基于Deep Learning的跟踪算法总结(三)
本文是博主对最近看的相关跟踪算法的总结,其中的算法有一些不是基于深度学习的。另外本文只是对各篇论文的核心亮点简单描述,同时加上博主自己的一些看法。本文仅作为学习笔记,供学习交流,如果有什么错误或疑问,欢迎留言。
知乎:王弗兰克
https://www.zhihu.com/people/xue-sheng-er-yi/activities
这里提供两个链接,供大家学习参考。
目标跟踪专栏(目前在更新):https://zhuanlan.zhihu.com/visual-tracking
”小白在闭关“个人博客:http://wh1te.me/index.php/tag/tracking/
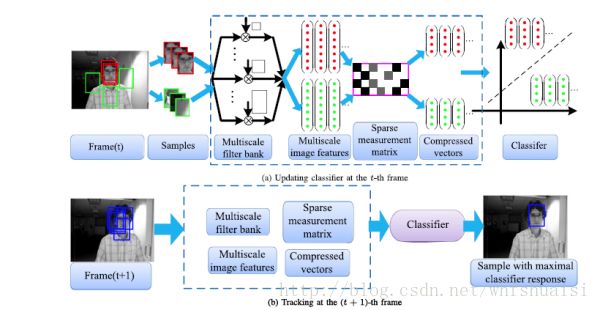
一、压缩跟踪(compressive tracking)
简称CT,发表于ECCV2012,升级版发表于PAMI2014,简称FCT。
本文的核心在于使用压缩感知的方法来进行特征表示,实现了降维,同时得到的低维信号可以保持高维信号的特性。
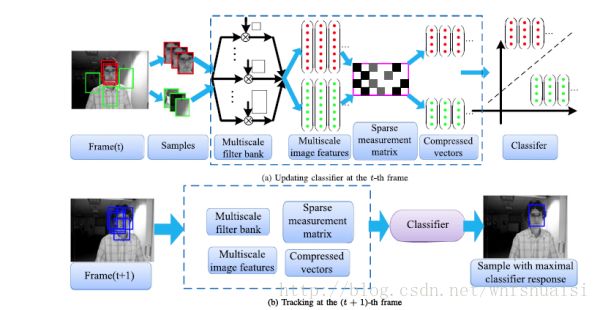
压缩感知请参考:
http://blog.csdn.net/zhang11wu4/article/details/19699763
二、ECO( Efficient Convolution Operators for Tracking)
论文链接:
http://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1611.09224.pdf
本文主要解决三个问题:
1、模型大小(使用了CNN提取特征的跟踪算法,参数过多,导致速度慢;又由于训练数据少,容易过拟合);
2、训练集大小(这里所指的训练集是指保存了每一帧的跟踪结果的训练集,所以随着跟踪的进行,训练集越来越大,一般的解决方案是保存比较新的样本,丢弃老的样本,这样一来,模型还是容易过拟合。因为当目标被遮挡或者丢失的时候,比较新的这些样本本身就是错的,那么模型很容易有model drift,就是被背景或者错误的目标污染,导致跟踪结果出错。);
3、模型更新(显然,模型如果每帧都更新,速度肯定比间歇更新要慢)。
本文的核心是Factorized Convolution Operator(因式分解的卷积操作)。其作用主要是为了降维。另外,通过改变训练样本的分来,减少了数据的冗余。更新规则是目前比较通用的,每隔几帧更新一次,这样可以避免模型漂移。
因式分解卷积以及算法的流程请参见:
http://blog.csdn.net/discoverer100/article/details/62885860
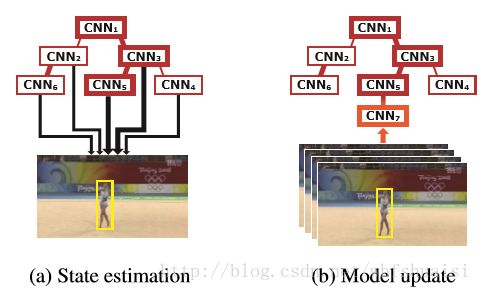
三、TCNN(Modeling and Propagating CNNs in a Tree Structure for Visual Tracking)
论文链接:
http://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1608.07242.pdf
这篇其实刚刚是上一篇文章的精炼,这里稍微提一下。
http://blog.csdn.net/whfshuaisi/article/details/70228930
本文的核心在于使用了树状CNN结构,可以理解为跟踪的每个阶段都训练出新的CNN,即每个CNN学习到的特征是目标在不同阶段的特征,最后结果由多个CNN加权求和得到。因为之前的信息也能被CNN捕获,并且对最终结果有一定权重,所以可以减少模型飘移。
四、Staple:Complementary Learners for Real-Time Tracking
论文链接:
http://link.zhihu.com/?target=http%3A//arxiv.org/pdf/1512.01355
代码链接:
https://github.com/bertinetto/staple
本文的核心在于考虑了两种特征的结合,即Learning the template score(Hog特征)+ Learning the histogram score(简单的颜色直方图)。
相关滤波用HOG特征时对运动模糊和照度很鲁棒,但是对形变不够鲁棒。而颜色直方图对形变则非常鲁棒。毕竟一个目标有了形变后,整个目标的颜色分布是基本不会变的。另一方面,颜色直方图对光照变化不鲁棒,这一点又可以由HOG特征进行互补。
五、MDNet: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
论文链接:
http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Nam_Learning_Multi-Domain_Convolutional_CVPR_2016_paper.pdf
代码链接:
https://github.com/HyeonseobNam/MDNet
本文发表于2015年。2015年底的时候,Visual Tracking领域继Object Detection之后,陆续将CNN引入,但是大部分算法只是用在大量数据上训练好的(pretrain)的一些网络如VGG作为特征提取器,结果证明确实用了CNN深度特征对跟踪结果是有较大的改进的。那么其实自己设计一个网络来做跟踪是大家都能够想到的思路,Korea的POSTECH这个团队就做了MDNet。
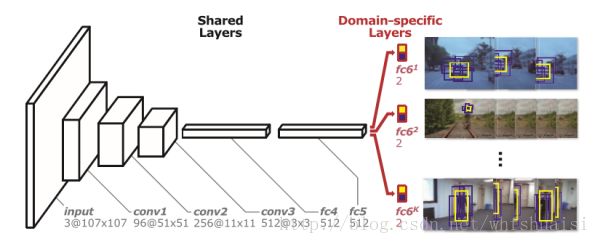
本文的核心在于提出了Multi-Domain Network,多域学习的网络结构。
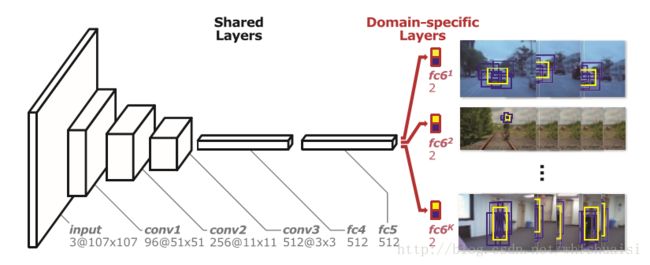
直接用视频数据来进行训练,从视频中随机采取8帧作为一个mini-batch,然后在这8帧里随机采取正负样本。鉴于不同的视频里,目标不同,所以,MDNet重新设计了网络结构,即fc6层是针对不同视频的。这样的训练来学得各个视频中目标的共性。训练好的网络在做test的时候,会新建一个fc6层,在线fine-tune fc4-fc6层,卷积层保持不变。
模型更新方面,采用采用long-term和short-term两种更新方式。
六、GOTURN(Generic Object Tracking Using Regression Networks)
第一个做到100FPS的深度学习跟踪算法——GOTURN。
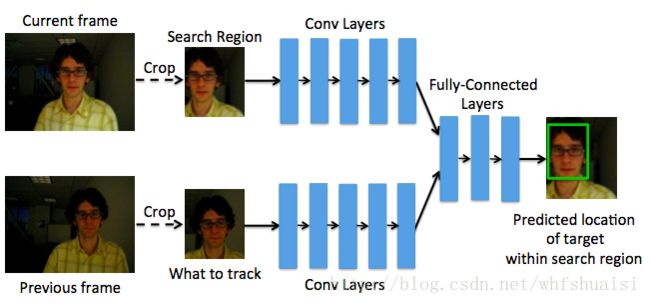
本文的核心在于不对patch进行classification,而是对object的bounding-box进行回归,以获得更高的FPS。
输入是当前帧和上一帧。
两种假设:
网络比较前后两帧,并找到目标在当前帧的位置,有点verification的意思;网络就想一个通用的object detector,找到最近的目标。
当当前帧出现较为严重的遮挡/相机运动,此时tracker可以从前一帧中获得非常大的性能提升,因为tracker记住了哪个objcet是要跟踪的,这种情况中,第一个假设扮演了重要的角色。而当帧间变化剧烈时,相邻帧的比较更为困难,此时假设二占主导,tracker表现的像一个通用object detector
最后,自己这段时间也把目标跟踪方向的经典论文看了一遍,这里对这个方向做个简单的梳理。
总结:
①目前目标跟踪主要分为两大类:基于相关滤波和基于深度学习。需要注意的是,因为训练数据缺失的问题,这一领域暂时未被深度学习完全统治。
②顶会上目标跟踪论文主要有两类:拼精度和拼速度。精度和速度一直是跟踪领域的矛与盾。相比而言,基于深度学习方法的模型精度更好,但基于相关滤波(可以用FFT加速)的模型速度快很多。
③目标跟踪≠目标检测。
参考:https://www.zhihu.com/question/36500536
④遮挡和剧烈形变,是目标跟踪需要解决的关键问题。解决方法主要是使用long-term和short-term两种更新方式。上面提到的TCNN其实也是这种思想。
⑤目标跟踪论文的不同之处主要在于:训练数据的处理,模型的结构,更新的规则。
⑥总的来说,读论文时,目标跟踪相比与目标检测,路线不是那么明确。因为目标检测有RCNN系列,以及一连串改进,最后是基于回归方法的YOLO和SSD嘛。但目标跟踪就比较杂,不好梳理发展的路线。
展望:
最近GAN应用在了目标检测上,可以生成辅助样本。博主目前在想如何把GAN应用在目标跟踪上(也许已经有相关论文,欢迎指出)。同时,关注到3D Vision有崛起的势头(之前有3D CNN),因为3D模型在跟踪场景其实更直观明了,所以考虑是不是不要把视频样本当成是一帧帧2D图像来处理,我对这个方向目前没什么头绪,不知道今年CVPR放出来有没有相关论文,欢迎有研究的同学留言交流。