Hadoop3.0集群环境搭建
1 前言
项目中大部分数据存储在Hadoop分布式文件系统(HDFS)中,包括MPI并行用到的原始数据,因此我搭建了Hadoop集群进行测试。距离我搭建Hadoop集群也有几个月了,当时只记录下了主要步骤,有些细节可能被遗忘。不过我会用最通俗的语言还原搭建Hadoop3.0集群的流程,尽可能保证所有读者在看了我的文章后可以成功搭建出Hadoop集群。
2 准备工作
集群中两个节点(mpi-1和mpi-2),这是我在OpenStack分配的两个节点,具体内容可参考我以前博客(如果对并行没有兴趣,可以不用管)。注:可以根据需要修改节点主机名(这些都不是重点),我将mpi-1看作主节点Master,mpi-2看作从节点Worker(根据需要自行增加)。一句话概括,我的Hadoop集群用了两台虚拟机(mpi-1和mpi-2,主机名改不改无所谓),可以根据需要任意增加节点数量(步骤完全一样)。为了省去不必要的麻烦,新建虚拟机时用户保持一致(搭建Hadoop集群的每个节点用户名相同,我这里用户名都是ubuntu)。
其实我们可以直接去Hadoop官网,上面有完整的集群搭建步骤说明。安装Hadoop之前需要安装Java(Hadoop是java开发的,编译及运行都需要使用JDK)和ssh(Hadoop需要通过ssh来启动各个节点的进程)。
2.1 jdk安装(每个节点同样操作)
- 下载JDK(可到甲骨文网站Oracle下载,我当时下载的是jdk-8u151-linux-x64.tar.gz(jdk8都行)
- 在jdk压缩包目录下(我的路径是/home/ubuntu/java/)解压:
tar –zxvf jdk-8u151-linux-x64.tar.gz - 配置jdk(关于Linux配置文件,可以参考:Linux配置文件说明),执行以下命令:
vim ~/.bashrc
//在文件最后添加
export JAVA_HOME=/home/ubuntu/java/jdk1.8.0_151
export PATH=$JAVA_HOME/bin:$PATH
source ~/.bashrc //刷新配置
java –version //验证,查看 java 版本2.2 ssh免密码登录配置
2.2.1 网络环境配置
首先修改主机名和 IP 的映射关系,分别配置两台机器的hosts文件,在此之前先通过ip addr show或ifconfig命令查看两台机器(三个及三个以上节点只需添加即可)的IP地址,我的IP地址为:
mpi-1:10.10.10.12
mpi-2:10.10.10.17然后修改hosts文件:
sudo vim /etc/hosts 根据以上查得的IP地址,在两台机器的hosts文件中均输入以下内容并保存:
10.10.10.12 mpi-1
10.10.10.17 mpi-2此时,两个节点间应该可以互相ping通(在mpi-1上执行命令: ping mpi-2)。
2.2.2 ssh免密登录(可以参考我之前博客)
(1)在每个节点安装ssh服务:sudo apt-get install ssh (有些版本Ubuntu安装过程中可能会出现问题,安装错误提示一步一步搜索即可解决问题)。
(2)各节点生成私钥和公钥
ssh-keygen -t rsa // 生成的钥匙文件在 ~/.ssh/下,其他linux版本如CentOS路径会有所不同
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys //认证(执行该步后可以保证本机免密登录,使用ssh mpi-1进行测试)
(3)把各子节点的 id_rsa.pub 传到主节点
scp id_rsa.pub ubuntu@mpi-1:~/.ssh/id_rsa.pub.mpi-2(这里我们把mpi-1看作主节点,将mpi-2节点的钥匙文件传到node1上)
(4)在主节点上操作
cat ~/.ssh/id_rsa.pub.mpi-2 >> ~/.ssh/authorized_keys//认证
scp authorized_keys ubuntu@mpi-2:~/.ssh/authorized_keys//将认证文件传回每个子节点
(5)验证无密码登录
在mpi-1节点上执行:ssh mpi-2
注:这里只有两个节点,如果是更多节点或需要添加节点,只需模仿上述步骤修改每个节点的hosts文件,ssh免密登录配置时将所有节点的公钥文件传到主节点认证,然后将主节点的认证文件传回每个子节点。我是在OpenStack上创建的节点,文件传输我使用了其他服务器作为跳板(比如:scp authorized_keys [email protected]:~/.ssh/authorized_keys.mpi-2 使用190服务器作为跳板)。
3 Hadoop的安装与配置
3.1 安装Hadoop
3.1.1 下载
(1)到Hadoop官网下载,我下载的是hadoop-3.0.0.tar.gz
(2)同jdk类似,在家目录下(/home/ubuntu/)创建文件夹hadoop:mkdir hadoop,然后解压:tar –zxvf hadoop-3.0.0.tar.gz
3.1.2 配置环境变量
执行如下命令:
vim ~/.bashrc
//在文件最后添加
export HADOOP_HOME=/home/ubuntu/hadoop/hadoop-3.0.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc //刷新配置3.1.3 创建文件目录
mkdir /home/ubuntu/hadoop/tmp
mkdir /home/ubuntu/hadoop/dfs
mkdir /home/ubuntu/hadoop/dfs/data
mkdir /home/ubuntu/hadoop/dfs/name3.2 配置Hadoop
进入hadoop-3.0.0的配置目录:cd /home/ubuntu/hadoop/hadoop-3.0.0/etc/hadoop,依次修改hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml以及workers文件。
3.2.1 配置 hadoop-env.sh
vim hadoop-env.shexport JAVA_HOME=/home/ubuntu/java/jdk1.8.0_151 //在hadoop-env.sh中找到 JAVA_HOME,配置成对应安装路径
3.2.2 配置 core-site.xml (根据自己节点进行简单修改即可)
vim core-site.xml<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://mpi-1:9000value>
<description>HDFS的URI,文件系统://namenode标识:端口号description>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/ubuntu/hadoop/tmpvalue>
<description>namenode上本地的hadoop临时文件夹description>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
<description>Size of read/write buffer used in SequenceFilesdescription>
property>
configuration>3.2.3 配置 hdfs-site.xml
vim hdfs-site.xml<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
<description>Hadoop的备份系数是指每个block在hadoop集群中有几份,系数越高,冗余性越好,占用存储也越多description>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///home/ubuntu/hadoop/dfs/namevalue>
<description>namenode上存储hdfs名字空间元数据 description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///home/ubuntu/hadoop/dfs/datavalue>
<description>datanode上数据块的物理存储位置description>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>mpi-1:50090value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
<description>dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是truedescription>
property>
configuration>3.2.4 配置 mapred-site.xml
vim mapred-site.xml注:之前版本需要cp mapred-site.xml.template mapred-site.xml,hadoop-3.0.0直接是mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<description>The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn.description>
<final>truefinal>
property>
<property>
<name>mapreduce.jobtracker.http.addressname>
<value>mpi-1:50030value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>mpi-1:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>mpi-1:19888value>
property>
<property>
<name>mapred.job.trackername>
<value>http://mpi-1:9001value>
property>
configuration>3.2.5 配置 yarn-site.xml
vim yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mpi-1value>
<description>The hostname of the RM.description>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>mpi-1:8032value>
<description>${yarn.resourcemanager.hostname}:8032description>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>mpi-1:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>mpi-1:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>mpi-1:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>mpi-1:8088value>
property>
configuration>3.2.6 配置 workers 文件(之前版本是slaves,注意查看)
vim workers添加 mpi-2(根据需要也可以把主节点添加作为子节点)
3.3 复制hadoop文件夹到所有子节点
把配置好的 hadoop 文件传到各子节点:scp -r hadoop/ [email protected]:~/
注:这一步很重要,将整个hadoop文件夹传到所有子节点,保证所有节点配置相同,记得每个子节点配置hadoop环境变量。
4 运行Hadoop集群
4.1 格式化namenode
hdfs namenode -format //第一次使用hdfs,必须对其格式化(只需格式化一次)
4.2 启动Hadoop
start-dfs.sh
start-yarn.sh注:只要按照我的步骤配置和执行,一定可以成功启动。
4.3 查看集群是否成功启动
jps命令查看
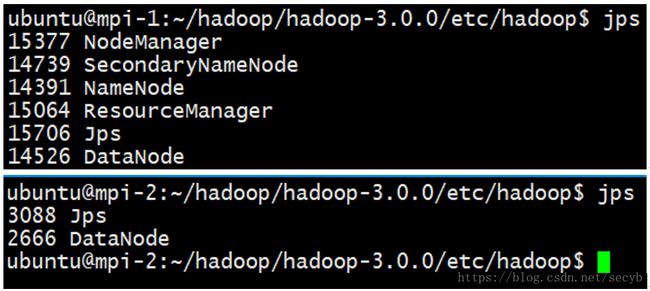
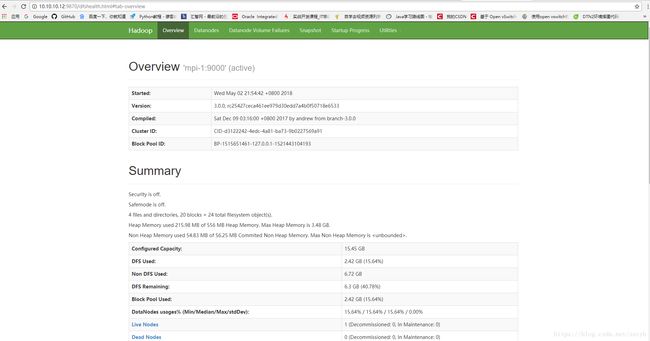
9870端口查看(这里是9870,不是50070了)
在浏览器输入10.10.10.12:9870,结果如下:
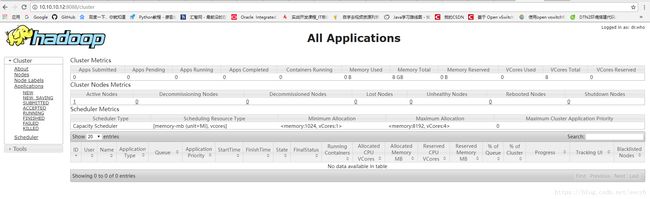
测试YARN
在浏览器输入10.10.10.12:8088,结果如下:
注:将绑定IP或mpi-1改为0.0.0.0,而不是本地回环IP,这样,就能够实现外网访问本机的8088端口了。比如这里需要将yarn-site.xml中的
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>mpi-1:8088value>
property>修改为:
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>0.0.0.0:8088value>
property>另外,可以直接参考Hadoop官网的默认配置文件进行修改,比如hdfs-site.xml文件,里面有详细的参数说明。另外可以使用hdfs dfs命令,比如hdfs dfs -ls /进行存储目录的查看。
5 总结
本文尽量以简洁的语言还原Hadoop3.0集群环境搭建的流程,旨在帮助新手以最快的时间成功搭建Hadoop集群。我的邮箱:[email protected],欢迎讨论。