Mask R-CNN论文综述
Mask R-CNN论文综述
摘要:提出了一个简单、灵活、通用的目标实例分割框架Mask R-CNN。这个框架可同时做目标检测、实例分割。实例分割的实现就是在faster r-cnn的基础上加了一个可以预测目标掩膜(mask)的分支。只比Faster r-cnn慢一点,5fps。很容易拓展到其他任务如:关键点检测。18年在coco的目标检测、实例分割、人体关键点检测都取得了最优成绩。
1、 引言
计算机视觉发展很快,faster r-cnn只用于目标检测,FCN只用于语义分割,mask r-cnn的任务就是将目标检测与实例分割结合在一起。
实例分割混合了目标检测(分类、定位)和语义分割(给每个像素点确定一个所属类别,而不区分是否属于不同实例)的元素,所以直觉上感觉需要一个更复杂的方法解决这个问题。实则并非如此。
Mask r-cnn在faster r-cnn的基础上加了一个预测分支,这个分支是对每个输入的Roi进行处理,与目标搜检测和bb回归并行,下图所示为实例分割的分支。
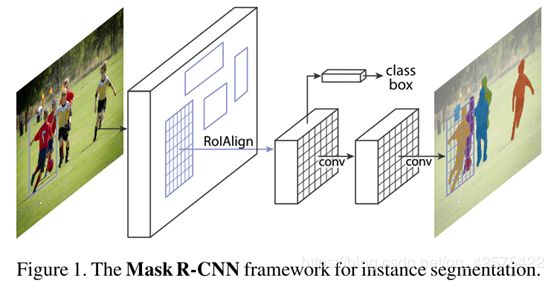
实例分割的分支就是一个应用到每个roi上的FCN网络。由于借了faster r-cnn的东风,mask r-cnn很容易就能实现和训练,faster r-cnn提供了更大范围更灵活的架构设计。而且,实例分割分支只给faster r-cnn加入了一个非常小的计算开销。
如何构建mask分支很重要,因为faster r-cnn并不是为实例分割所设计的,其roipooling操作是通过粗糙的空间量化来提取特征,会去除很多像素点,丢失细节信息,而这些像素点都是实例分割所必须的,故不能从roipooling之后生成的向量作为实例分割分支的输入,而要取roipooling之前的fm即每个roi作为mask分支的输入,而且mask分支中还要有个roialign操作来完整地保存空间位置信息。
为了解决错位的问题,新提出解决方案:
1)分割实例中去除roipooling,添加RoIAlign:RoIAlign看似一个小操作,却能给实例分割的准确度提高了10%~50%。
2)将分类预测与掩膜预测相分离(去耦合):即对独立地对每个类别预测一个二进制的掩膜,而不是同时对多个类别进行预测掩膜,并且是依赖网络的带有roi的分类分支来确定要对那个类别预测掩膜。
作为对比,FCN通常实现的是在多类别之间同时做预测掩膜,这种方法耦合了分割与分类,这种方法用在faster r-cnn上表现很差。
mask r-cnn在8GPU的单机上训练要花1~2天,每张图片的推断时间是200ms(5fps)。
2.相关工作
R-CNN系列:
实例分割:以前的方法都是先进行分割然后进行识别分类,不仅慢而且精度低。也有其他多阶段串联的方法: 先预测出目标的候选框,然后在候选框中做分割,最后在分割的基础上做分类识别。
而mask r-cnn是同时做分割和分类,更简单更灵活。
几乎与mask r-cnn同期,也有同时做分类、检测框回归和预测掩膜的方法FCIS,但是效果不好,它对于重叠实例会有错误,而且掩膜边界也不对。
还有的实例分割的方法是先进行语义分割,将每个像素点属于什么类别确定好之后再进行实例分割。上面都是些先做语义分割,再进行实例分割,mask r-cnn是上来就做实例分割。
3.Mask r-cnn
mask r-cnn中的实例分割分支中有一道faster r-cnn中缺少的操作,RoIAlign,这一步可以提取更加精细的目标的空间位置信息。
Faster r-cnn回顾:rpn+两个同级分支(分类+定位)
Mask r-cnn: rpn网络跟faster r-cnn的一样,也有跟faster r-cnn中一样的同级的分类和定位网络,同时增加了一个预测二进制掩膜的并行分支。
mask r-cnn的损失函数:
![]()
其中分类损失和定位损失与faster r-cnn中的一样。
mask分支对每个roi会转变为K(类别总数)个m*m大小的fm,之后每个fm上的每个像素点会应用sigmoid激活,Lmask为平均二进制交叉熵损失(average binary cross-entropy loss)。训练时如果类别标签是第i类,那么就只计算第i个mask输出的损失作为Lmask,其他K-1个掩膜输出对Lmask贡献为0。
在进行推断时,会利用专门预测分类的分支的输出确定选用那个掩膜输出。
这样就能够实现不是在类别之间预测掩膜,而是只针对某一类预测掩膜,即解耦合了掩膜和类别输出。
以上跟FCN不同之处就是FCN是对每个像素点计算softmax值并用一个多项的交叉熵损失函数。
掩膜表现力:分类和检测分支都会被全连接层折叠成端输出向量,难以保存空间位置信息。而卷积操作能够像素对应的保存空间位置信息,用于预测掩膜就合情合理了。
RoI是经过卷积操作输出的fm,这种fm很小,但是忠实地保存了每个像素点空间位置信息,这就促使我们研究RoIAlign层。
RoIAlign: RoIPool可对每个roi提取一个固定大小的小的fm(7*7),roipooling的量化(取整)操作会损失细节,导致RoI和提取的特征之间的错位,这种错位不会影响分类,因为分类具有平移不变性,但对于预测掩膜有极大影响。
为了解决roipooling中取整带来的问题,构建了roialign层,roialign与roipooling的区别就是roialign没有取整(quantization)操作,即在计算roi的边界、计算roi中的bin的边界、计算每个bin中的四个采样点的位置时用的全是浮点数,在计算四个采样点所表示的值时用了双边插值法,即根据他们与每个点最邻近的四个点的值确定这个点的值(不是这个点的位置,而是这个点的值),然后将这四个点的值用取平均或取最大值来聚合成一个点。
注意到:每个bin中取几个点以及每个点的位置在哪对最后的结果没影响,只要没有取整操作就行。
网络结构:
为证明方法的通用性和便于做比较,做了两种改变:
1) 改主干网络
2) 改网络头:将分类和回归作为一个头,掩膜预测作为一个头。
用命名法network-depth-features对主干网络进行命名,如ResNet-50-C4代表取50层残差的的第四层卷积层输出的fm作为主干网络的输出。
主干网络用了resnet和fpn做对比。

3.1实现细节
超参数跟faster r-cnn一样。
训练:跟faster r-cnn中一样??,如果roi与标签框的iou值大于0.5认为是正例,否则是负例。
注:在faster r-cnn中:
1)anchor对应到原图上与任意标签框的iou值大于0.7的认为是正例(有物体)anchor,小于0.3的认为是负例(背景)anchor
2)每个Anchor,如果与任意一个真实物体的标签框的iou值>0.7就认为是正例,这样就有可能某个物体对应着多个正例anchor。
Lmask只在正的RoI(姑且认为每个由rpn回归出来的roi都完全地包住对应的物体)上计算,每个预测出的mask的目标就是完全重合标签mask。
采用以图像为中心的训练(fast r-cnn中的?),resize原图至小边为800,每个mini-batch是16张图片置于8个gpu上,每张图片采样64个rois,正例roi与负例roi比例为1:3,初始学习率是0.02,120k次迭代之后降为0.002,总共迭代160k次。权重衰减0.0001,动量0.9。
rpn的anchor有5种大小,三种高宽比(按照fpn中的来的),为方便做消融实验,rpn网络权重和mask r-cnn不共享网络参数,但是由于cnn的网络结构一样,他们是可以共享参数的。
推断
推断阶段,rpn输出proposal数是300(c4 in resnet)或者1000(fpn中),在这些proposals中应用非极大值抑制留下100个proposals作为mask分支的输入(训练的时候不用非极大值抑制,会对rpn输出的每个proposal都输入mask分支中进行训练),每个roi输入到mask分支会预测出K(类别总数)个掩膜输出,但是只用分类分支预测出的那个类别对应的掩膜作为最终的掩膜,这个m*m大小(有很多个channel)的元素是浮点数(因为用了sigmoid激活,所以这些元素的值0~1之间)的掩膜,会以0.5为分解线将每个元素的值确定为0或者1。
注:roi与proposal有什么区别?
首先他们都是同一层卷积层crop出来的特征,roi是输入到第二步网络中的输入。proposal是rpn网络的输出。在训练阶段roi就是proposal,因为没有做nms,但在推断阶段,会做nms,使得roi数小于proposal数。
4.实验:实例分割
coco中的度量标准,对用每个掩膜的AP用标签mask与预测出的mask的iou值表示。
4.1主要结果
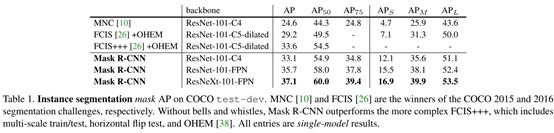
比较了FCIS,MNC,和以残差和fpn做主干网络的Mask R-CNN。
注FCIS+++是用了多尺度训练、水平翻转测试以及在线硬例最小化online hard example min- ing (OHEM) 等手段的FCIS。

4.2消融实验

主干网络架构影响:如图(a)一般来说主干网络越先进越好,但并不是所有的都这样,详见论文中提到的一篇论文。
多类别预测与单类别预测掩膜:如图(b),不用担心所属类别(由分类分支解决)问题,所以能更专注于掩膜预测。
特定类别VS类别无关的掩膜:出自上一对比的分析。mask r-cnn中的掩膜预测有两种方式,一种是每种类别都单独有个预测掩膜的分支,所以共有K个掩膜分支预测K个掩膜输出(也或者是单个掩膜分支预测K个掩膜输出,论文中对这一块没细讲)。另外一种是与类别无关掩膜预测,即是掩膜分支预测1掩膜输出,这个掩膜输出可以应用于所有类别,故称为类别无关。预测K个掩膜输出方案AP:30.3,预测单个掩膜(类别无关)方案AP:29.7,可将两者的ap差不多,多出来的0.6个百分点是由于解耦了分类与分割。
RoIAlign:不错,有用
Mask Branch:比较了以多层感知机(MLP)和FCN作为掩膜分支的表现,如(e)。
4.3 BB检测结果
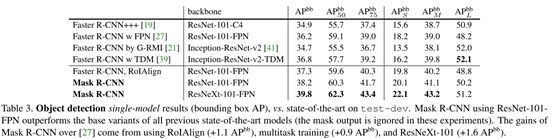
训练时掩膜分支也是训练的,但是在推断时忽略掩膜分支的输出,来单独看检测框的回归情况。
上表中faster r-cnn,RoIAlign是去掉了掩膜分支的Faster r-cnn,与最初的fpn版的faster r-cnn的区别就是用roialign取代了roipooling,这样做比之前的结果好。另外把mask分支去掉比带上mask分支的mask r-cnn的ap值低了0.9,可得多任务训练对检测框的回归也有帮助的结论。
最后由表一和表三对比值实例分割的ap比目标检测的ap稍微低。
4.4 时间消耗
推断:按照faster r-cnn的四部训练法训练ResNet-101-FPN模型,一张图的推断时间是210ms,rpn和faster r-cnn是否共享参数ap一样。
四部训练法训练ResNet-101-C4模型的推断时间是每张图片400ms,因为他的网络头更大,故实践中用fpn更好。
训练: mini-batch=16,8GPU,coco trainval135k数据集,训练ResNet-50-FPN花了32个小时。训练ResNet-101-FPN花了44小时。如果实在coco train数据集上训练,会更快。
5.将mask r-cnn用于人体姿态评估
用独热掩膜(one-hot mask:即只有一个点是1,其他点全是0)来模拟关键点的位置,利用mask r-cnn的掩膜分支预测K个独热掩膜,每个掩膜代表预测的一个关键点位置信息。
实现细节:由于关键点检测对分辨率要求更高,故需要上采样。
主要结果和消融实验:

由table5可见这个时候的多任务训练并不能提升bb框回归的准确度,反而降低了bb框回归的精度,但是多任务训练提升了掩膜分支的预测精度。
由table6可知roialign都能大幅提升关键点检测和实例分割的精度,因为他们都对保留空间位置信息有要求。