Dgraph的基本使用经典教程(安装,数据导入,导出,删除,查询等)
一、安装
Windows系统下安装Dgraph
下载二进制文件dgraph-windows-amd64.tar.gz
https://github.com/dgraph-io/dgraph/releases/download/v1.0.14/dgraph-windows-amd64.tar.gz
解压,在dgraph工作目录下,依次执行:
dgraph zero
dgraph alpha --lru_mb 2048 --zero localhost:5080
dgraph-ratel
前端使用localhost:8000访问
数据查询使用localhost:8080访问
Linux系统下安装Dgraph
1、拉取dgraph镜像文件
docker pull dgraph/dgraph
2、 安装二进制文件
curl https://get.dgraph.io -sSf | bash
3、docker-compose.yaml文件撰写
version: "3.2"
services:
zero:
image: dgraph/dgraph:latest
volumes:
- type: volume
source: dgraph
target: /dgraph
volume:
nocopy: true
ports:
- 5080:5080
- 6080:6080
restart: on-failure
command: dgraph zero --my=zero:5080
server:
image: dgraph/dgraph:latest
volumes:
- type: volume
source: dgraph
target: /dgraph
volume:
nocopy: true
ports:
- 8080:8080
- 9080:9080
restart: on-failure
command: dgraph alpha --my=server:7080 --lru_mb=2048 --zero=zero:5080
ratel:
image: dgraph/dgraph:latest
volumes:
- type: volume
source: dgraph
target: /dgraph
volume:
nocopy: true
ports:
- 8000:8000
command: dgraph-ratel
volumes:
dgraph:
4、建立Dgraph容器集群
docker-compose up -d
5、使用docker ps -a |grep dgraph查看是否安装成功,如果存在三个带有dgraph的容器,并且状态为up,说明安装成功。
二、数据的导入
数据导入之前的数据处理
1、在执行导入之前,需将数据处理成dgraph支持的格式。如下所示:
<:uid> <属性> “属性值” .
<:uid> <关系> <:uid> .
如下例子:
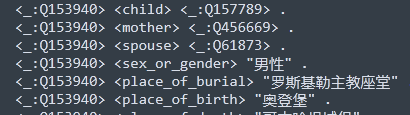
PS1:属性/关系值里面不能出现双引号,因为最外面使用的是双引号,所以你需要将数据值中的双引号全替换为单引号。
PS2:文件的后缀保存为.rdf格式或者,将rdf文件压缩为.gz格式。
PS3:每一个uid一定要有name属性,即<:uid> “name的值” .
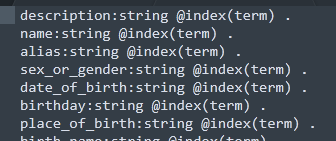
2、设置schema文件,该文件是配置数据类型和索引的,string表示字符串,datetime表示时间类型,具体类型请看官网https://docs.dgraph.io/get-started/。term表示模糊查询索引,还有trigram正则索引等等,详细索引请查阅官网。该文件最后保存为.schema格式
Linux系统下导入
1、仅开启zero服务(5080端口)docker容器,并进入5080服务docker,如果数据库有数据,请先删除p和w文件夹
2、执行
dgraph bulk -r goldendata.rdf -s goldendata.schema --map_shards=4 --reduce_shards=1 --zero=localhost:5080
3、这时候会生成一个out文件夹,进入里面找到p和w文件夹,复制至dgraph主目录对原先的p、w进行覆盖
4、重新启动三个docker服务,导入完成
参数说明 :
– goldendata.rdf.gz 表示rdf三元组文件,也可以不压缩为gz,直接使用rdf文件;
– goldendata.schema 表示定义的导入数据类型;
– reduce_shards 表示服务器集群数据同步之类的,一般自己用1即可;
–localhost:5080 表示ip地址和端口
PS:如果还不清楚,可参考本人另外一篇博客:https://blog.csdn.net/weixin_43922901/article/details/91362434
Windows系统下导入
windows系统下导入和linux相同,只不过服务不是docker形式
三、数据的导出
windows系统下
1、在三个服务全开启的情况下,访问:http://localhost:8080/admin/export, 过一会后,会出现 ’ {“code”: “Success”, “message”: “Export completed.”} ’ 提示,说明导入成功
2、在dgraph的主目录下,会出现一个export文件夹,进入里面,会发现多了两个压缩包,一个是存储的数据,一个是schema文件。导出成功。
Linux系统下
关闭除zero服务的另外服务,进入到zero服务的docker,在/dgraph目录下,
rdf格式导出
curl localhost:8080/admin/export
json格式导出
curl 'localhost:8080/admin/export?format=json'
三、 Dgraph数据查询(此部分主要参考官网)
1、通过uid查询数据, – uid – get这个字段是自定义的。
{
get(func: uid(0x579683)) {
uid
name@en
initial_release_date
netflix_id
}
}
2、指定多个uid查询
{
movies(func: uid(0x579683, 0x5af1c7)) {
uid
name@en
initial_release_date
netflix_id
}
}
3、通过属性名完全匹配查询数据, – eq函数 – 命令行查询一头一尾加上如下代码即可
curl localhost:8080/query -XPOST -d '{
get(func: eq(name@en, "Blade Runner")) {
uid
name@en
initial_release_date
netflix_id
}
}' | python -m json.tool | less
4、模糊查询
查询可以匹配许多节点并返回每个节点的值。即根Blade或Runner有关的所有节点 – anyofterms函数
查询示例:名称中包含“Blade”或“Runner”的所有节点。
{
get(func: anyofterms(name@en, "Blade Runner")) {
uid
name@en
initial_release_date
netflix_id
}
}
查询示例:描述中包含美国总统的四个字的词,注意,不一定连续
{
directors(func: allofterms(description, "美国总统")) {
name
description
}
}
anyofterms
语法示例: anyofterms(predicate, “space-separated term list”)
架构类型: string
所需索引: term
匹配任何顺序中具有任何指定术语的字符串; 不区分大小写。
5、查询示例:“Blade Runner”中演员和角色。查询首先找到名为“Blade Runner”的节点,然后将传出starring边缘跟随表示actor作为角色的表现的节点。从那里扩展performance.actor和performance,character扩展边缘以找到电影中每个演员的演员姓名和角色。
{
brCharacters(func: eq(name@en, "Blade Runner")) {
name@en
initial_release_date
starring {
performance.actor {
name@en # actor name
}
performance.character {
name@en # character name
}
}
}
}
6、查询示例:标题中带有“Blade”或“Runner”并在2000年之前发布的电影。 – le函数,小于?
{
bladerunner(func: anyofterms(name@en, "Blade Runner")) @filter(le(initial_release_date, "2000")) {
uid
name@en
initial_release_date
netflix_id
}
}
7、通过正则表达式匹配,这个需要在导入数据时添加正则索引trigram
语法示例:regexp(predicate, /regular-expression/)或不区分大小写regexp(predicate, /regular-expression/i)
架构类型: string
所需索引: trigram
查询示例:在root中,匹配节点Steven Sp的开头name,后跟任何字符。对于每个这样匹配的uid,匹配包含的电影ryan。注意区别allofterms,只有匹配ryan但正则表达式搜索也会匹配术语,例如bryan。
{
directors(func: regexp(name@en, /^Steven Sp.*$/)) {
name@en
director.film @filter(regexp(name@en, /ryan/i)) {
name@en
}
}
}
8、全文检索 – alloftext
查询示例:有所有的名字run,running等等和man。停止删除单词消除the和maybe
全文检索
语法示例:alloftext(predicate, “space-separated text”)和anyoftext(predicate, “space-separated text”)
架构类型: string
所需索引: fulltext
{
movie(func:alloftext(name@en, "the man maybe runs")) {
name@en
}
}
9、等于、不等于
eq(edge_name, value): 等于
ge(edge_name, value): ga大于等于
le(edge_name, value): 小于等于
gt(edge_name, value): 大于
lt(edge_name, value): 小于
10、 AND、OR、NOT
AND, OR 以及 NOT可以把一个filter中的多个function结合起来
{
michael_friends_and(func: allofterms(name, "Michael")) {
name
age
friend @filter(ge(age, 27) AND le(age, 48)) {
name@.
age
}
}
}