分布式机器学习系统笔记(一)——模型并行,数据并行,参数平均,ASGD
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。
技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入。
文章索引::”机器学习方法“,”深度学习方法”,“三十分钟理解”原创系列
2017年3 月,谷歌大脑负责人 Jeff Dean 在 UCSB 做了一场题为《通过大规模深度学习构建智能系统》的演讲[9]。Jeff Dean 在演讲中提到,当前的做法是:
解决方案 = 机器学习(算法)+ 数据 + 计算力
未来有没有可能变为:
解决方案 = 数据 + 100 倍的计算力?
由此可见,谷歌似乎认为,机器学习算法能被超强的计算力取代[9]。

[11]研究工作表明,任务表现与训练数据数量级呈线性增长关系。或许最令人震惊的发现是视觉任务的表现和用于表征学习的训练数据量级(对数尺度)之间的关系竟然是线性的!即使拥有 300M 的大规模训练图像,我们也并未观察到训练数据对所研究任务产生任何平顶效应(plateauing effect)。

上图说明预训练模型在 JFT-300M 不同子数据集中的目标检测性能。其中 x 轴代表数据集的大小,y 轴代表在 mAP@[.5,.95] 中 COCO-minival 子数据集上的检测性能。
要完成超大规模数据的训练,以及训练超大规模的神经网络,靠单GPU是行不通的(至少目前来看),必须要有分布式机器学习系统的支撑,本文以及接下来几篇博客,会记录一下前面几年比较经典的分布式机器学习系统的学习笔记,文中资料都参考了public的paper或者网上资料,我会自己整理一下,并标明出处。作为第一篇,先总体地介绍一个全貌的基本概念。
并行模型
- 模型并行( model parallelism ):分布式系统中的不同机器(GPU/CPU等)负责网络模型的不同部分 —— 例如,神经网络模型的不同网络层被分配到不同的机器,或者同一层内部的不同参数被分配到不同机器;[14]
- 数据并行( data parallelism ):不同的机器有同一个模型的多个副本,每个机器分配到不同的数据,然后将所有机器的计算结果按照某种方式合并。

- 当然,还有一类是混合并行(Hybrid parallelism),在一个集群中,既有模型并行,又有数据并行,例如,可以在同一台机器上采用模型并行化(在GPU之间切分模型),在机器之间采用数据并行化。
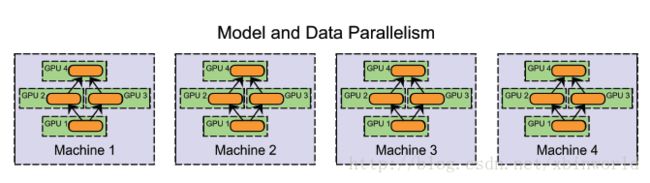
数据并行
数据并行化式的分布式训练在每个工作节点上都存储一个模型的备份,在各台机器上处理数据集的不同部分。数据并行化式训练方法需要组合各个工作节点的结果,并且在节点之间同步模型参数。文献中讨论了各种方法,各种方法之间的主要区别在于:
- 参数平均法 vs. 更新式方法
- 同步方法 vs. 异步方法
- 中心化同步 vs. 分布式同步
参数平均 model averaging
参数平均是最简单的一种数据并行化。若采用参数平均法,训练的过程如下所示:
- 基于模型的配置随机初始化网络模型参数
- 将当前这组参数分发到各个工作节点
- 在每个工作节点,用数据集的一部分数据进行训练
- 将各个工作节点的参数的均值作为全局参数值
- 若还有训练数据没有参与训练,则继续从第二步开始
上述第二步到第四步的过程如下图所示。在图中,W表示神经网络模型的参数(权重值和偏置值)。下标表示参数的更新版本,需要在各个工作节点加以区分。
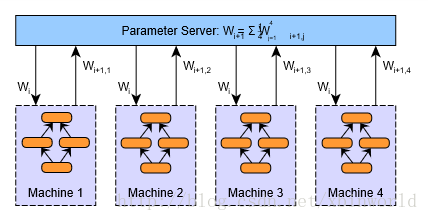
很容易证明参数平均法的结果在数学意义上等同于用单个机器进行训练;每个工作节点处理的数据量是相等的。(实际上如果采用momentum等技术,并不是严格相等的)
假设该集群有n个工作节点,每个节点处理m个样本,则总共是对nxm个样本求均值。如果我们在单台机器上处理所有nxm个样本,学习率设置为α,权重更新的方程为:

现在,假设我们把样本分配到n个工作节点,每个节点在m个样本上进行学习(节点1处理样本1,……,m,节点2处理样本m+1,……,2m,以此类推),则得到:
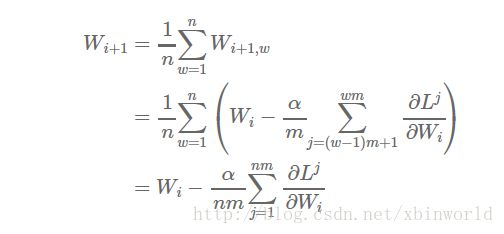
参数平均法听上去非常简单,但事实上并没有我们看上去这么容易。
首先,我们应该如何求平均值?最简单的办法就是简单地将每轮迭代之后的参数进行平均。一旦这样实现了,我们会发现此方法在计算之外的额外开销非常巨大;网络通信和同步的开销也许就能抵消额外机器带来的效率收益。因此,参数平均法通常有一个大于1的平均周期averaging period(就每个节点的minibatch而言)。如果求均值周期太长,那么每个节点得到的局部参数更多样化,求均值之后的模型效果非常差。我们的想法是N个局部最小值的均值并不保证就是局部最小:
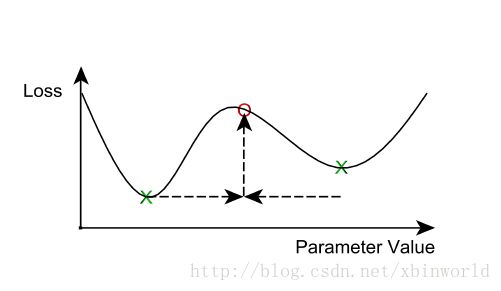
什么样的平均的周期算是过高呢?这个问题还没有结论性的回答,和其它超参数搅和在一起之后变得更为复杂,比如学习率、minibatch的大小,和工作节点的数量。有些初步的研究结论(比如[16])建议平均的周期为每10~20个minibatch计算一次(每个工作节点)能够取得比较好的效果。随着平均的周期延长,模型的准确率则随之下降。
另一类额外的复杂度则是与优化算法相关,比如adagrad,momentum和RMSProp。这些优化方法,在神经网络的训练过程中能够显著提升收敛的特性。然而,这些updater都有中间状态(通常每个模型参数有1或2个状态值)—— 我们也需要对这些状态值求均值吗?对每个节点的中间状态求均值可以加快收敛的速度,而牺牲的代价则是两倍(或者多倍)增加网络的传输数据量。有些研究在参数服务器的层面应用类似的“updater”机制,而不仅仅在每个工作节点([17])。
异步随机梯度下降 Asynchronous SGD
有另一种与参数平均概念类似的方法,我们称之为‘基于更新’的数据并行化。两者的主要区别在于相对于在工作节点与参数服务器之间传递参数,我们在这里只传递更新信息(即梯度和冲量等等)。参数的更新形式变为了:
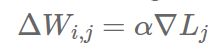
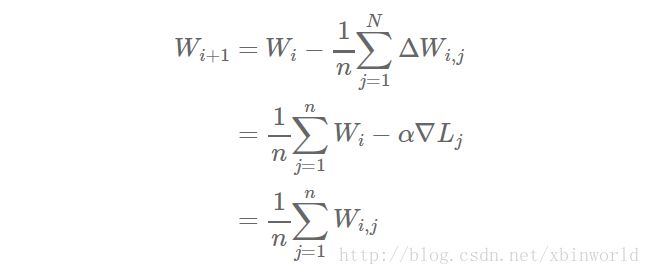
当参数时同步方式更新时,参数平均法等价于基于更新的数据并行化。这个等价关系对多个平均步骤以及其它updater都成立(不仅限于标准SGD)。
当我们松绑同步更新的条件之后,基于更新的数据并行化方法变得更有意思了。也就是说,一旦计算得到?Wi,j,就立即将其应用于参数向量(而不是等待N ≥ 1 轮迭代),我们因此得到了异步随机梯度下降算法。异步SGD有两个主要优势:
首先,我们能够增加分布式系统的数据吞吐量:工作节点能把更多的时间用于数据计算,而不是等待参数平均步骤的完成
其次,相比于同步更新的方式(每隔N步),各个节点能够更快地从其它节点获取信息(参数的更新量)。
但是,这些优势也不是没带来开销。随着引入参数向量的异步更新,我们带来了一个新的问题,即梯度值过时问题。梯度值过时问题也很简单:计算梯度(更新量)需要消耗时间。当某个节点算完了梯度值并且将其与全局参数向量合并时,全局参数可能已经被刷新了多次。用图片来解释这个问题就是如下:
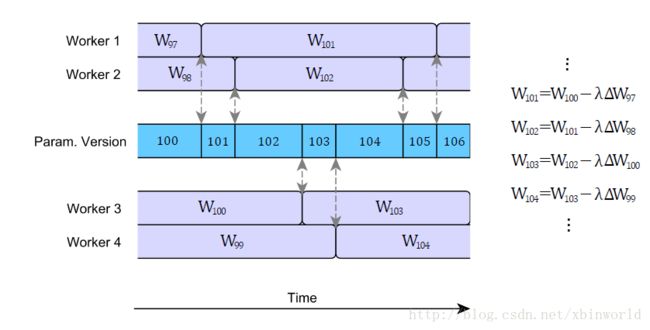
异步SGD的简单实现可能会导致非常严重的梯度值过时。举个例子,Gupta et al. 2015 [18]证明了梯度值的平均过时量等于执行单元的个数。假设有N个执行单元,也就是说梯度值被用于计算全局参数向量时,平均会延迟N个计算步骤。这会在现实场景中带来问题:严重的梯度值过时会明显减慢网络模型的收敛速度,甚至完全停止了收敛。早期的异步SGD实现(例如Google的DistBelief系统)并没有考虑到这些问题,因此学习的效率远不如它原本应有状态。
异步随机梯度下降方法还有多种形式的变种,但采取了各种策略来减弱梯度过时所造成的影响,同时保持集群的高可用率。解决梯度值过时的方法包括以下几种:
- 基于梯度值的过时量,对每次更新?Wi,j 分别缩放λ的值
- 采用‘软’的同步策略soft synchronization([19])
- 使用同步策略来限制过时量。例如,[20]提到的系统在必要时会延迟速度较快的节点,以保证最大的过时量控制在某个阈值以下。事实上一般现在采用bounded delay策略更多,见[1],给定一个t参数,要求t轮之前旧的参数更新必须全完成才能开始当前轮次的参数更新。
所有这些方法相比简单的异步SGD算法都本证明能提升收敛的性能。尤其是前两条方法效果更为显著。soft synchronization的方法很简单:相对于立即更新全局参数向量,参数服务器等待收集n个节点产生的s次更新?Wj(1 ≤ s ≤ n)。参数随之进行更新:
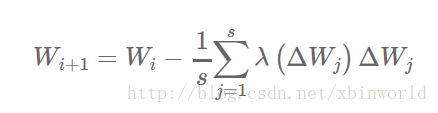
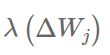 表示缩放因子。
表示缩放因子。
注意,我们设置s=1并且λ(·) = 常数,就得到了简单版的异步SGD算法([2]);同样的,若设置s = n,我们得到了类似(不完全相同)同步参数平均的算法。
后面会介绍Google DistBelief 框架,并行随机梯度下降算法Downpour SGD
DistBelief
先来描述Google在2012年发表在NIPS上的一个工作[2],虽然不是分布式机器学习系统的第一篇,但我相信是在近几年来影响最为深远的一篇,之后包括微软等公司纷纷研究自己的分布式系统Adam[12],Parameter Server[1][3][4],petuun[13],或多或少都受其影响。
(未完待续…)
http://blog.sina.com.cn/s/blog_81f72ca70101kuk9.html
参考资料
[1] Scaling Distributed Machine Learning with the Parameter Server
[2] Large Scale Distributed Deep Networks, DistBelief, 2012
[3] Parameter Server for Distributed Machine Learning
[4] 【深度学习&分布式】Parameter Server 详解, http://blog.csdn.net/cyh_24/article/details/50545780
[5] 【深度学习系列4】深度学习及并行化实现概述, http://djt.qq.com/article/view/1245
[6] 最近比较火的parameter server是什么?https://www.zhihu.com/question/26998075
[7] parameter_server架构, http://blog.csdn.net/stdcoutzyx/article/details/51241868
[8] DistBelief 框架下的并行随机梯度下降法 - Downpour SGD, http://blog.csdn.net/itplus/article/details/31831661
[9] 谷歌要构建10 亿+ 级别的超大数据集,这样能取代机器学习算法吗?http://www.sohu.com/a/156598020_323203
[10] 学界 | 超越ImageNet:谷歌内建300M图像数据集揭露精度与数据的线性增长关系, http://www.sohu.com/a/156495509_465975
[11] 2017 - Revisiting Unreasonable Effectiveness of Data in Deep Learning Era
[12] Adam:大规模分布式机器学习框架, http://blog.csdn.net/stdcoutzyx/article/details/46676515
[13] 十分钟了解分布式计算:Petuum, http://www.cnblogs.com/wei-li/p/Petuum.html
[14] 分布式深度学习(I):分布式训练神经网络模型的概述,https://blog.skymind.ai/distributed-deep-learning-part-1-an-introduction-to-distributed-training-of-neural-networks/
[15] 谈谈你对”GPU/CPU集群下做到Data/Model Parallelism的区别”的理解?https://www.zhihu.com/question/31999064?sort=created
[16] Hang Su and Haoyu Chen. Experiments on parallel training of deep neural network using model averaging. arXiv preprint arXiv:1507.01239, 2015.
[17] Kai Chen and Qiang Huo. Scalable training of deep learning machines by incremental block training with intra-block parallel optimization and blockwise model-update filtering.
[18] Suyog Gupta, Wei Zhang, and Josh Milthrope. Model accuracy and runtime tradeoff in distributed deep learning. arXiv preprint arXiv:1509.04210, 2015.
[19] Wei Zhang, Suyog Gupta, Xiangru Lian, and Ji Liu. Staleness-aware async-sgd for distributed deep learning. IJCAI, 2016.
[20] Qirong Ho, James Cipar, Henggang Cui, Seunghak Lee, Jin Kyu Kim, Phillip B. Gibbons, Garth A Gibson, Greg Ganger, and Eric P Xing. More effective distributed ml via a stale synchronous parallel parameter server
[21] HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent