【Python 网络爬虫】使用 urllib 爬取网页源码、图片和视频
目录
-
- 1.网络爬虫简介
- 2.使用urllib爬虫
-
- 2.1 发送请求
- 2.2 数据保存和异常处理
- 2.3 模拟浏览器发起请求
- 2.4 添加请求头
- 2.5 认证登录
- 3.下载图片和视频
- 4.拓展-万能视频下载
1.网络爬虫简介
前面介绍了HTML基础和CSS基础,了解了页面元素构成的基础上,这对于爬虫来说,看到源代码也能熟悉一二,并且也能更好地定位到所需要的数据。接下来带大家更深入了解爬虫相关知识。
网络爬虫是一种按照一定的规则,自动爬去万维网信息的程序或脚本。一般从某个网站某个网页开始,读取网页的内容,同时检索页面包含的有用链接地址,然后通过这些链接地址寻找下一个网页,再做相同的工作,一直循环下去,直到按照某种策略把互联网所有的网页都抓完为止。
网络爬虫的分类
网络爬虫大致有4种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。
- 通用网络爬虫:爬取的目标数据巨大,并且范围非常广,性能要求非常高。主要应用在大型搜索引擎中,有非常高的应用价值,或者应用于大型数据提供商。
- 聚焦网络爬虫:按照预先定义好的主题,有选择地进行网页爬取的一种爬虫。将爬取的目标网页定位在与主题相关的页面中,大大节省爬虫爬取时所需要的带宽资源和服务器资源。主要应用在对特定信息的爬取中,为某一类特定的人群提供服务。
- 增量式网络爬虫:在爬取网页的时候,只爬取内容发生变化的网页或者新产生的网页,对于内容未变化的网页,则不会爬。增量式网络爬虫在一定的程度上能够保证爬取的页面尽可能是新页面。
- 深层网络爬虫:网页按存在方式可以分为表层页面和深层页面。表层页面指不需要提交表单,使用静态的链接就能够到达的静态页面;深层页面则隐藏在表单后面,不能通过静态链接直接获取,需要提交一定的关键词之后才能获取的页面。
表单用于收集用户的输入信息,表示文档中的一个区域,此区域包含交互控件,将用户收集到的信息发送到 Web 服务器。通常包含各种输入字段、复选框、单选按钮、下拉列表等元素。在实际生活中,最常见的就是问卷调查和账号登入。
网络爬虫的作用
1)搜索引擎:为用户提供相关且有效的内容,创建所有访问页面的快照以供后续处理。使用聚焦网络爬虫实现任何门户网站上的搜索引擎或搜索功能,有助于找到与搜索主题具有最高相关性的网页。
2)建立数据集:用于研究、业务和其他目的。
- 了解和分析网民对公司或组织的行为。
- 收集营销信息,并在短期内更好地做出营销决策。
- 从互联网收集信息,分析他们并进行学术研究。
- 收集数据,分析一个行业的长期发展趋势。
- 监控竞争对手的实时变化。
网络爬虫的工作流程
预先设定一个或若干个初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获取URL,进而访问并下载该页面。
当页面下载后,页面解析器去掉页面上的HTML标记并得到页面内容,将摘要、URL等信息保存到Web数据库中,同时抽取当前网页上新的URL,推入URL队列,知道满足系统停止条件。
爬虫的矛与盾:
- 反爬机制:门户网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
- 反反爬策略:爬虫程序,可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站中相关的数据。
robots.txt协议:君子协议。规定了网站中那些数据可以被爬虫爬取,那些数据不允许被爬取。
2.使用urllib爬虫
urllib 是Python中请求URL连接的官方标准库,在Pyhton 2 中分为 urllib 和 urllib2,在Python 3 中合成为 urllib。它用于获取URL,使用urlopen函数打开获取的网页,并且可以使用各种不同的协议获取URL,常见的有以下4个模块:
- urllib.request:主要负责构造和发起网络请求,定义了适用于各种复杂情况下打开URL的函数和类。
- urllib.error:异常处理,包含urllib.request抛出的异常。
- urllib.parse:解析各种URL数据格式。
- urllib.robotparser:解析robots.txt文件。
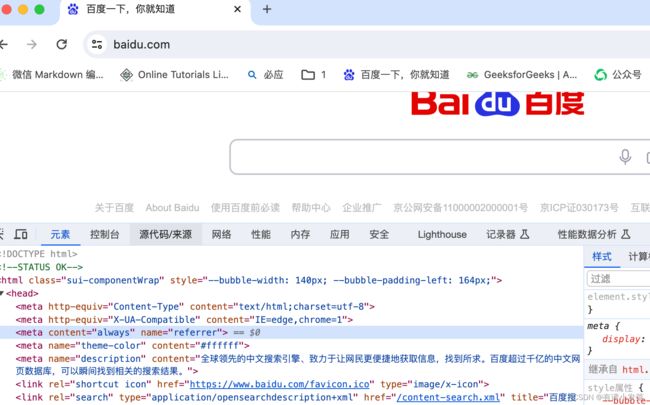
谷歌浏览器,打开百度网址:https://www.baidu.com/,使用右键点击检查,或者谷歌设置中更多工具-开发者工具,点开刷新并且点击元素,可以看到如下图:
2.1 发送请求
以百度网址为参照,使用urlopen发起请求,查看具体源码信息,执行以下命令即可。
import urllib.request # 导入模块
baidu_url = 'http://www.baidu.com' # 百度url
response = urllib.request.urlopen(baidu_url) # 发起请求,返回响应对象
msg = response.read().decode('utf-8') # 调用read方法读取数据并解码
print(msg) # 打印元素信息

2.2 数据保存和异常处理
如果网速比较慢或者所请求的网站打开时比较缓慢,可以设置一个超时限制,使用timeout参数。除此之外,可以将网页源码保存为HTML文件,还可以使用异常处理方法try…except,可参考Python 异常处理和程序调试。
新建py文件,输入以下命令,然后在终端执行该文件,如python 1.py,如果显示没有文件,说明路径不对,可以使用 cd 进入到该文件所在目录下。
import urllib.request # 导入模块
try:
baidu_url = 'http://www.baidu.com' # 百度url
response = urllib.request.urlopen(baidu_url,timeout=1) # 发起请求,返回响应对象,设置超时1s
msg = response.read().decode('utf-8') # 调用read方法读取数据并解码
save_file = open('baidu.html','w') # 将网页信息保存为html文件,可以指定绝对路径,此处文件存放在命令行所处目录下
save_file.write(msg)
save_file.close()
print('over!')
except Exception as e:
print(str(e))

如上,执行完后即可看到urllib_request目录中生成了改HTML文件,点击打开可发现和浏览器中是一致的。
2.3 模拟浏览器发起请求
使用urllib.request.Request 可以模仿浏览器访问网址,这样能避免一些简单的反爬措施。反爬一旦出发,就不能继续爬取数据了。
以京东网址为例,新建py文件,输入以下命令并执行。
import urllib.request # 导入模块
try:
jd_url = 'http://www.jd.com' # 京东url
request = urllib.request.Request(jd_url) # 返回Requests对象
response = urllib.request.urlopen(request) # 发起请求,打开网址,返回响应对象
msg = response.read().decode('utf-8') # 调用read方法读取数据并解码
save_file = open('jd.html','w') # 将网页信息保存为html文件,可以指定绝对路径,此处文件存放在命令行所处目录下
save_file.write(msg)
save_file.close()
print('over!')
except Exception as e:
print(str(e))
通过上面示例,可以发现urlopen有以下两种用法:
# 都返回响应对象
http.client.HTTPResponse = urllib.request.urlopen(url,data,timeout,cafile,capath,context)
http.client.HTTPResponse = urllib.request.urlopen(urllib.request.Request)
2.4 添加请求头
添加请求头,常常又叫UA伪装,作用是让爬虫模拟浏览器更真更假。基本格式:headers = {‘User-Agent’:‘请求头’} 。
还是以百度网址为例,右键选择检查,点击网络中百度网址,看标头,可以看到如下信息,还可继续往下滑查看更多。

- 请求网址:当前打开的网址。
- 请求方法:GET 请求,还有常见的POST请求。
- 状态代码:200 OK,表示请求网址打开成功。
- Cookie:用于用户身份识别。
- User-Agent:用户代理。
以知乎热榜为例,输入以下命令,获取网页HTML文件。
import urllib.request
try:
url = 'https://www.zhihu.com/billboard' # 知乎热榜
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
requests = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(requests) # 发起请求,返回响应对象
msg = response.read().decode('utf-8') # 调用read方法读取数据并解码
save_file = open('zhihubillboard.html','w') # 将网页信息保存为html文件,可以指定绝对路径,此处文件存放在命令行所处目录下
save_file.write(msg)
save_file.close()
print('over!')
except Exception as e:
print(str(e))
也可以继续在请求头中添加其它信息,如Cookie,便于身份识别。
import urllib.request
try:
url = 'https://www.zhihu.com/billboard' # 知乎热榜
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Cookie': '_zap=a4ca5ae3-6096-4bfe-85d9-29ec029e5139; d_c0=AGDWXB3XchaPTh7JqVPL2DXt_HZ-eyoUOe8=|1678443923; __snaker__id=Rojpy7kzOo4QD1qH; YD00517437729195%3AWM_NI=jFh9c3lgUsZ2rn%2F4NoCwfBUKeMIG7qwJ7ogEPJYJx3HH2VSM74V4z8d%2FKTapadHED%2Fy2ZfMSiY6Tup5jQR7wYP6jBo%2Fqj4FqgLO9Rty4prHJCwZD%2BLUYEIzOsT3dQaIBZHc%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6eea3e14285868c93d57ab2968fa3c15f928a8a87c16ab08e84adc67cf6eebaa3f92af0fea7c3b92aaa9aa8dae239b0b99b94d93ab2b2e1d5cd6581a9aaa3d841a79387a8b67bb596f990e64f949697abfb398c98feb7d247f5ec9ad5f934a8f185b5e47ca3bc88a6c725bbee9687d059ab87fab5f87cf7b69fb3b67d9b90fa8bc165edafa6d5c57ba59481dad180bbecc093cb4281a996a5aa4897878baaf945b18cfd85d46b8b9e96a9e237e2a3; YD00517437729195%3AWM_TID=RTtO5%2Fq3SYtEEAFVRBPAagEeaCt%2F26Ry; l_n_c=1; l_cap_id="OTNjZTgzNmQ4OTE5NDM2Y2FmMTJlOGY3NTlkYmE2MDI=|1703057324|7361fe71da9c72be879115517ae60a45a5cb9cc5"; r_cap_id="ZTVjMTgxZWQ2MTg3NGVlOGJjZDM3ODJjNmE0MDk2N2Y=|1703057324|a5fbcb7c58a06bccc58929001d0757465533852b"; cap_id="NzBhYTA3Mjc3ZTQ2NGZjYWI0OTI2MTY1MGU4OTQ4ZjI=|1703057324|70b91e0fc74f4df3a43ee78735905e9c4ea40e75"; n_c=1; _xsrf=lBmR1gcdJUT3in6ptJZhosQfxpcQATmo; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1703057329; captcha_session_v2=2|1:0|10:1703057329|18:captcha_session_v2|88:Sm9FR1ZqV1VZU0hpeHdoSXIvaWQyZ2FrKy84cTM4WVZ2QUtmVWxRZThPengrbFU0RkRhN2VDQWtWT1hURU0vQw==|9d94397475e180bfd9427e40143374afeb674533f873fc21c73d3c4cafc433b8; SESSIONID=o9FiVMzL4fXXqtarTVS3JsVpUea9CjwExnOnqJELoaq; JOID=VlwVAEshpRQX2k_EGibxBn9bpUAITphRfYgCulURw0hMqD-lbOs1lnXeS8Ma_QOeSua8OlDbmfBWrHqYFGnEZvI=; osd=VlgVCkwhoRQd3U_AGiz2Bntbr0cISphbeogGul8Ww0xMojilaOs_kXXaS8kd_QeeQOG8PlDRnvBSrHCfFG3EbPU=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1703057423; gdxidpyhxdE=jcNXJIKi%5Csz7c2u2UPPNoESbzjfffl0nXY0b7rcOozmIRo20NkiY%5C%5C%2BJzbUf7rZPNZpJqaCmojnY9cwqPlBVuBw0mnPEWhzZNuvxkWzPAQWG6U7SJ26sdhgRU4RWgaDo%5Ce0oI%5Cc7gBn%5Ckm%2B5nBOG7lDlvdSiVEExPGdrBNfa5%2BTUt%2BxA%3A1703059071056; KLBRSID=fe78dd346df712f9c4f126150949b853|1703058399|1703057324'
}
requests = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(requests) # 发起请求,返回响应对象
msg = response.read().decode('utf-8') # 调用read方法读取数据并解码
save_file = open('zhihubillboard1.html', 'w') # 将网页信息保存为html文件,可以指定绝对路径,此处文件存放在命令行所处目录下
save_file.write(msg)
save_file.close()
print('响应码:',response.getcode()) # 获取响应码
print('实际url:',response.geturl()) # 获取实际url
print(response.info()) # 获取服务器响应的HTTP标头
print('over!')
except Exception as e:
print(str(e))
2.5 认证登录
有SSL认证的网址,爬虫常常会报如下错:
URLError:
我们常常有两种方法,一种是可以对ssl进行设置,忽略掉警告,继续进行访问,如下对中国铁路12306网址,不登入进行访问。
import urllib.request
import ssl
# 对ssl进行设置,忽略警告,继续进行访问
ssl._create_default_https_context = ssl._create_unverified_context
url = 'https://www.12306.cn/mormhweb/'
response = urllib.request.urlopen(url=url)
msg = response.read().decode('utf-8')
print(msg)
另一种是使用账号进行登入访问,常见步骤如下:
- 创建一个账号密码管理对象。
- 添加账号和密码。
- 获取一个handler对象。
- 获取opener对象。
- 使用open()函数发起请求。
以博客园网址为例,注册一个账号,并且使用账号进行爬取。
import urllib.request
try:
url = 'https://www.cnblogs.com/' # 博客圆网址
user = 'user'
password = 'password'
pwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 创建一个账号密码管理对象
pwdmgr.add_password(None,url,user,password) # 添加账号和密码
auto_handler = urllib.request.HTTPBasicAuthHandler(pwdmgr) # 获取一个handler对象
opener = urllib.request.build_opener(auto_handler) # 获取opener对象
response = opener.open(url) # 使用open函数发起请求
msg = response.read().decode('utf-8')
save_file = open('blogs.html','w')
save_file.write(msg)
save_file.close()
print('over!')
except Exception as e:
print(str(e))

3.下载图片和视频
前面讲解了urllib基础知识,并结合不同网址爬取了相关源代码保存到本地。源代码相对陌生,接下来进一步使用urllib爬取我们常见的图片和视频格式文件。
以梨视频:https://www.pearvideo.com/ 为例,随便点击一个视频,进入到里面,右键选择检查,再点击左上方箭头,点击需要元素快速定位到源代码,即可获取到链接。

import urllib.request
import os
url = 'https://image2.pearvideo.com/cont/20231208/cont-1790138-12750419.jpg' # 图片url
requests = urllib.request.Request(url) # 发送请求,返回请求对象
response = urllib.request.urlopen(requests) # 返回响应对象
msg = response.read() # 读取信息
if not os.path.exists('download_file'): # 判断当前目录下,此目录是否存在,不存在则创建
os.makedirs('download_file')
save_file = open('download_file/2.jpg', 'wb') # 保存图片,模型为wb二进制写入
save_file.write(msg) # 写入图片
save_file.close() # 关闭
print('over!')
在这里我们利用os新建一个目录用于存放所下载的文件,如download_file,执行上面代码即可下载对应图片。
同样地,我们快速定位到一个视频源码链接。
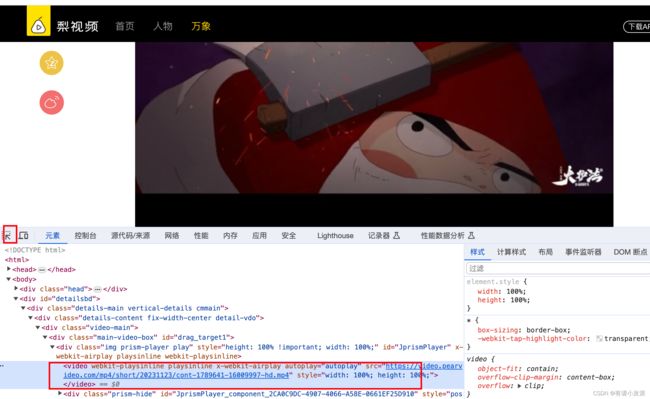
import urllib.request
import os
url = 'https://video.pearvideo.com/mp4/short/20231123/cont-1789641-16009997-hd.mp4' # 视频url
requests = urllib.request.Request(url) # 发送请求,返回请求对象
response = urllib.request.urlopen(requests) # 返回响应对象
msg = response.read() # 读取信息
if not os.path.exists('download_file'): # 判断当前目录下,此目录是否存在,不存在则创建
os.makedirs('download_file')
save_file = open('download_file/1.mp4', 'wb') # 保存视频,模型为wb二进制写入
save_file.write(msg) # 写入视频
save_file.close() # 关闭
print('over!')
继续将文件保存在download_file目录中,所得到的结果如下图。

以上是使用urllib.request和open方法实现的文件爬取保存,其实在urllib中还有urlretrieve方法也一样可以实现,urllib.request.urlretrieve(url,文件路径名称),具体可以查看以下示例。
import urllib.request
if __name__ == '__main__':
url1 = 'https://www.pearvideo.com/video_1789641' # 梨视频视频网页网址
url2 = 'https://image2.pearvideo.com/cont/20231208/cont-1790138-12750419.jpg' # 图片url
url3 = 'https://video.pearvideo.com/mp4/short/20231123/cont-1789641-16009997-hd.mp4' # 视频url
urllib.request.urlretrieve(url1, 'download_file/url1.html') # 保存url1为html
urllib.request.urlretrieve(url2, 'download_file/url2.jpg') # 保存url1为图片
urllib.request.urlretrieve(url3, 'download_file/url3.mp4') # 保存url1为视频
4.拓展-万能视频下载
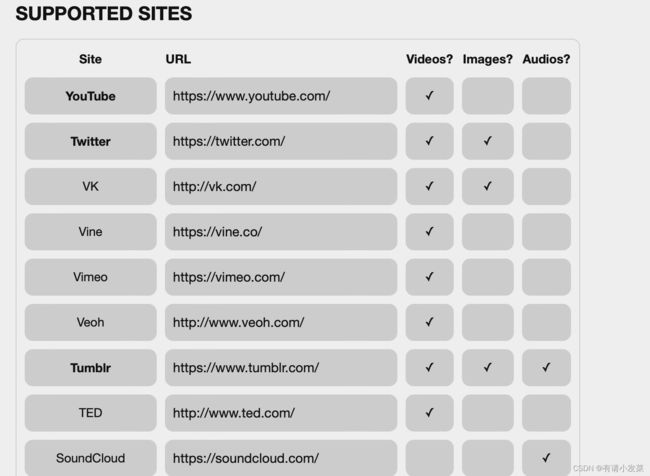
you-get官网:https://you-get.org
终端命令行中进行安装,如pip install you-get,安装完成后就可以直接使用了,从官网可以发现有支持下载的网址,以及相关知识和一些下载示例。
随便找一个支持的网易视频为例,使用右键检查,定位到视频对应的链接地址。
直接在命令行中输入以下命令即可下载,-o 选项可设置保存路径,-O 可设置下载文件的名称,不写默认截取链接后面的文本,还有其它一些可选参数可以前往官网深度学习。
you-get -o download_file -O wangyi 'https://flv3.bn.netease.com/d007d7e6e21113cbebd6ee56b312da000d3a18a34ed6f9e7a811c1aa017eda5705f4f1d6c53d0d0ff2258604ef5ce15c7673b36396bb3b4f500a1ee36ee64390bf1184a2f095c71e7704e67f17f928c03739fc8a26b9db66d943f36641e82fd9a992304050488f362fe95ad1d6b6fff4dc037de346c5be47.mp4'

每次在命令行书写you-get命令,可能存在记不住或者不方便,可以进一步使用python进行封装,模仿成在命令行执行,新建12.py文件输入以下命令。
import sys
from you_get import common
directory = 'download_file'
url = 'https://flv3.bn.netease.com/d007d7e6e21113cbebd6ee56b312da000d3a18a34ed6f9e7a811c1aa017eda5705f4f1d6c53d0d0ff2258604ef5ce15c7673b36396bb3b4f500a1ee36ee64390bf1184a2f095c71e7704e67f17f928c03739fc8a26b9db66d943f36641e82fd9a992304050488f362fe95ad1d6b6fff4dc037de346c5be47.mp4'
sys.argv = ['you-get','-o',directory,'-O','3','--format=flv',url] # 将you-get命令写入列表传递给变量
common.main()
命令行直接执行python 12.py,download_file目录即可保存新视频文件。

此封装方法很有用,在实际工作当有大量任务要在命令行执行命令时,也一样可以把任务列表罗列出来,然后遍历模拟成命令行命令。