爬虫抓取58简历之字库解密
爬虫抓取58同城 反反爬虫之字库解密
- 2019.03.01更新
- 前言
- 看不懂的字体
- 解密字库
- 字库自动解密API
2019.03.01更新
定制简历采集软件wechat联系13939147257. 解密没有什么技术含量, 所有环节都写在博文里. 请勿联系我资讯技术问题. API测试地址在最下方.
前言
最近接了个人力资源管理系统的项目, 部分数据需要抓取58的简历数据. 在数据抓取环节踩了很多坑, 所以写个博文分享下心得.
看不懂的字体
抓取的第一步就遇到了难题,浏览器可以显示字体,开发者模式看不到
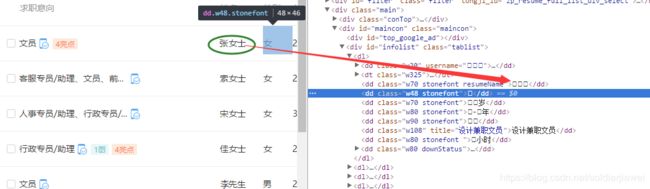
查看源码,发现未知编码,并且编码每次都变.
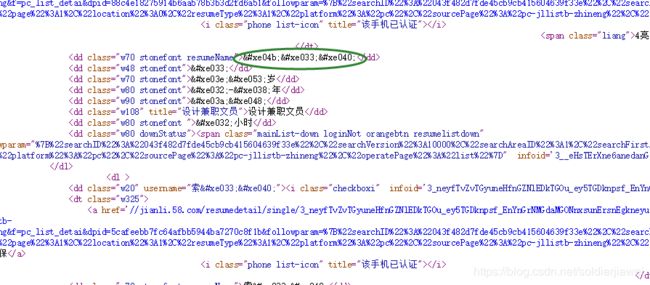
在html的css部分发现58加载了BASE64编码的WOFF动态字库, 每次刷新网页字库都不同.

解密字库
找了个WOFF to SVG在线字体转换网站将字体转化为SVG后可以看到字体数据了.

因为字库每次都不一样,所以多分析了几个字库文件,找到了字库的共同特征,看下图
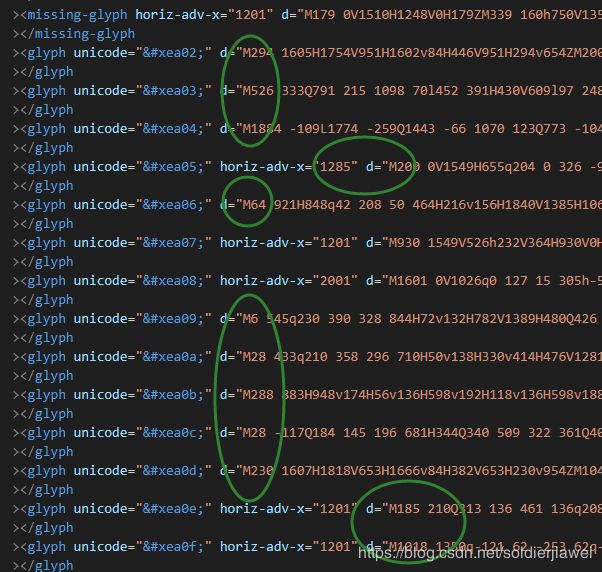
分析字库文件,找出了共同特征:
A、45个字体
B、字体unicode随机、D值随机
C、最重要的一点----> D值开头不变
剩下的就是体力活了, 找出D值和真实字体之间的对应关系. 我直接分享结果出来:
{"M52 ":"下","M570 ":"1","M143 ":"3","M28 4":"校","M308 ":"验","M294 ":"吴","M66 ":"王","M6 ":"硕","M1095 ":"7","M760 ":"陈","M1054 ":"5","M2010 ":"本","M24 ":"科","M64 9":"无","M853 ":"2","M816 ":"经","M168 ":"中","M1884 ":"女","M526 ":"专","M28 -10":"大","M950 ":"应","M382 ":"高","M1044 ":"刘","M185 ":"9","M720 ":"张","M1018 ":"6","M1702 ":"博","M1568 ":"杨","M288 ":"黄","M28 -11":"赵","M376 ":"周","M40 ":"生","M1542 ":"以","M528 ":"届","M188 ":"士","M91 ":"0","M1033 ":"E","M200 ":"B","M1417 ":"A","M1601 ":"M","M64 3":"李","M98 ":"8","M230 ":"男","M766 ":"技","M930 ":"4"}
字库自动解密API
前面把最难,最耗时间的问题解决了. 下面就是自动化处理流程了:
爬虫抓取HTML源码->取出加密字库->转化为SVG->根据D值取出unicode和真正字体的对应关系->替换HTML源码
我的项目是C#开发,转化SVG用了GITHUB的PYTHON库,为了C#开发的桌面程序使用方便,用PHP写了个API调用py脚本自动处理了(PS: 不会PYTHON, 别笑话我 ).
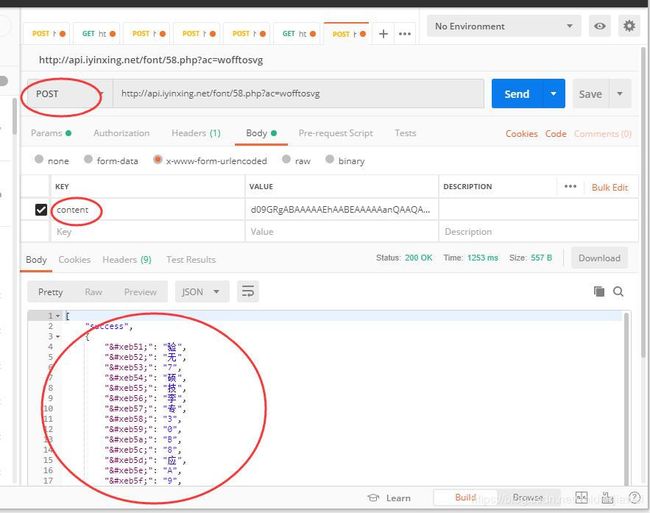
这里给出API地址, 提交BASE64编码的WOFF字体到服务器即可自动解密并返回Key=>Value对应的JSON数据. 接口限制了访问频率, 请勿用于商业用途.
Url: http://api.iyinxing.net/font/58.php?ac=wofftosvg
Method: POST
Parameters: content [String] BASE64编码的WOFF文件内容