阅读笔记:自动发现,关系估计,学习上千个类别的语义属性,扩展zero-shot learning
论文地址:https://arxiv.org/pdf/1704.03607.pdf
本文已经被CVPR2017接收,针对的是基于属性的识别模型(attribute-based recognition models)中,属性词典(attribute vocabulary)和类与属性的关系(class-attribute associations)需要专业人士人工定义的问题,比如基于属性的识别算法的经典文章之一《Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer》(可参考上一篇博文)所提供的方法。作者提出了一种端对端(end-to-end)的非监督属性学习算法。首先,基于文本语料库自动发现显著的多样性和区分性强的词典,并且该词典需要与人类认知中的语义概念属性高度相关。之后,作者利用深度卷积神经网络最优化了类与属性之间的关系(class-attribute associations),并使用linguistic prior方法使得模型对噪声和缺失数据具有抵抗性,增强了模型的鲁棒性。该方法在三个数据集(ImageNet、Animals with Attributes、aPascal/aYahoo)上实现的zero-shot learning均得到目前最好水平。作者也公开了在ImageNet上学习到的高维特征。
主要的贡献:1、提出了一种新的从文本中挖掘属性的方法,挖掘到的属性具有 “区分性”、“多样性”、“显著性”并且与人类认知的语义概念属性高度相关;
2、提出了一种基于深度卷积神经网络的建立属性与类别之间联系的方法,并且考虑了文本语料库中的 噪声和缺失值;
3、实现了在三个数据集上的zero-shot learning的最好效果。
4、公开了在ImageNet上学习到的高维属性。(属性数据的下载地址为:http://cvhci.anthropomatik.kit.edu/~zalhalah/)
先解释一下zero-shot learning。Zero-shot learning简单来说就是识别从未见过的数据类别,即训练的分类器不仅仅能够在识别出训练集中已有的数据类别,还可以对于未见过的数据类别进行区分。这是一个很有用的功能,使得计算机能够有知识迁移的能力,并无需任何样本标签,很符合现实生活中海量数据的存在形式。
算法内容
主要分为三个部分:属性的发现、类与属性之间关系的发现和基于属性的样本分类。
发现和学习语义属性
对问题进行数学形式化:设文本语料库为D,对象类别为C,总共有M类,设W为从D中学习到的词典,算法的目标是选择一个子集A属于W,能够最好地描述C,即:
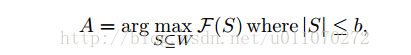
其中,b为词典的大小,F为子集S的描述函数,优化该函数可以选择出最优的子集A,所以这部分的工作就是对于函数F进行建模。对于选择出来的A集合,需要具有三个性质:a)区分性:能够对类别具有很好的区分性;b)多样性:能够从多个方面对类别进行描述;c)显著性:能够代表人类的认知。
a.区分性:设集合V={v1,...,vj}为tfidf提取的重要性特征,即vij表示词wi在文档dj中的重要性。建立一个无向全连接图G(N,E),每个结点ni都代表了一个类别ci,每条边代表了集合S中词的对于不同类别的区分能力,可写成:
![]()
对于每一个结点,设置一个环形结构eii,权重为:
![]()
令:
![]()
![]()

且设:
![]()
则目标函数可以表示为:

公式看起来比较复杂,其实这是一种利用信息熵评估区分度的方法,该公式计算的是entropy rate of a random walk ,方法来自于论文[1,2],有兴趣的同学可以进一步阅读论文进行探究。最大化上述目标函数,得到的词典即是具有高区分度能力的词典。
b.多样性:多样性的好处在于,可以使得选出的词对于所有类别都是尽量公平的,并且能够一定程度上低于bias。首先,利用非监督的概率主题模型算法(LDA[3])得到每个文档的主题。这T={T1,...,Tk}为从D中学习到的主题集合,设多样性目标函数为:
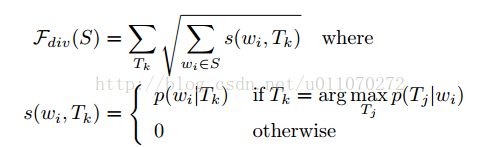
从公式中可以看出,如果添加已经选择主题相关的词,会使得系统的增益减小。这个函数同时能够选择出对于主题更加重要的词,因为一个词wi对应的p(wi|Tk)越大,会得到越大的增益。同时,它能够一定程度上避免冗余,因为同类词属于同一个主题,该函数限制了同一类主题相关词的增加。
c.显著性:例如“leg”,“yellow”,“transparent”等词是具有显著性的,因为它们都有很清晰的语义概念,相比下,“become”,“allow”等词,它们代表的语义就不显著。可以借助junk topic实现显著性词的发现。Junk topic 是指文中没有包含特别明显的语义主题,通过测量与junk topic 之间的距离,可以得到重要的主题,从而发现具有显著性的词。表1列出了根据topic重要性的排列结果,越靠上的文本表示的主题意义越明显和清晰。

表1 主题显著性表
可以设insig(T)为最低10%的topic,定义显著性损失函数为:

其中gama控制词wi对主题的非重要性的贡献值,即当选择的词是“become”、“allow”之类的词的时候,损失变大。因此,该损失函数能够选择具有显著性的词。
Submodular optimization
该方法来自于论文[4],如果一个函数F满足边际效益递减的情况,即有:
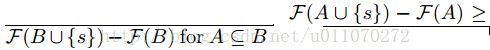
则,该函数被称为submodular函数。就是说新元素加入地越晚,其对系统的增益越小。就好像一个饿的人吃馒头,吃第一个的时候觉得很满足,但再多吃几个时,满足感越来越小。可以设目标优化函数为:

可以使用lazy greedy algorithm[5]对其进行求解,即假设一个空的S={},逐步向里面添加元素,每一步都保证最大化增益。
使用语言优先(linguistic prior)使得类-属性关系最优化
这里的关系,指的是类别标签与属性之间的关系,即如何用上文所找到的属性组合表示类别标签。定义类-属性关系矩阵Ml=[mij]:
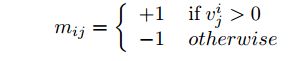
也就是利用tfidf进行简单的初始定义。这样的定义有个缺陷是文本中是存在缺省的,就比如大部分动物都有头、四肢和皮肤,在文本中就可能不会出现这些关键词,使得提取到的V可能并不好。再者,可能会将负相关系处理为正向关系,比如“老虎不生活在海里”,提取之后变为“老虎”和“海”。
利用如图1所示的网络结构,获取深层次的类-属性关系。

图 1 joint deep modal
该网络结构包含了DAP法[3],可以将损失函数定义为:
![]()
其中Lc和La分别为分类和属性的交叉熵损失,||M-Ml||1表示对于属性矩阵的约束,这么做的目的主要是将M的变化控制在一个范围内,这也被称为linguistic prior。作者在此使用的是alexnet网络。
如此,可以得到类别的属性向量的表示形式。之后可以进行属性预测模型的训练,即训练得到样本X到属性M层的映射,也是利用一个深度卷积网络进行学习,结构如图2所示。
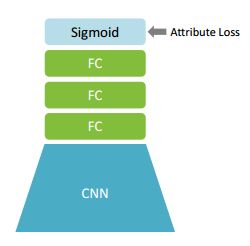
图2 attribute deep modal
利用5个卷基层和三个全连接层,最终连接一个sigmoid激活函数作为输出,同样使用交叉熵损失进行网络的训练。这一步是为了得到DAP中的s(a|x),即由X到属性层M的预测。之后就可以使用DAP预测s(a|x),这样也可以实现zero-shot learning。
实验结果
数据集ILSVR2012,使用Wikipedia API 搜集文本语料库,对于每个文本截断为500。使用tfidf方法得到向量集合V,即词对文章的重要性。使用LDA法,学习200个主题。深度属性模型的权值使用第一个深度模型的权值进行初始化。
评估所选择的属性词典的性能
作者从两个方面进行了评估:(1)通过属性获得的同类对象的相似性(2)词表自身的显著性。
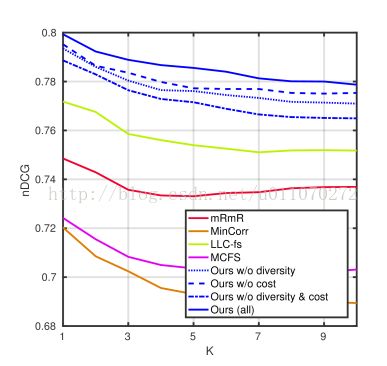
使用discounted cumulative gain(nDCG)[5]来衡量(1)。如图3所示,本文算法的效果是最好的。

属性预测
可以利用上文生成的属性,进行图片分类的任务。表3为实验结果,包括属性分类结果和类别分类结果(使用DAP方法)。具体的做法就是将图片的类别换成属性向量表示,然后利用训练好的神经网络,对属性向量进行预测,看其准确率和AP(average precision)。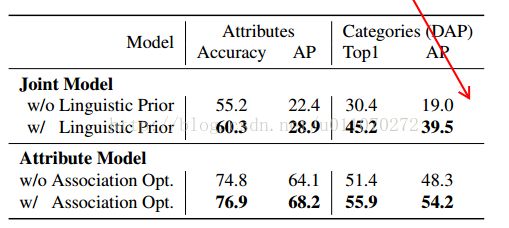

基于属性的分类器最主要的功能是进行zero-shot learning。使用的是分割好的ILSVRC2010数据集,共800个训练集,200个测试集。表4为实验结果,该方法要明显比目前其他的方法效果好,这里的1000labels是为了检测算法对于已见样本类别的倾向性,即将训练集中的类别也作为测试预测时的候选类别,这样做效果肯定是会降低的,因为模型是有训练类别训练出来的,所以会更加偏向于训练类别。如果将测试类别的属性表示的分布情况,即知道其方差和均值,可以在最终的分类中运用该方差和均值,能够得到ours-BT的结果,结果是会更好的。作者这么做应该是为了测试一下预测样本分布对结果的影响,但在现实的问题中,我们通常是不会知道未知类别样本的属性分布的。表4的最后两行表明了本方法利用深度网络对类-属性关系建模的重要性,上文已经提到了它在监督学习情况下的作用,这里表明了它在zero-shot learning问题上的作用。



其实本文提出的算法思路是基于论文[3]的算法框架所提出的,感兴趣的同学可以参考上一篇博文。对于[3]中需要人工建立的属性表示和类-属性关系的表示,实行了自动化,提出属性预测的深度模型,并取得了现在最好的效果。
回顾一下算法的流程:利用wikipedia的文本语料库生成最优的属性表(用词表示),利用深度卷积网络实现类-属性的关系表示,也就是将类更好地表示为属性向量的形式,并在此过程中加入linguistic prior约束;利用另一个深度网络进行样本到属性向量的预测,使用DAP算法得到最终类别的预测结果。
从本工作的研究思路可以看出,它的研究重点在于改进之前算法框架中部分步骤的效果,这种方式实际上在论文[3]作者的总结中就有提及。该工作应该可以扩展到对视频对象的zero-shot learning的工作中。