single_pdf in enumerate(pdf_set):
rename = re.sub(name_pattern_compile, '', single_pdf[3])
file.write(' [文档] %s \n' % (rename))
get_content(single_pdf,'%d.%d.%d [文档] %s'%(index+1,sub_index+1,pdf_index+1+count_num,rename))
4.3 请求具体资源信息并下载处理
由于慕课资源主要分为两种,一种为视频,一种为pdf。两种在获取下载地址时有所不同,所以我们要分别进行判断。
在下载时,pdf一般较小,所以可以选择直接下载,这里下载是我们是将返回的内容重新用 file.write 方法写入成新的pdf文件,并根据之前我们对文件名的处理进行重新命名。对于比较大的视频文件,采用存储下载链接的方式,供第三方软件下载。
在这里我们创建了一个Rename.bat文件,主要是由于视频在下载下来时一般命名都是随机的(根据服务器上存储的命名),所以我们在写入下载链接时,同时将在服务器上的视频名称及我们已经在上一步处理过的视频名称写入,供下载好后批量改名。
def get_content(single_content, name, *args):
'''
如果是文档,则直接下载
如果是视频,则保存链接供第三方下载
'''
# 检查文件命名,防止网站资源有特殊字符本地无法保存
file_pattern_compile = re.compile(r'[\\/:\*\?"<>\|]')
name = re.sub(file_pattern_compile, '', name)
# 检查是否有重名的(即已经下载过的)
if os.path.exists('PDFs\\' + name + '.pdf'):
print(name + "------------->已下载")
return
post_data = {
'callCount': '1',
'scriptSessionId': '${scriptSessionId}190',
'httpSessionId': '5531d06316b34b9486a6891710115ebc',
'c0-scriptName': 'CourseBean',
'c0-methodName': 'getLessonUnitLearnVo',
'c0-id': '0',
'c0-param0': 'number:' + single_content[0], # 二级目录id
'c0-param1': 'number:' + single_content[1], # 判定文件还是视频
'c0-param2': 'number:0',
'c0-param3': 'number:' + single_content[2], # 具体资源id
'batchId': '1492168138043'
}
sources = requests.post(
SOURCE_RESOURCE_URL, headers=HEADER, data=post_data).text
# 如果是视频的话
if single_content[1] == '1':
if args[0] == 'a':
download_pattern_compile = re.compile(r'mp4SdUrl="(.*?\.mp4).*?"')
elif args[0] == "b":
download_pattern_compile = re.compile(r'mp4HdUrl="(.*?\.mp4).*?"')
else:
download_pattern_compile = re.compile(r'mp4ShdUrl="(.*?\.mp4).*?"')
video_down_url = re.search(download_pattern_compile, sources).group(1)
print('正在存储链接:' + name + '.mp4')
with open('Links.txt', 'a', encoding='utf-8') as file:
file.write('%s \n' % (video_down_url))
with open('Rename.bat', 'a', encoding='utf-8') as file:
file.write('rename "' + re.search(
r'http:.*/(.*?.mp4)', video_down_url).group(1) + '" "' + name +
'.mp4"' + '\n')
# 如果是文档的话
else:
pdf_download_url = re.search(r'textOrigUrl:"(.*?)"', sources).group(1)
print('正在下载:' + name + '.pdf')
pdf_file = requests.get(pdf_download_url, headers=HEADER)
if not os.path.isdir('PDFs'):
os.mkdir(r'PDFs')
with open('PDFs\\' + name + '.pdf', 'wb') as file:
file.write(pdf_file.content)
剩下的方法主要是一些输入输出监测等等,这里就不再进行演示。
最后欢迎大家Star或者给我issue~~