爬虫做js逆向分析的思路
1. 为什么要做逆向

正常我们访问一个网站是由html css js 文件组成的,下图是某网站的正常访问。
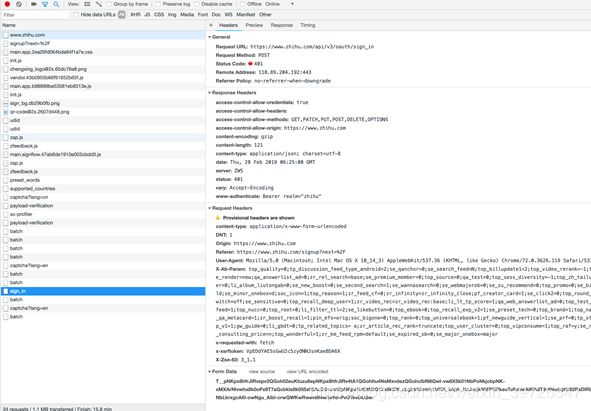
当然我们也可以看到是谁调用了这个请求执行了什么(2图为某网站登录链接)
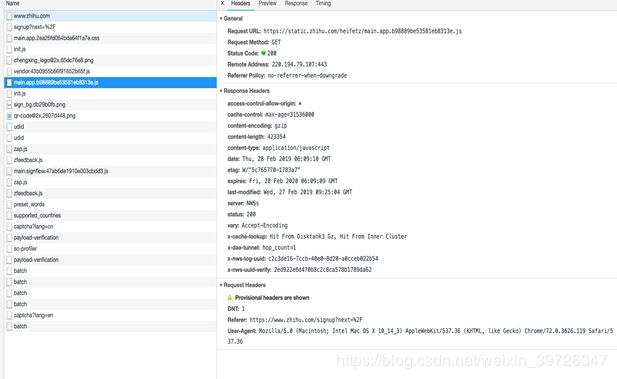
分析URL
我们可以看到这个链接他的请求参数,传输方式等。我们可以看到左图和右图的差距;同样的请求方式和fromdata会有这样的差距。如果有些经验的同学就会去找相关js了

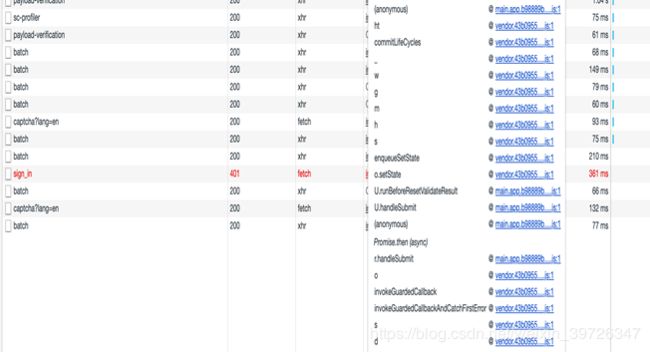
如何快速查找js
- 我们可以在搜索查找或者链接js调用中查找相关js
- 可以看到出现了两个搜索到的结果
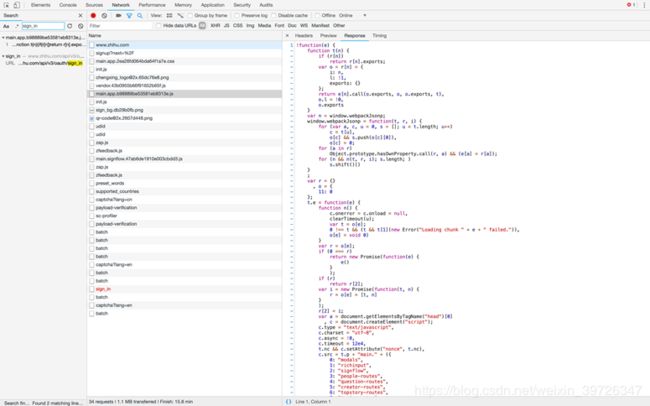
如何分析调用及复写js
如何准确无误的找到相关加密以及调试
我们在找到相关js后需要去找到一些疑似加密的函数,比如哈希,base64等
还可以从链接调用开始着手,这都是可以的。并没有一定哪种更加简便。这是其中的一个加密函数被我提取出来了。像这种加密很少的js我们可以用python复写,但是一旦加密函数过于庞大就需要将js抽取出用python+node或是webdriver来执行相关函数。
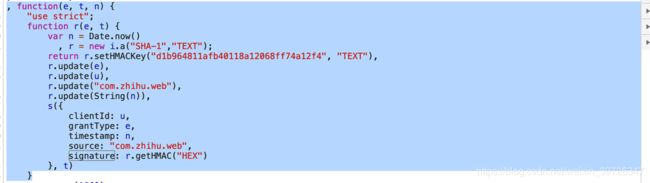
python复写hmac加密
import hmac
def get_singa_true(timestamp):
sha1 = hmac.new("d1b964811afb40118a12068ff74a12f4".encode('utf8'), digestmod='sha1')
sha1.update("password".encode('utf8'))
sha1.update("c3cef7c66a1843f8b3a9e6a1e3160e20".encode('utf8'))
sha1.update("com.zhihu.web".encode('utf8'))
sha1.update(str(timestamp).encode('utf8'))
return sha1.hexdigest()
另外一个混淆加密函数的查找
查找方法方式和调试技巧


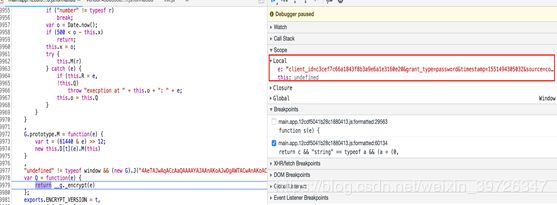
-
下面是我提取出的另外一个加密函数大概有400多行
-
这个函数因为使用了windows对象,所以构造了相关的函数
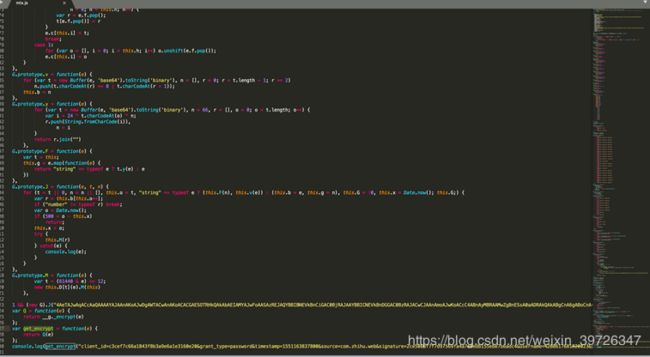
这么大的混淆加密js我们如何处理呢?
-
400行的混淆js用python复写其实也不是不能,但是开发时间和破解效率都是一个很关键的问题
-
如果说开发时间紧急,那么此时我们就需要使用其他的方式来执行这段js
**第一种:**使用selenium+webdriver来执行本地文件,然后调用本地html上的js运行
**第二种:**使用python下的库exec.js来调用node来执行
如何验证这个混淆加密函数是否有效?
我们可以将这个js函数写到一个空白的html中,再用console.log进行调试。查看是否结果相同



使用node执行混淆js

使用node执行混淆js

上面几图中分别有如下几个坑
- 他会判断window对象是否为undifined
- 一个浏览器aotb的解码函数,需要从node中找到对应函数
- 需要构造一个windows对象,和部分变量;函数
相关代码
测试混淆加密函数
import execjs, os
os.environ["EXECJS_RUNTIME"] = "Node"
IMAGE_LIST = [[17, 25.1875], [44, 28.1875], [69, 28.1875], [93, 25.1875], [109, 28.1875], [140, 26.1875],
[177, 13.1875]]
def get_js(js_location):
f = open(js_location, 'r', encoding='UTF-8')
line = f.readline()
htmlstr = ''
while line:
htmlstr = htmlstr + line
line = f.readline()
return htmlstr
def get_encrypt(ctx, all_args):
return ctx.call('get_encrypt', all_args)
if __name__ == '__main__':
all_args = "client_id=c3cef7c66a1843f8b3a9e6a1e3160e20&grant_type=password×tamp=1551496362379&source=com.zhihu.web&signature=b92f67a96cc1fde5db2a93ed87a482a6ceda29ee&username=%2B8613252798967&password=123456qwe&captcha=&lang=cn&ref_source=homepage&utm_source="
ctx = execjs.compile(get_js('jiami.js'))
post_ctx = ctx.call("Q", all_args)
print(post_ctx)
倒立图片的验证码坐标
import requests, json, base64,urllib.parse
from io import BytesIO
from PIL import Image
IMAGE_LIST = [[17, 25.1875], [44, 28.1875], [69, 28.1875], [93, 25.1875], [109, 28.1875], [140, 26.1875],
[177, 13.1875]]
def get_image_addr(img_str):
if "," in img_str:
img_str = img_str.replace(",", ",")
img_list = img_str.split(",")
captcha = {"img_size": [200, 44], "input_points": []}
for i in img_list:
captcha['input_points'].append(IMAGE_LIST[int(i) - 1])
return captcha
url = "https://www.zhihu.com/api/v3/oauth/captcha?lang=cn"
headers = {
"Referer": "https://www.zhihu.com/signup?next=%2F",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36",
"x-requested-with": "fetch",
}
response = session.get(url, headers=headers)
print(response.text)
response = session.put(url, headers=headers)
print(response.status_code)
content = json.loads(response.content.decode())
image = Image.open(BytesIO(base64.b64decode(content['img_base64'])))
image.show()
captcha = input("请输入图片验证码 倒立图片请输入第几个文字以,为间隔(输入数字)")
image.close()
captcha = get_image_addr(captcha)
captcha = urllib.parse.quote(json.dumps(captcha).replace(" ", ""))
url = "https://www.zhihu.com/api/v3/oauth/captcha?lang=cn"
response = session.post(url, headers=headers, data={"input_text": captcha})
print(response.text)