hadoop1.x与hadoop2.x在HDFS和MapReduce上的区别
HDFS改进
·hadoop1.x的HDFS体系架构
在Hadoop1.x中的NameNode只可能有一个,虽然可以通过SecondaryNameNode与NameNode进行数据同步备份,但是总会存在一定的延时,如果NameNode挂掉,但是如果有部份数据还没有同步到SecondaryNameNode上,还是可能会存在着数据丢失的问题。
下面顺便介绍一下SecondaryNameNode在Hadoop1.x的作用:(1).HA(高可靠性)的一个解决方案,但不支持热备,配置即可。
(2).执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage.
切换——下载——合并——发送
如图:
Hadoop1.x体系HDFS架构如图:
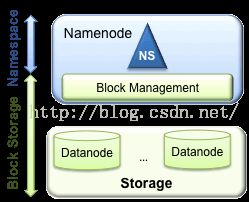
该架构包含两层:Namespace 和 Block Storage Service;
其中,Namespace 层面包含目录、文件以及块的信息,支持对Namespace相关文件系统的操作,如增加、删除、修改以及文件和目录的展示;
而Block Storage Service层面又包含两个部分:
①Block Management(块管理)维护集群中DataNode的基本关系,它支持数据块相关的操作,如:创建数据块,删除数据块等,同时,它也会管理副本的复制和存放。
②Physical Storage(物理存储)存储实际的数据块并提供针对数据块的读写服务。
当前HDFS架构只允许整个集群中存在一个Namespace,而该Namespace被仅有的一个NameNode管理。这个架构使得HDFS非常容易实现,但是,它(见上图)在具体实现过程中会出现一些模糊点,进而导致了很多局限性(下面将要详细说明),当然这些局限性只有在拥有大集群的公司,像baidu,腾讯等出现。
Hadoop1.x的HDFS架构的局限:
(1)Block Storage和namespace高耦合
当前namenode中的namespace和block management的结合使得这两层架构耦合在一起,难以让其他可能namenode实现方案直接使用block storage。
(2)NameNode扩展性
HDFS的底层存储是可以水平扩展的(解释:底层存储指的是datanode,当集群存储空间不够时,可简单的添加机器已进行水平扩展),但namespace不可以。当前的namespace只能存放在单个namenode上,而namenode在内存中存储了整个分布式文件系统中的元数据信息,这限制了集群中数据块,文件和目录的数目。
(3)NameNode性能
文件操作的性能制约于单个Namenode的吞吐量,单个Namenode当前仅支持约60K的task,而下一代Apache MapReduce将支持多余100K的并发任务,这隐含着要支持多个Namenode。
(4)隔离性
现在大部分公司的集群都是共享的,每天有来自不同group的不同用户提交作业。单个namenode难以提供隔离性,即:某个用户提交的负载很大的job会减慢其他用户的job,单一的namenode难以像HBase按照应用类别将不同作业分派到不同namenode上。
1.1HDFS Federation(HDFS联邦)
(1)全新的Feration架构
在Hadoop2.x中,HDFS的变化主要体现在增强了NameNode的水平扩展(Horizontal Scalability)及高可用性(HA)->【这不就是针对我们刚刚提到到的Hadoop1.x HDFS架构的局限性而做的改进,么么嗒!】,可以同时部署多个NameNode,这些NameNode之间是相互独立,也就是说他们不需要相互协调,DataNode同时在所有NameNode中注册,作为他们共有的存储节点,并定时向所有的这些NameNode发送心跳块使用情况的报告,并处理所有NameNode向其发送的指令。该架构如图2所示:
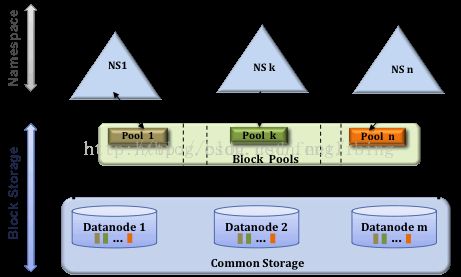
该架构引入了两个新的概念:存储块池(Block Pool) 和 集群ID(ClusterID);
①一个Bock Pool 是块的集合,这些块属于一个单一的Namespace。DataNode存储着集群中所有Block Pool中的块。Block Pool的管理相互之间是独立的。这意味着一个Namespace可以独立的生成块ID,不需要与其他Namespace协调。一个NameNode失败不会导致Datanode的失败,这些Datanode还可以服务其他的Namenode。
一个Namespace和它的Block Pool一起称作命名空间向量(Namespace Volume)。这是一个自包含单元。当一个NameNode/Namespace删除后,对应的Block Pool也会被删除。当集群升级时,每个Namespace Volume也会升级。
②集群ID(ClusterID)的加入,是用于确认集群中所有的节点,也可以在格式化其它Namenode时指定集群ID,并使其加入到某个集群中。
(2)HDFS Federation与老HDFS架构的比较
①老HDFS架构只有一个命名空间(Namespace),它使用全部的块。而HDFS Federation 中有多个独立的命名空间(Namespace),并且每一个命名空间使用一个块池(block pool)。
②老HDFS架构中只有一组块。而HDFS Federation 中有多组独立的块。块池(block pool)就是属于同一个命名空间的一组块。
③老HDFS架构由一个Namenode和一组datanode组成。而HDFS Federation 由多个Namenode和一组Datanode,每一个Datanode会为多个块池(block pool)存储块。
1.2 NameNode的HA
Hadoop中的NameNode好比是人的心脏,非常重要,绝对不可以停止工作。在Hadoop1.x时代,只有一个NameNode。如果该NameNode数据丢失或者不能工作,那么整个集群就不能恢复了。这是Hadoop1.x中的单点问题,也是Hadoop1.x不可靠的表现,如图1所示。Hadoop2的出现解决了这个问题,也被称为HA。
Hadoop2中HDFS的HA主要指的是可以同时启动2个NameNode。其中一个处于工作(Active)状态,另一个处于随时待命(Standby)状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。在hadoop的运行过程中,有时候会发生一些意想不到的事情,例如磁盘阵列的损坏,机器的宕机错误,以及及群管理员想对集群进行升级配置,此时我们会联想到hadoop HA(高可用性)。具体说,例如就是在一个集群上同时运行两个namenode,一个是active状态,另一个是standby状态。当节点运行失败或者需要停止的时候,就是启动那个备份的namenode,standbynamenode的功能和active完全相同,要达到这种水平,需要做下面的两件事情。第一:我们必须要同步日志文件,也就是说activenamenode的运行中的镜像文件以及日志需要在两个namenode之间进行同步,这里就引入了Journal这个概念。当active节点运行的时候,需要把自己的日志文件时时的写入journal中去,于此同时standbynamenode就从其中读取日志文件。任何一个时刻,只有有一个写,一个读。这样还不够,我们还需要让datanode也要与standBynamenode进行时刻的通信。有了上面的这两点,我们就可以在一个集群上同时运行两个namenode来保证集群的高可用性。(FailoverController:故障管理控制器)。
如图3所示,它展示了一个在Hadoop2下实现HA的一种方式结构:
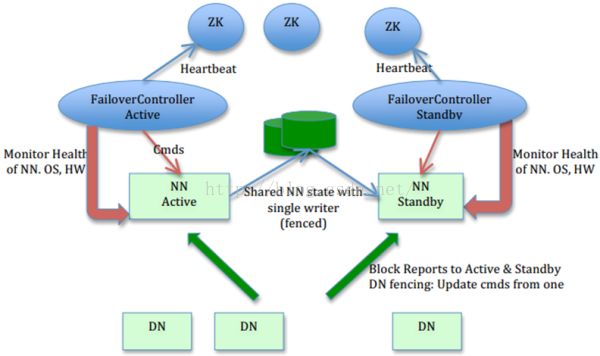
下面对上图做一下简单的介绍:
(1)这些NameNode之间通过共享存储同步edits信息,保证数据的状态一致。多个NameNode之间共享数据,可以通过Network File System(NFS)或者Quorum Journal Node。前者是通过Linux共享的文件系统,属于操作系统层面的配置;后者是Hadoop自身的东西,属于软件层面的配置。
(2)DataNode同时向两个NameNode汇报块信息。这是让Standby NameNode保持集群最新状态的必需步骤。
(3)使用Zookeeper来进行心跳监测监控,在Active NameNode失效时自动切换Standby NameNode为Active状态。
主要在两方面影响了HDFS的可用性:
(1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个集群将无法利用,直到NN被重新启动;
(2)、在可预知的情况下,比如NN所在的机器硬件或者软件需要升级,将导致集群宕机。
HDFS的高可用性将通过在同一个集群中运行两个NN(active NN & standby NN)来解决上面两个问题,这种方案允许在机器破溃或者机器维护快速地启用一个新的NN来恢复故障。
在典型的HA集群中,通常有两台不同的机器充当NN。在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态。Active NN负责集群中所有客户端的操作;而StandbyNN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
为了让 Standby NN的状态和Active NN保持同步,即元数据保持一致,它们都将会和JournalNodes守护进程通信。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上(通过editslog持久化存储),而StandbyNN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间。一旦ActiveNN出现故障,Standby NN将会保证从JNs中读出了全部的Edits,然后切换成Active状态。Standby NN读取全部的edits可确保发生故障转移之前,是和ActiveNN拥有完全同步的命名空间状态。
为了提供快速的故障恢复,StandbyNN也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的Database将配置好Active NN和StandbyNN的位置,并向它们发送块文件所在的位置及心跳。
Hadoop2.2.0中HDFS的高可用性实现原理
在任何时候,集群中只有一个NN处于Active 状态是极其重要的。否则,在两个Active NN的状态下NameSpace状态将会出现分歧,这将会导致数据的丢失及其它不正确的结果。为了保证这种情况不会发生,在任何时间,JNs只允许一个 NN充当writer。在故障恢复期间,将要变成Active 状态的NN将取得writer的角色,并阻止另外一个NN继续处于Active状态。
为了部署HA集群,你需要准备以下事项:
(1)、NameNodemachines:运行Active NN和Standby NN的机器需要相同的硬件配置;
(2)、JournalNode machines:也就是运行JN的机器。JN守护进程相对来说比较轻量,所以这些守护进程可以可其他守护线程(比如NN,YARN ResourceManager)运行在同一台机器上。在一个集群中,最少要运行3个JN守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3 个以上的JN,但是为了增加系统的容错能力,你应该运行奇数个JN(3、5、7等),当运行N个JN,系统将最多容忍(N-1)/2个JN崩溃。在HA集群中,Standby NN也执行namespace状态的checkpoints,所以不必要运行Secondary NN、CheckpointNode和BackupNode;事实上,运行这些守护进程是错误的。