Python爬虫爬取中国大学慕课MOOC课程的课程评价信息(讨论信息),采用selenium动态爬取方法
首先慕课网是动态网页,不能简简单单采用以前的静态网站的方法,,,所以,,,
我在一开始的时候选择selenium+phantomjs(百度的),后因selenium版本高,不支持后者了,因此我把selenium换成了2.48.0版本,后来发现selenium+phantomjs这种方法运行特别慢,而且我觉得还是有问题,因此开始选择selenium+WebDriver,此方法需要下载chrome浏览器(必需32位),我下载了70.0的浏览器,,对于webDriver必需要下载一个对应支持浏览器版本的版本,如果没有,就选时间最近的,二者还需要在同一目录奥!,具体的话百度一下吧,,学编程的同学最好使用火狐和chrome浏览器奥,看源码方便,我也是小白,下面贴上原创代码奥,经本人运行无误上传分享,谢谢支持!(开头引入的234个库没有用到)
from selenium import webdriver
from time import sleep
import os
import re
from bs4 import BeautifulSoup #executable_path为chromedriver.exe的解压安装目录,需要与chrome浏览器同一文件夹下
driver=webdriver.Chrome(executable_path="C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe")
url='https://www.icourse163.org/course/BIT-268001' #爬取Python语言程序设计为例
driver.get(url)
cont=driver.page_source #获得初始页面代码,接下来进行简单的解析
soup=BeautifulSoup(cont,'html.parser')
#print(soup)
ele=driver.find_element_by_id("review-tag-button") #模仿浏览器就行点击查看课程评价的功能
ele.click() #上边的id,下边的classname都可以在源码中看到(首选火狐,谷歌)
xyy=driver.find_element_by_class_name("ux-pager_btn__next")#翻页功能,类名不能有空格,有空格可取后边的部分
connt=driver.page_source
soup=BeautifulSoup(connt,'html.parser')
#print(soup)
acontent=[] #n页的总评论
content=soup.find_all('div',{'class':'ux-mooc-comment-course-comment_comment-list_item_body_content'})#包含全部评论项目的总表标签
#print(content)
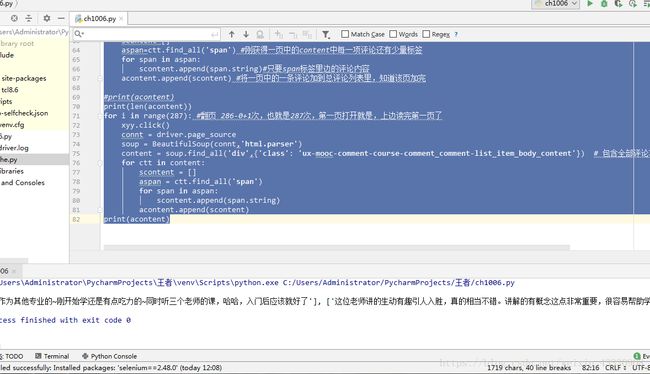
for ctt in content: #第一页评论的爬取
scontent=[]
aspan=ctt.find_all('span') #刚获得一页中的content中每一项评论还有少量标签
for span in aspan:
scontent.append(span.string)#只要span标签里边的评论内容
acontent.append(scontent) #将一页中的一条评论加到总评论列表里,知道该页加完
#print(acontent)
print(len(acontent))
for i in range(287): #翻页 286-0+1次,也就是287次,第一页打开就是,上边读完第一页了
xyy.click()
connt = driver.page_source
soup = BeautifulSoup(connt,'html.parser')
content = soup.find_all('div',{'class': 'ux-mooc-comment-course-comment_comment-list_item_body_content'}) # 包含全部评论项目的总表标签
for ctt in content:
scontent = []
aspan = ctt.find_all('span')
for span in aspan:
scontent.append(span.string)
acontent.append(scontent)
print(acontent)