Java常用消息队列原理介绍及性能对比
消息队列使用场景
为什么会需要消息队列(MQ)?
解耦
在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
冗余
有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的”插入-获取-删除”范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka保证一个Partition内的消息的有序性。
缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
MQ常用的使用场景:
1. 进程间通讯和系统间的消息通知,比如在分布式系统中。
2. 解耦,比如像我们公司有许多开发团队,每个团队负责业务的不同模块,各个开发团队可以使用MQ来通信。
3. 在一些高并发场景下,使用MQ的异步特性。
消息队列和RPC对比
系统架构
RPC系统结构:
+----------+ +----------+
| Consumer | <=> | Provider |
+----------+ +----------+Consumer调用的Provider提供的服务。
Message Queue系统结构:
+--------+ +-------+ +----------+
| Sender | <=> | Queue | <=> | Receiver |
+--------+ +-------+ +----------+Sender发送消息给Queue;Receiver从Queue拿到消息来处理。
功能特点
在架构上,RPC和Message Queue的差异点是,Message Queue有一个中间结点Message Queue(broker),可以把消息存储。
消息队列的特点
- Message Queue把请求的压力保存一下,逐渐释放出来,让处理者按照自己的节奏来处理。
- Message Queue引入一下新的结点,让系统的可靠性会受Message Queue结点的影响。
- Message Queue是异步单向的消息。发送消息设计成是不需要等待消息处理的完成。
所以对于有同步返回需求,用Message Queue则变得麻烦了。
RPC的特点
- 同步调用,对于要等待返回结果/处理结果的场景,RPC是可以非常自然直觉的使用方式。RPC也可以是异步调用。
- 由于等待结果,Consumer(Client)会有线程消耗。
如果以异步RPC的方式使用,Consumer(Client)线程消耗可以去掉。但不能做到像消息一样暂存消息/请求,压力会直接传导到服务Provider。
RPC适用场合说明
- 希望同步得到结果的场合,RPC合适。
- 希望使用简单,则RPC;RPC操作基于接口,使用简单,使用方式模拟本地调用。异步的方式编程比较复杂。
- 不希望发送端(RPC Consumer、Message Sender)受限于处理端(RPC Provider、Message Receiver)的速度时,使用Message Queue。
随着业务增长,有的处理端处理量会成为瓶颈,会进行同步调用到异步消息的改造。这样的改造实际上有调整业务的使用方式。
比如原来一个操作页面提交后就下一个页面会看到处理结果;改造后异步消息后,下一个页面就会变成“操作已提交,完成后会得到通知”。
RPC不适用场合说明
RPC同步调用使用Message Queue来传输调用信息。 上面分析可以知道,这样的做法,发送端是在等待,同时占用一个中间点的资源。变得复杂了,但没有对等的收益。
对于返回值是void的调用,可以这样做,因为实际上这个调用业务上往往不需要同步得到处理结果的,只要保证会处理即可。(RPC的方式可以保证调用返回即处理完成,使用消息方式后这一点不能保证了。)
返回值是void的调用,使用消息,效果上是把消息的使用方式Wrap成了服务调用(服务调用使用方式成简单,基于业务接口)。
常用的消息队列及使用场景
ActiveMQ
AcitveMQ是作为一种消息存储和分发组件,涉及到client与broker端数据交互的方方面面,它不仅要担保消息的存储安全性,还要提供额外的手段来确保消息的分发是可靠的。
ActiveMQ消息传送机制
Producer客户端使用来发送消息的, Consumer客户端用来消费消息;它们的协同中心就是ActiveMQ broker,broker也是让producer和consumer调用过程解耦的工具,最终实现了异步RPC/数据交换的功能。随着ActiveMQ的不断发展,支持了越来越多的特性,也解决开发者在各种场景下使用ActiveMQ的需求。比如producer支持异步调用;使用flow control机制让broker协同consumer的消费速率;consumer端可以使用prefetchACK来最大化消息消费的速率;提供”重发策略”等来提高消息的安全性等。在此我们不详细介绍。
一条消息的生命周期如下:
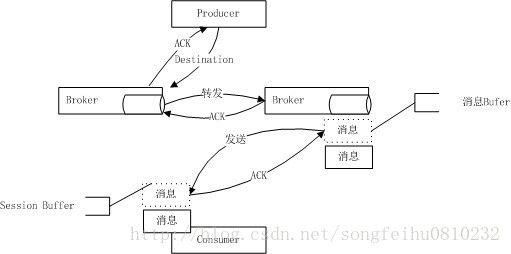
图片中简单的描述了一条消息的生命周期,不过在不同的架构环境中,message的流动行可能更加复杂.将在稍后有关broker的架构中详解..一条消息从producer端发出之后,一旦被broker正确保存,那么它将会被consumer消费,然后ACK,broker端才会删除;不过当消息过期或者存储设备溢出时,也会终结它。
ActiveMQ的安装
- 从官网下载安装包, http://activemq.apache.org/download.html
- 赋予运行权限 chmod +x,windows可以忽略此步
- 运行 ./active start | stop
启动后,activeMQ会占用两个端口,一个是负责接收发送消息的tcp端口:61616,一个是基于web负责用户界面化管理的端口:8161。这两个端口可以在conf下面的xml中找到。http服务器使用了jettry。这里有个问题是启动mq后,很长时间管理界面才可以显示出来。可以使用netstat -an|find “61616”来测试ActiveMQ是否启动。
Jms与ActiveMQ的结合
JMS是一个用于提供消息服务的技术规范,它制定了在整个消息服务提供过程中的所有数据结构和交互流程。而MQ则是消息队列服务,是面向消息中间件(MOM)的最终实现,是真正的服务提供者;MQ的实现可以基于JMS,也可以基于其他规范或标准。目前选择的最多的是ActiveMQ。
JMS支持两种消息传递模型:点对点(point-to-point,简称PTP)和发布/订阅(publish/subscribe,简称pub/sub)。这两种消息传递模型非常相似,但有以下区别:
- PTP消息传递模型规定了一条消息之恩能够传递费一个接收方。
- Pub/sub消息传递模型允许一条消息传递给多个接收方
点对点模型
通过点对点的消息传递模型,一个应用程序可以向另外一个应用程序发送消息。在此传递模型中,目标类型是队列。消息首先被传送至队列目标,然后从该队列将消息传送至对此队列进行监听的某个消费者,如下图:
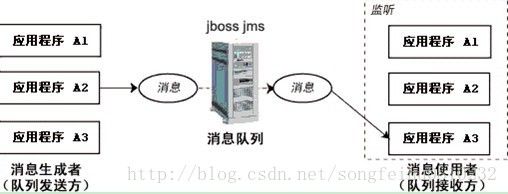
一个队列可以关联多个队列发送方和接收方,但一条消息仅传递给一个接收方。如果多个接收方正在监听队列上的消息,JMS Provider将根据“先来者优先”的原则确定由哪个价售房接受下一条消息。如果没有接收方在监听队列,消息将保留在队列中,直至接收方连接到队列为止。这种消息传递模型是传统意义上的拉模型或轮询模型。在此列模型中,消息不时自动推动给客户端的,而是要由客户端从队列中请求获得。
点对点模型的代码(springboot+jms+activemq)实现如下:
@Service("queueproducer")
public class QueueProducer {
@Autowired // 也可以注入JmsTemplate,JmsMessagingTemplate对JmsTemplate进行了封装
private JmsMessagingTemplate jmsMessagingTemplate;
// 发送消息,destination是发送到的队列,message是待发送的消息
@Scheduled(fixedDelay=3000)//每3s执行1次
public void sendMessage(Destination destination, final String message){
jmsMessagingTemplate.convertAndSend(destination, message);
}
@JmsListener(destination="out.queue")
public void consumerMessage(String text){
System.out.println("从out.queue队列收到的回复报文为:"+text);
}
}Producer的实现
@Component
public class QueueConsumer2 {
// 使用JmsListener配置消费者监听的队列,其中text是接收到的消息
@JmsListener(destination = "mytest.queue")
//SendTo 该注解的意思是将return回的值,再发送的"out.queue"队列中
@SendTo("out.queue")
public String receiveQueue(String text) {
System.out.println("QueueConsumer2收到的报文为:"+text);
return "return message "+text;
}
}
Consumer的实现
@RunWith(SpringRunner.class)
@SpringBootTest
public class ActivemqQueueTests {
@Autowired
private QueueProducer producer;
@Test
public void contextLoads() throws InterruptedException {
Destination destination = new ActiveMQQueue("mytest.queue");
for(int i=0; i<10; i++){
producer.sendMessage(destination, "myname is Flytiger" + i);
}
}
}Test的实现
其中QueueConsumer2表明的是一个双向队列。
发布/订阅模型
通过发布/订阅消息传递模型,应用程序能够将一条消息发送到多个接收方。在此传送模型中,目标类型是主题。消息首先被传送至主题目标,然后传送至所有已订阅此主题的或送消费者。如下图:
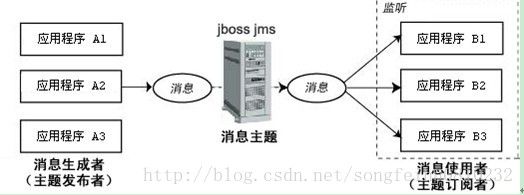
主题目标也支持长期订阅。长期订阅表示消费者已注册了主题目标,但在消息到达目标时该消费者可以处于非活动状态。当消费者再次处于活动状态时,将会接收该消息。如果消费者均没有注册某个主题目标,该主题只保留注册了长期订阅的非活动消费者的消息。与PTP消息传递模型不同,pub/sub消息传递模型允许多个主题订阅者接收同一条消息。JMS一直保留消息,直至所有主题订阅者都接收到消息为止。pub/sub消息传递模型基本上是一个推模型。在该模型中,消息会自动广播,消费者无须通过主动请求或轮询主题的方法来获得新的消息。
上面两种消息传递模型里,我们都需要定义消息生产者和消费者,生产者把消息发送到JMS Provider的某个目标地址(Destination),消息从该目标地址传送至消费者。消费者可以同步或异步接收消息,一般而言,异步消息消费者的执行和伸缩性都优于同步消息接收者,体现在:
1. 异步消息接收者创建的网络流量比较小。单向对东消息,并使之通过管道进入消息监听器。管道操作支持将多条消息聚合为一个网络调用。
2. 异步消息接收者使用线程比较少。异步消息接收者在不活动期间不使用线程。同步消息接收者在接收调用期间内使用线程,结果线程可能会长时间保持空闲,尤其是如果该调用中指定了阻塞超时。
3. 对于服务器上运行的应用程序代码,使用异步消息接收者几乎总是最佳选择,尤其是通过消息驱动Bean。使用异步消息接收者可以防止应用程序代码在服务器上执行阻塞操作。而阻塞操作会是服务器端线程空闲,甚至会导致死锁。阻塞操作使用所有线程时则发生死锁。如果没有空余的线程可以处理阻塞操作自身解锁所需的操作,这该操作永远无法停止阻塞。
发布/订阅模型的代码(springboot+jms+activemq)实现如下:
@Service("topicproducer")
public class TopicProducer {
@Autowired // 也可以注入JmsTemplate,JmsMessagingTemplate对JmsTemplate进行了封装
private JmsMessagingTemplate jmsMessagingTemplate;
// 发送消息,destination是发送到的队列,message是待发送的消息
@Scheduled(fixedDelay=3000)//每3s执行1次
public void sendMessage(Destination destination, final String message){
jmsMessagingTemplate.convertAndSend(destination, message);
}
}Producer的实现
@Component
public class TopicConsumer2 {
// 使用JmsListener配置消费者监听的队列,其中text是接收到的消息
@JmsListener(destination = "mytest.topic")
public void receiveTopic(String text) {
System.out.println("TopicConsumer2收到的topic报文为:"+text);
}
}Consumer的实现
@RunWith(SpringRunner.class)
@SpringBootTest
public class ActivemqTopicTests {
@Autowired
private TopicProducer producer;
@Test
public void contextLoads() throws InterruptedException {
Destination destination = new ActiveMQTopic("mytest.topic");
for(int i=0; i<3; i++){
producer.sendMessage(destination, "myname is TopicFlytiger" + i);
}
}
}Test的实现
Topic模式工作时,默认只能发送和接收queue消息,如果要发送和接收topic消息,需要加入:
spring.jms.pub-sub-domain=trueQueue与Topic的比较
JMS Queue执行load balancer语义
一条消息仅能被一个consumer收到。如果在message发送的时候没有可用的consumer,那么它讲被保存一直到能处理该message的consumer可用。如果一个consumer收到一条message后却不响应它,那么这条消息将被转到另外一个consumer那儿。一个Queue可以有很多consumer,并且在多个可用的consumer中负载均衡。Topic实现publish和subscribe语义
一条消息被publish时,他将发送给所有感兴趣的订阅者,所以零到多个subscriber将接收到消息的一个拷贝。但是在消息代理接收到消息时,只有激活订阅的subscriber能够获得消息的一个拷贝。分别对应两种消息模式
Point-to-Point(点对点),Publisher/Subscriber Model(发布/订阅者)
其中在Publicher/Subscriber模式下又有Nondurable subscription(非持久化订阅)和durable subscription(持久化订阅)两种消息处理方式。
ActiveMQ优缺点
优点:是一个快速的开源消息组件(框架),支持集群,同等网络,自动检测,TCP,SSL,广播,持久化,XA,和J2EE1.4容器无缝结合,并且支持轻量级容器和大多数跨语言客户端上的Java虚拟机。消息异步接受,减少软件多系统集成的耦合度。消息可靠接收,确保消息在中间件可靠保存,多个消息也可以组成原子事务。
缺点:ActiveMQ默认的配置性能偏低,需要优化配置,但是配置文件复杂,ActiveMQ本身不提供管理工具;示例代码少;主页上的文档看上去比较全面,但是缺乏一种有效的组织方式,文档只有片段,用户很难由浅入深进行了解,二、文档整体的专业性太强。在研究阶段可以通过查maillist、看Javadoc、分析源代码来了解。
RabbitMQ
简介
Rabbitmq简介可以参考我的两篇文章:
openstack的RPC机制之AMQP协议(http://blog.csdn.net/songfeihu0810232/article/details/73321828)
RabbitMQ高可用性(http://blog.csdn.net/songfeihu0810232/article/details/73924529)
RabbitMQ安装好之后的默认账号密码是(guest/guest)
需要注意的是:
多个消费者可以订阅同一个Queue,这时Queue中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理。这种分发方式叫做round-robin(循环的方式)。
当publisher将消息发给queue的过程中,publisher会指明routing key。Direct模式中,Direct Exchange 根据 Routing Key 进行精确匹配,只有对应的 Message Queue 会接受到消息。Topic模式中Exchange会根据routing key和bindkey进行模式匹配,决定将消息发送到哪个queue中。
有一个疑问:当有多个consumer时,rabbitmq会平均分摊给这些consumer;没办法把同一个message发给不同的consumer吗?
我之前的猜想是,当有多个consumer使用topic模式订阅消息时,所有的消息它们都会收到;但如果是direct模式,只有一个consumer会收到消息。(理解错误,topic和direct只是publisher用来选择发到不同的queue,不是consumer接收消息。一个队列一个消息只能发送给一个消费者,不然消费者的ack也会有很多,RabbitMQ Server也不好处理)
RabbitMQ的消息确认
默认情况下,如果Message 已经被某个Consumer正确的接收到了,那么该Message就会被从queue中移除。当然也可以让同一个Message发送到很多的Consumer。
如果一个queue没被任何的Consumer Subscribe(订阅),那么,如果这个queue有数据到达,那么这个数据会被cache,不会被丢弃。当有Consumer时,这个数据会被立即发送到这个Consumer,这个数据被Consumer正确收到时,这个数据就被从queue中删除。
那么什么是正确收到呢?通过ack。每个Message都要被acknowledged(确认,ack)。我们可以显示的在程序中去ack,也可以自动的ack。如果有数据没有被ack,那么:
RabbitMQ Server会把这个信息发送到下一个Consumer。而且ack的机制可以起到限流的作用(Benefitto throttling):在Consumer处理完成数据后发送ack,甚至在额外的延时后发送ack,将有效的balance Consumer的load。
RabbitMQ高可用方案
RabbitMQ有以下几种集群模式:
普通模式(默认)

上图是由3个节点(Node1,Node2,Node3)组成的RabbitMQ普通集群环境,Exchange A的元数据信息在所有节点上是一致的;而Queue的完整信息只有在创建它的节点上,各个节点仅有相同的元数据,即队列结构。
当producer发送消息到Node1节点的Queue1中后,consumer从Node3节点拉取时,RabbitMQ会临时在Node1、Node3间进行消息传输,把Node1中的消息实体取出并经过Node3发送给consumer。
该模式存在一个问题:当Node1节点发生故障后,Node3节点无法取到Node1节点中还未被消费的消息实体。如果消息没做持久化,那么消息将永久性丢失;如果做了持久化,那么只有等Node1节点故障恢复后,消息才能被其他节点消费。
对于publish,客户端任意连接集群的一个节点,转发给创建queue的节点存储消息的所有信息;
对于consumer,客户端任意连接集群中的一个节点,如果数据不在该节点中,则从存储该消息data的节点拉取。可见当存储有queue内容的节点失效后,只要等待该节点恢复后,queue中存在的消息才可以获取消费的到。
显然增加集群的节点,可以提高整个集群的吞吐量,但是在高可用方面要稍微差一些
至于为什么只在一个节点存储queue?
官方认为,如果之前一个节点的消息队列容量是1GB,那现在如果有三个节点,至少要增加2GB;同时rabbitmq的消息存储在磁盘上,如果每个消息在所有的节点活动的话,会大大增加网络和磁盘的负载,降低了集群的性能。
镜像模式
它是在普通模式的基础上,把需要的队列做成镜像队列,存在于多个节点来实现高可用(HA)。该模式解决了上述问题,Broker会主动地将消息实体在各镜像节点间同步,在consumer取数据时无需临时拉取。
该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被大量消耗。通常地,对可靠性要求较高的场景建议采用镜像模式。
在实现机制上,mirror queue内部实现了一套选举算法,有一个master和多个slave,queue中的消息以master为主,
对于publish,可以选择任意一个节点进行连接,rabbitmq内部若该节点不是master,则转发给master,master向其他slave节点发送该消息,后进行消息本地化处理,并组播复制消息到其他节点存储,
对于consumer,可以选择任意一个节点进行连接,消费的请求会转发给master,为保证消息的可靠性,consumer需要进行ack确认,master收到ack后,才会删除消息,ack消息会同步(默认异步)到其他各个节点,进行slave节点删除消息。
若master节点失效,则mirror queue会自动选举出一个节点(slave中消息队列最长者)作为master,作为消息消费的基准参考;在这种情况下可能存在ack消息未同步到所有节点的情况(默认异步),若slave节点失效,mirror queue集群中其他节点的状态无需改变。
其他模式
当然还有其他的方式,比如active/passive和shovel,主备方式(active,passive)只有一个节点处于服务状态,可以结合pacemaker和ARBD,shovel简单从一个broker的一个队列中消费消息,且转发该消息到另一个broker的交换机。 这两种方式用的比较少,这里就不做介绍了。
RabbitMQ功能测试
本次测试依然是RabbitMQ+springboot,首先需要application.properties
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest这里的端口是5672,,15672时管理端的端口。
pom要添加依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>Direct模型
Sender的实现:
@Component
public class Sender {
@Autowired
private RabbitTemplate rabbitTemplate;
public void send(String msg) {
this.rabbitTemplate.convertAndSend("tiger", msg);
}
}
Listener和listener2的实现均如下:
@Configuration
@RabbitListener(queues = "tiger")
public class Listener {
private static final Logger LOGGER = LoggerFactory.getLogger(Listener.class);
@Bean
public Queue fooQueue() {
return new Queue("tiger");
}
@RabbitHandler
public void process(@Payload String foo) {
LOGGER.info("Listener: " + foo);
}
}此时多次发送消息时,listener和listener2会按顺序分别收到消息。Listener收到的消息如下:
com.example.rabbitmq.Listener : Listener: this is a test
com.example.rabbitmq.Listener2 : Listener2: this is a test
com.example.rabbitmq.Listener : Listener: this is a test
com.example.rabbitmq.Listener2 : Listener2: this is a test
com.example.rabbitmq.Listener : Listener: this is a test
com.example.rabbitmq.Listener2 : Listener2: this is a test
com.example.rabbitmq.Listener : Listener: this is a test
com.example.rabbitmq.Listener2 : Listener2: this is a testTopic模型
Sender的实现:
@Component
public class SenderTopic {
@Autowired
private RabbitTemplate rabbitTemplate;
/*queue的key,用于和routing key 根据binding模式匹配*/
@Bean(name="message")
public Queue queueMessage() {
return new Queue("topic.message");
}
@Bean(name="messages")
public Queue queueMessages() {
return new Queue("topic.messages");
}
@Bean
public TopicExchange exchange() {
return new TopicExchange("exchange");
}
/*设置binding key,此时所有发送到这个exchange的消息,
exchange都会根据routing key将消息与@Qualifier定义的queue进行匹配*/
@Bean
Binding bindingExchangeMessage(@Qualifier("message") Queue queueMessage, TopicExchange exchange) {
return BindingBuilder.bind(queueMessage).to(exchange).with("topic.message");
}
@Bean
Binding bindingExchangeMessages(@Qualifier("messages") Queue queueMessages, TopicExchange exchange) {
return BindingBuilder.bind(queueMessages).to(exchange).with("topic.#");//*表示一个词,#表示零个或多个词
}
public void send(String routingKey, String msg) {
this.rabbitTemplate.convertAndSend("exchange",routingKey, msg);
}
}Listener的实现如下:
@Configuration
@RabbitListener(queues = "topic.message")//监听器监听指定的Queue
public class ListenerTopic {
private static final Logger LOGGER = LoggerFactory.getLogger(ListenerTopic.class);
@RabbitHandler
public void process(@Payload String foo) {
LOGGER.info("Listener: " + foo);
}
}listener2的实现如下
@Configuration
@RabbitListener(queues = "topic.messages")
public class ListenerTopic2 {
private static final Logger LOGGER = LoggerFactory.getLogger(ListenerTopic2.class);
@RabbitHandler
public void process(@Payload String foo) {
LOGGER.info("Listener2: " + foo);
}
}发送topic.message会匹配到topic.#和topic.message 两个Receiver都可以收到消息,发送topic.messages(或者top、topic等)只有topic.#可以匹配所有只有Receiver2监听到消息。
Fanout模型
@Configuration
public class SenderFanout {
@Autowired
private RabbitTemplate rabbitTemplate;
/*queue的key,用于和routing key 根据binding模式匹配*/
@Bean(name="Amessage")
public Queue AMessage() {
return new Queue("fanout.A");
}
@Bean(name="Bmessage")
public Queue BMessage() {
return new Queue("fanout.B");
}
@Bean
FanoutExchange fanoutExchange() {
return new FanoutExchange("fanoutExchange");//配置广播路由器
}
@Bean
Binding bindingExchangeA(@Qualifier("Amessage") Queue AMessage,FanoutExchange fanoutExchange) {
return BindingBuilder.bind(AMessage).to(fanoutExchange);
}
@Bean
Binding bindingExchangeB(@Qualifier("Bmessage") Queue BMessage, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(BMessage).to(fanoutExchange);
}
public void send(String msg) {
this.rabbitTemplate.convertAndSend("fanoutExchange","", msg);
}
}
@Configuration
@RabbitListener(queues = "fanout.A")//监听器监听指定的Queue
public class ListenerFanout {
private static final Logger LOGGER = LoggerFactory.getLogger(ListenerFanout.class);
@RabbitHandler
public void process(@Payload String foo) {
LOGGER.info("Listener: " + foo);
}
}Fanout模式下,所有绑定fanout交换机的队列,都能收到消息。
Kafka
Kafka简介
Kafka是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。

如上图所示,一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
Kafka代理
与其它消息系统不同,Kafka代理是无状态的。这意味着消费者必须维护已消费的状态信息。这些信息由消费者自己维护,代理完全不管。这种设计非常微妙,它本身包含了创新。
- 从代理删除消息变得很棘手,因为代理并不知道消费者是否已经使用了该消息。Kafka创新性地解决了这个问题,它将一个简单的基于时间的SLA应用于保留策略。当消息在代理中超过一定时间后,将会被自动删除。
- 这种创新设计有很大的好处,消费者可以故意倒回到老的偏移量再次消费数据。这违反了队列的常见约定,但被证明是许多消费者的基本特征。
MQ性能对比及选型
MQ性能对比

从社区活跃度
按照目前网络上的资料,RabbitMQ 、activeM 、ZeroMQ 三者中,综合来看,RabbitMQ 是首选。
持久化消息比较
ZeroMq 不支持,ActiveMq 和RabbitMq 都支持。持久化消息主要是指我们机器在不可抗力因素等情况下宕机了,消息不会丢失的机制。
综合技术实现
可靠性、灵活的路由、集群、事务、高可用的队列、消息排序、问题追踪、可视化管理工具、插件系统等等。
RabbitMq / Kafka 最好,ActiveMq 次之,ZeroMq 最差。当然ZeroMq 也可以做到,不过自己必须手动写代码实现,代码量不小。尤其是可靠性中的:持久性、投递确认、发布者证实和高可用性。
高并发
毋庸置疑,RabbitMQ 最高,原因是它的实现语言是天生具备高并发高可用的erlang 语言。
比较关注的比较, RabbitMQ 和 Kafka
RabbitMq 比Kafka 成熟,在可用性上,稳定性上,可靠性上, RabbitMq 胜于 Kafka (理论上)。RabbitMQ使用ProtoBuf序列化消息。极大的方便了Consumer的数据高效处理,与XML相比,ProtoBuf有以下优势:
1.简单
2.size小了3-10倍
3.速度快了20-100倍
4.易于编程
5.减少了语义的歧义.
ProtoBuf具有速度和空间的优势,使得它现在应用非常广泛。
另外,Kafka 的定位主要在日志等方面, 因为Kafka 设计的初衷就是处理日志的,可以看做是一个日志(消息)系统一个重要组件,针对性很强,所以 如果业务方面还是建议选择 RabbitMq 。
还有就是,Kafka 的性能(吞吐量、TPS )比RabbitMq 要高出来很多。
选型最后总结:
如果我们系统中已经有选择 Kafka,或者 RabbitMq,并且完全可以满足现在的业务,建议就不用重复去增加和造轮子。
可以在 Kafka 和 RabbitMq 中选择一个适合自己团队和业务的,这个才是最重要的。但是毋庸置疑现阶段,综合考虑没有第三选择。
参考
你应该知道的 RPC 原理
远程调用服务(RPC)和消息队列(Message Queue)对比及其适用/不适用场合分析
基于高可用配置的RabbitMQ集群实践
RabbitMQ(五)高可用 – Highly Available Queues
RPC和MQ各自适合的应用场景
为什么会需要消息队列(MQ)?
ActiveMQ消息传送机制以及ACK机制详解
JMS简介与ActiveMQ实战
kafka设计解析
Kafka剖析(一):Kafka背景及架构介绍
Apache Kafka:下一代分布式消息系统
RabbitMQ从入门到精通
RabbitMQ安装教程(Windows/Linux都有)
我的码云地址: