计算机视觉:多视几何——基础矩阵原理
一、基础矩阵原理介绍
1、对极几何
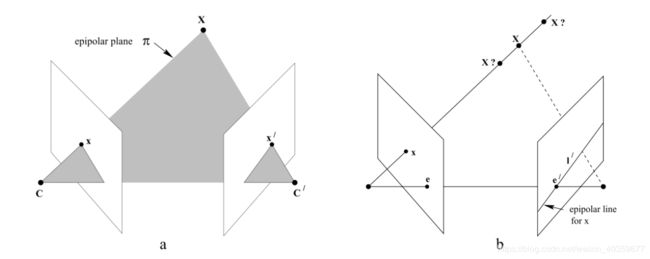
本质上两幅图之间的对极几何是图像平面与以基线为轴的平面束的交的几何,这种几何被广泛同于双目成像原理中
如图所示,摄像机由相机中心C,C’以及各自的成像平面表示,对于任意一个空间中的点X,在两个像平面上的点分别为x,x’,第一幅图像上的点x反向投影成空间三维的一条射线,它由摄像机中心和x确定,这条射线向第二个图像平面上投影得到一条直线l’,显然x的投影x’必然在l’上

如图所示,我们把相机中心的连线叫做基线(baseline),基线与两幅图像平面交于对极点e和e’,任何一条包含基线的平面pi是一张对极平面,分别与图像平面相交于l和l’,实际上,当三维位置X变化时,对应的实际上是该对极平面绕基线”旋转”,这个旋转得到的平面簇叫做对极平面束,由所有对极平面和成像平面相交得到的对极限相交于对极点
(1)对极几何的几个相关概念
对极平面束(epipolar pencil):以基线为轴的平面束;下图给出了包含两个平面的对极平面束
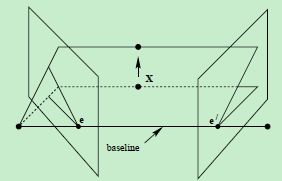
对极平面(epipolar plane):任何包含基线的平面都称为对极平面,或者说是对极平面束中的平面;例如,下图中的平面ππ就是一个对极平面

对极点(epipole):摄像机的基线与每幅图像的交点;即上图中的点e和e’
对极线(epipolar line):对极平面与图像的交线;例如,上图中的直线l和l’
2、基础矩阵
基础矩阵是对极几何的代数表达方式
本质矩阵描述了空间中的点在两个图像的投影的对应关系
(图像中任意对应点 x↔x’ 之间的约束关系)
F 为 3x3 矩阵,秩为2,对任意匹配点对 x↔x’ 均满足

基础矩阵F表示的就是这种从点到直线的映射。
(1)F的代数推导
设以第一个相机作为坐标系三维空间的点P=[X,Y,Z],其在两个相机的像点分别为p1,p2。由于第一个相机的中心作为世界坐标系的原点,也就是说第一个相机没有旋转和平移,通过小孔相机模型可得:
p1=KP,p2=K(RP+t)
其中,K是相机的内参,R,t是第二个相机相对于第一个相机的旋转和平移。
从p1=KP可以得到P=K−1p1,带入第二个式子可得到:
p2=K(RK−1p1+t)
两边同时左乘K−1,得到
K−1p2=RK−1p1+t
设x1=K−1p1,x2=K−1p2,代入
x2=Rx1+t
两边同时左乘向量t的反对称矩阵t×,由于t×t=0,消除t
t×x2=t×Rx1
两边再同时左乘xT2
xT2t×x2=xT2t×Rx1
由于t×x2是向量t和向量x2的叉积,同时垂直于向量t和向量x2,所以左边xT2t×x2=0,得到
xT2t×Rx1=0
再将x1,x2换掉
pT2K−Tt×RK−1p1=0
上式是对极约束的另一种表示,该式子中仅包含像点,相机的旋转和平移,中间的矩阵就是基础矩阵F。
pT2Fp1=0,其中F=K−Tt×RK−1
式子F=K−Tt×RK−1,可知假如相机的内参数K是已知的,提取中间的矩阵可到
E=t×R
E被称为本质矩阵,其和基础矩阵相差相机的内参K。
(2) 基础矩阵的性质:
1、转置对称性:如果 F 是一对影像 (P,P′) 的基础矩阵(即 x′Fx=0 ),反过来 (P′,P) 的基础矩阵是 FT。证明很简单,直接对 x′Fx=0 两侧分别转置,得到 xTFTx′=0 。
2、核线:对于左影像上任意一点 x ,其在右影像上的核线为 l′=Fx 。
3、核点:任何核线都会经过核点,所以有对于左影像上任意一点 x ,e′Tl′=e′T(Fx)=0 ,于是有 e′TF=0 。同理有 Fe=0 。
4、F 具有7自由度:一个 3x3 的单应矩阵,具有8个自由度,而 F 还满足/5、detF=0,所以 F 具有7个自由度。
5、F 是相关的:F 将左影像上的一点 x 投影到右影像上一条核线 l′,投影本质上是将 x 与左核点的连线 l 投影到右影像上的核线 l′ ,所以右影像上的一条核线 l′ 对应的是左影像上的一条核线 l,这种点到线的投影不可逆。
如果已知基础矩阵F,以及一个3D点在一个像面上的像素坐标p,则可以求得在另一个像面上的像素坐标p’。这个是基础矩阵的作用,可以表征两个相机的相对位置及相机内参数。
二、代码
# coding: utf-8
# In[1]:
from PIL import Image
from numpy import *
from pylab import *
import numpy as np
# In[2]:
from PCV.geometry import camera
from PCV.geometry import homography
from PCV.geometry import sfm
from PCV.localdescriptors import sift
from imp import reload
camera = reload(camera)
homography = reload(homography)
sfm = reload(sfm)
sift = reload(sift)
# In[3]:
# Read features
im1 = array(Image.open('D:/Python36/code/data/001.jpg'))
sift.process_image('D:/Python36/code/data/001.jpg', 'im1.sift')
im2 = array(Image.open('D:/Python36/code/data/002.jpg'))
sift.process_image('D:/Python36/code/data/002.jpg', 'im2.sift')
# In[4]:
l1, d1 = sift.read_features_from_file('im1.sift')
l2, d2 = sift.read_features_from_file('im2.sift')
# In[5]:
matches = sift.match_twosided(d1, d2)
# In[6]:
ndx = matches.nonzero()[0]
x1 = homography.make_homog(l1[ndx, :2].T)
ndx2 = [int(matches[i]) for i in ndx]
x2 = homography.make_homog(l2[ndx2, :2].T)
d1n = d1[ndx]
d2n = d2[ndx2]
x1n = x1.copy()
x2n = x2.copy()
# In[7]:
figure(figsize=(16,16))
sift.plot_matches(im1, im2, l1, l2, matches, True)
show()
# In[26]:
#def F_from_ransac(x1, x2, model, maxiter=5000, match_threshold=1e-6):
def F_from_ransac(x1, x2, model, maxiter=5000, match_threshold=1e-6):
""" Robust estimation of a fundamental matrix F from point
correspondences using RANSAC (ransac.py from
http://www.scipy.org/Cookbook/RANSAC).
input: x1, x2 (3*n arrays) points in hom. coordinates. """
from PCV.tools import ransac
data = np.vstack((x1, x2))
d = 10 # 20 is the original
# compute F and return with inlier index
F, ransac_data = ransac.ransac(data.T, model,
8, maxiter, match_threshold, d, return_all=True)
return F, ransac_data['inliers']
# In[27]:
# find F through RANSAC
model = sfm.RansacModel()
F, inliers = F_from_ransac(x1n, x2n, model, maxiter=5000, match_threshold=1e-5)
print(F)
# In[28]:
P1 = array([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0]])
P2 = sfm.compute_P_from_fundamental(F)
# In[29]:
print(P2)
print (F)
# In[30]:
# P2, F (1e-4, d=20)
# [[ -1.48067422e+00 1.14802177e+01 5.62878044e+02 4.74418238e+03]
# [ 1.24802182e+01 -9.67640761e+01 -4.74418113e+03 5.62856097e+02]
# [ 2.16588305e-02 3.69220292e-03 -1.04831621e+02 1.00000000e+00]]
# [[ -1.14890281e-07 4.55171451e-06 -2.63063628e-03]
# [ -1.26569570e-06 6.28095242e-07 2.03963649e-02]
# [ 1.25746499e-03 -2.19476910e-02 1.00000000e+00]]
# In[31]:
# triangulate inliers and remove points not in front of both cameras
X = sfm.triangulate(x1n[:, inliers], x2n[:, inliers], P1, P2)
# In[32]:
# plot the projection of X
cam1 = camera.Camera(P1)
cam2 = camera.Camera(P2)
x1p = cam1.project(X)
x2p = cam2.project(X)
# In[33]:
figure(figsize=(16, 16))
imj = sift.appendimages(im1, im2)
imj = vstack((imj, imj))
imshow(imj)
cols1 = im1.shape[1]
rows1 = im1.shape[0]
for i in range(len(x1p[0])):
if (0<= x1p[0][i]三、实验结果
1、室外场景
1)、运行结果
|| 第一张图和第二张图的sift特征点匹配图:
 ------------------------------------------图3-1-1------------------------------------------
------------------------------------------图3-1-1------------------------------------------
|| 经过ransac算法筛选得到的特征点匹配图

------------------------------------------图3-1-2------------------------------------------
|| 经过前面的得到的基础矩阵对第一张图和第三张图进行特征匹配

------------------------------------------图3-1-3------------------------------------------
2)、基础矩阵

------------------------------------------图3-1-4------------------------------------------
2、室内场景
1)、运行结果

------------------------------------------图3-2-1------------------------------------------
------------------------------------------图3-2-2------------------------------------------
------------------------------------------图3-2-3------------------------------------------
2)、基础矩阵

三、遇到问题

在实际图像中获取到的数据,常常会包含有噪声数据,这些噪声数据会使对模型的构建造成干扰,我们称这样的噪声数据点为outliers,那些对于模型构建起积极作用的我们称它们为inliers,RANSAC做的一件事就是先随机的选取一些点,用这些点去获得一个模型(这个讲得有点玄,如果是在做直线拟合的话,这个所谓的模型其实就是斜率),然后用此模型去测试剩余的点,如果测试的数据点在误差允许的范围内,则将该数据点判为inlier,否则判为outlier。inliers的数目如果达到了某个设定的阈值,则说明此次选取的这些数据点集达到了可以接受的程度,否则继续前面的随机选取点集后所有的步骤,不断重复此过程,直到找到选取的这些数据点集达到了可以接受的程度为止,此时得到的模型便可认为是对数据点的最优模型构建。
解决:修改阈值,使得inliers的数目多一些
![]()
注意:拍摄角度很重要,很有可能拍出来的照片找不到匹配点。