Jacobian矩阵,Hessian矩阵和牛顿法
转自 : http://jacoxu.com/jacobian%E7%9F%A9%E9%98%B5%E5%92%8Chessian%E7%9F%A9%E9%98%B5/
Jacobian矩阵
在向量分析中, 雅可比矩阵是一阶偏导数以一定方式排列成的矩阵, 其行列式称为雅可比行列式.
雅可比矩阵的重要性在于它体现了一个可微方程与给出点的最优线性逼近. 因此, 雅可比矩阵类似于多元函数的导数.
假设 F:Rn→Rm 是一个从欧式n维空间转换到欧式m维空间的函数. 这个函数由m个实函数组成: y1(x1,…,xn),…,ym(x1,…,xn). 这些函数的偏导数(如果存在)可以组成一个m行n列的矩阵, 这就是所谓的雅可比矩阵:
本质上是一个列向量对列向量求偏微分。此矩阵表示为:
JF(x1,...,xn) 或者 ∂(y1,...,ym)∂(x1,...,xn)
如果 P 是 Rn 中的一点, F 在 P 点可微分, 那么在这一点的导数由 JF(P) 给出(这是求该点导数最简便的方法). 在此情况下, 由 F(P) 描述的线性算子即接近点 P 的 F 的最优线性逼近, x 逼近于 P :
F(x)≈F(p)+JF(p)⋅(x–p)
Hessian矩阵
在数学中, 海森矩阵(Hessian matrix或Hessian)是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵, 此函数如下:
f(x1,x2,...,xn)
如果f的所有二阶导数都存在, 那么f的海森矩阵即:
H(f)ij(x)=DiDjf(x)
其中H(f)为:
海森矩阵在牛顿法中的应用
一般来说, 牛顿法主要应用在两个方面, 1, 求方程的根; 2, 最优化.
1.求解方程
并不是所有的方程都有求根公式, 或者求根公式很复杂, 导致求解困难. 利用牛顿法, 可以迭代求解.
原理是利用泰勒公式, 在 x0 处展开, 且展开到一阶, 即
求解方程 f(x)=0 ,即 f(x0)+(x–x0)f′(x0)=0 求解得 x=x1=x0–f(x0)/f′(x0) 因为这是利用泰勒公式的一阶展开, f(x)=f(x0)+(x–x0)f′(x0) 处并不是完全相等, 而是近似相等, 这里求得的 x1 并不能让 f(x)=0 ,只能说 f(x1) 的值比 f(x0) 更接近 f(x)=0 于是乎, 迭代求解的想法就很自然了, 可以进而推出 xn+1=xn–f(xn)/f′(xn) 通过迭代, 这个式子必然在 f(x∗)=0 的时候收敛. 整个过程如下图:

2. 最优化问题
在最优化的问题中, 线性最优化至少可以使用单纯形法(或称不动点算法)求解, 但对于非线性优化问题, 牛顿法提供了一种求解的办法. 假设任务是优化一个目标函数 f , 求函数 f 的极大极小问题, 可以转化为求解函数 f 的导数 f'=0 的问题, 这样求可以把优化问题看成方程求解问题 (f′=0) . 剩下的问题就和第一部分提到的牛顿法求解很相似了.
这次为了求解 f'=0 的根, 把 f(x) 的泰勒展开, 展开到2阶形式:
这个式子是成立的, 当且仅当 Δx 无限趋近于0时 f(x+Δx)=f(x) , 约去这两项, 并对余项式 f′(x)Δx+12f”(x)Δx2=0 对 Δx 求导.此时上式等价于:
求解 :
得出迭代公式:
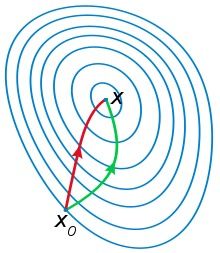
一般认为牛顿法可以利用到曲线本身的信息, 比梯度下降法更容易收敛(迭代更少次数), 如下图是一个最小化一个目标方程的例子, 红色曲线是利用牛顿法迭代求解, 绿色曲线是利用梯度下降法求解.
在上面讨论的是2维情况, 高维情况的牛顿迭代公式是:
其中H是hessian矩阵, 定义见上.
高维情况依然可以用牛顿迭代求解, 但是问题是Hessian矩阵引入的复杂性, 使得牛顿迭代求解的难度大大增加, 但是已经有了解决这个问题的办法就是Quasi-Newton method, 不再直接计算hessian矩阵, 而是每一步的时候使用梯度向量更新hessian矩阵的近似.