CUDA学习--矩阵乘法的并行运算
1. CUDA学习步骤
- CPU实现
a*b = c的矩阵乘法(矩阵尺寸是n*m的,n和m大于1000) - 下载 https://developer.nvidia.com/cuda-downloads,安装好cuda
- 将cpu代码移植到cuda。将CPU值传入GPU,使用cuda计算,与cpu结果对比。
- 优化思路1:将矩阵分块进行计算
- 优化思路2:使用share memory进行优化
- 优化思路3:将数据绑定在texture上
2. CPU实现的矩阵乘法
废话不多说,直接上源码
/* CPUMatMultiply:CPU下矩阵乘法
* a:第一个矩阵指针,表示a[M][N]
* b:第二个矩阵指针,表示b[N][S]
* result:结果矩阵,表示为result[M][S]
*/
void CPUMatMultiply(const int * a,const int * b, int *result,const int M,const int N,const int S)
{
for (int i = 0; i < M; i++)
{
for (int j = 0; j < S; j++)
{
int index = i * S + j;
result[index] = 0;
//循环计算每一个元素的结果
for (int k = 0; k < N; k++)
{
result[index] += a[i * N + k] * b[k * S + j];
}
}
}
}3. CUDA实现的矩阵乘法
在https://developer.nvidia.com/cuda-downloads中下载相应的CUDA安装程序,进行安装。
PS:有关CUDA的环境搭建,Hello_World工程的创建可以移步http://www.mamicode.com/info-detail-327339.html。
下面直接进入正题,矩阵乘法的移植。
从CPU上直接移植矩阵乘法到GPU上是非常简单的,不需要for循环,直接通过CUDA线程的id号,即threadIdx.x和threadIdx.y即可操作相应的数据。
gpu矩阵乘法核函数-源代码:
/* gpuMatMultKernel:GPU下矩阵乘法核函数
* a:第一个矩阵指针,表示a[M][N]
* b:第二个矩阵指针,表示b[N][S]
* result:结果矩阵,表示result[M][S]
*/
__global__ void gpuMatMultKernel(const int *a, const int *b, int *result, const int M, const int N, const int S)
{
int threadId = (blockIdx.y * blockDim.y + threadIdx.y) * gridDim.x * blockDim.x
+ blockIdx.x * blockDim.x + threadIdx.x;
if (threadId < M * S)
{
int row = threadId / S;
int column = threadId % S;
result[threadId] = 0;
for (int i = 0; i < N; i++)
{
result[threadId] += a[row * N + i] * b[i * S + column];
}
}
}其中,blockIdx、blockDim、threadIdx、gridDim都是CUDA的内置变量。
blockIdx、threadIdx:分别CUDA中线程块的ID、线程的ID。
blockDim、gridDim:分别是CUDA中线程块的维度,线程网格的维度。
if语句是为了判断是否是对矩阵中的数据进行操作,防止在当线程threadId超过了M*S时,使用result[threadId]出现越界行为。
后续的操作则是矩阵乘法的简单实现。
4. 程序优化1:共享内存分块运算
CUDA C支持共享内存。关键字__shared__添加到声明中,这将使这个变量驻留在共享内存中。当声明变量为shared变量时,线程块中的每一个线程都共享这块内存,使得一个线程块中的多个线程能够在计算上进行通信和协作。而且,共享内存缓冲区驻留在物理GPU上,而不是驻留在GPU之外的系统内存中。因此,在访问共享内存时的延迟要远远低于访问普通缓冲区的延迟,提高了效率。
使用共享内存的核函数:
/* gpuMatMultWithSharedKernel:GPU下使用shared内存的矩阵乘法
* a:第一个矩阵指针,表示a[height_A][width_A]
* b:第二个矩阵指针,表示b[width_A][width_B]
* result:结果矩阵,表示result[height_A][width_B]
*/
template<int BLOCK_SIZE>
__global__ void gpuMatMultWithSharedKernel(const int *a, const int *b, int *result, const int height_A, const int width_A, const int width_B)
{
int block_x = blockIdx.x;
int block_y = blockIdx.y;
int thread_x = threadIdx.x;
int thread_y = threadIdx.y;
if ((thread_y + block_y * blockDim.y) * width_B + block_x * blockDim.x + thread_x >= height_A * width_B)
{
return;
}
const int begin_a = block_y * blockDim.y * width_A;
const int end_a = begin_a + width_A - 1;
const int step_a = blockDim.x;
const int begin_b = block_x * blockDim.x;
const int step_b = blockDim.y * width_B;
int result_temp = 0;
for (int index_a = begin_a, int index_b = begin_b;
index_a < end_a; index_a += step_a, index_b += step_b)
{
__shared__ int SubMat_A[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int SubMat_B[BLOCK_SIZE][BLOCK_SIZE];
SubMat_A[thread_y][thread_x] = a[index_a + thread_y * width_A + thread_x];
SubMat_B[thread_y][thread_x] = b[index_b + thread_y * width_B + thread_x];
__syncthreads();
for (int i = 0; i < BLOCK_SIZE; i++)
{
result_temp += SubMat_A[thread_y][i] * SubMat_B[i][thread_x];
}
__syncthreads();
}
int begin_result = block_y * blockDim.y * width_B + begin_b;
result[begin_result + thread_y * width_B + thread_x] = result_temp;
}矩阵乘法的并行运算,每次计算矩阵的一块数据。利用共享内存的共享功能,每次将一块数据保存到共享内存中使得一个线程块同时调用数据进行计算当前块相对应得矩阵乘法结果值。
- 代码
__shared__ int SubMat_A中的__shared__声明变量SubMat_A为共享内存中保存的变量。然后将数组中的数据提取到变量SubMat_A中保存在共享内存。 __syncthreads()对线程块中的线程进行同步,确保对__shared__进行下面的操作时上面的操作已经完成。- 两个
for循环完成了当前线程块对应矩阵子块的乘法结果计算。
注意:CUDA架构将确保,除非线程块中的每个线程都执行了__syncthreads(),否则没有任何线程能执行__syncthreads()之后的指令。例如:
if (cacheIndex < i){
cache[cacheIndex] += cache[i];
__syncthreads();
}此时,如果有线程中的cacheIndex>i则会出现一直等待的情况。
5. 程序优化2:纹理内存的运用
纹理内存,CUDA C程序中的另一种只读内存。纹理内存是专门为那些在内存访问模式中存在大量空间局部性的图形应用程序而设计的。在某个计算应用程序中,这意味着一个线程读取的位置可能与邻近线程读取的位置“非常接近”,如下图所示。
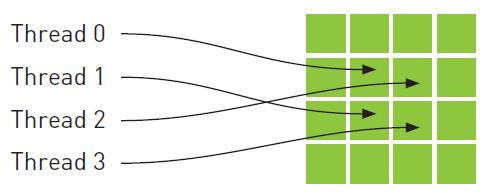
从数学的角度看,这四个地址并非连续的,在一般的CPU缓存模式中,这些地址将不会缓存。但由于GPU纹理缓存是专门为了加速这种访问模式而设计的,因此如果在这种情况中使用纹理内存而不是全局内存,那么将会获得性能提升。
使用纹理内存的核函数-源代码:
/* gpuMatMultWithTextureKernel:GPU下使用texture内存的矩阵乘法
* result:结果矩阵,表示为result[M][S];
* M:表示为矩阵A与矩阵result的行数
* N:表示矩阵A的列数,矩阵B的行数
* S:表示矩阵B和矩阵result的列数
*/
__global__ void gpuMatMultWithTextureKernel(int * result, const int M, const int N, const int S)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
if (offset < M * S)
{
int a = 0, b = 0;
int temp_result = 0;
for (int i = 0; i < N; i++)
{
a = tex1Dfetch(texA, y * N + i);
b = tex1Dfetch(texB, i * S + x);
temp_result += a * b;
}
result[offset] = temp_result;
}
}纹理内存的运用与普通内存运用时的算法大致相同,只不过数据是在核函数中调用tex1Dfetch从纹理中提取。
在使用纹理内存时,主要注意的是纹理内存的使用。
首先,需要将输入的数据声明为texture类型的引用。
注意,输入的数据是什么类型,相应的纹理也应该与之一致。并且纹理引用必须声明为文件作用域内的全局变量。
//这些变量将位于GPU上
texture<int> texA;
//二维纹理引用,增加了代表维数的参数2
texture<float, 2> texB;在为这两个缓冲区分配了GPU内存后,需要通过cudaBindTexture将这些变量绑定到内存缓冲区。这相当于告诉CUDA运行时两件事:
- 我们希望将指定的缓冲区作为纹理来使用。
- 我们希望将纹理引用作为纹理的“名字”。
cudaBindTexture(NULL, texA, dev_a, desc, M * N * sizeof(int));
cudaBindTexture(NULL, texB, dev_b, desc, N * S * sizeof(int));在绑定纹理时,CUDA运行时要求提供一个cudaChannelFormatDesc。此时,需要调用cudaCreateChannelDesc。
最后,通过cudaUnbindTexture()函数来取消纹理的绑定。
6.总结
矩阵乘法计算中,运行时间上有:共享内存 < 纹理内存 ≈ 普通GPU移植 < CPU运算。
具体源代码https://github.com/ZYMing/CUDA_Samples/blob/master/MatMulti/MatMulti.cu。