走向云计算之Hadoop数据同步框架Sqoop
一、概述
Sqoop即SQL-to-Hadoop,是连接传统关系型数据库和Hadoop 的桥梁,用于把关系型数据库的数据导入到 Hadoop 系统 ( 如 HDFS HBase 和 Hive) 中;也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。Sqoop利用MapReduce加快数据传输速度,并且采用批处理方式进行数据传输。
Sqoop具有以下优势:
- 高效、可控地利用资源,例如任务并行度,超时时间等
- 可自行设置数据类型映射与转换
- 可自动进行,用户也可自定义
- 支持多种数据库,例如:MySQL,Oracle,PostgreSQL等。
二、Sqoop的基本架构和操作
Sqoop的基本架构图如下:
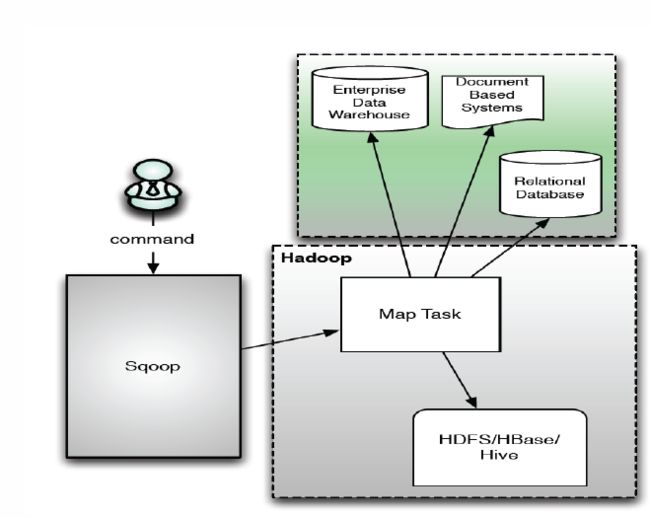
1、运行流程
Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。其运行流程如下:
1.读取要导入数据的表结构,生成运行类,默认是QueryResult,打成jar包,然后提交给Hadoop
2.设置好job,主要也就是设置好以上第六章中的各个参数
3.这里就由Hadoop来执行MapReduce来执行Import命令了,
1)首先要对数据进行切分,也就是DataSplit
DataDrivenDBInputFormat.getSplits(JobContext job)2)切分好范围后,写入范围,以便读取
DataDrivenDBInputFormat.write(DataOutput output) 这里是lowerBoundQuery and upperBoundQuery
3)读取以上2)写入的范围
DataDrivenDBInputFormat.readFields(DataInput input)4)然后创建RecordReader从数据库中读取数据
DataDrivenDBInputFormat.createRecordReader(InputSplit split,TaskAttemptContext context)5)创建Map
TextImportMapper.setup(Context context)6)RecordReader一行一行从关系型数据库中读取数据,设置好Map的Key和Value,交给Map
DBRecordReader.nextKeyValue()7)运行map
TextImportMapper.map(LongWritable key, SqoopRecord val, Context context)最后生成的Key是行数据,由QueryResult生成,Value是NullWritable.get()
2、命令详解
Sqoop总共有14个命令,包括:codegen,create-hive-table, eval, export, help, import, import-all-tables, import-mainframe, job, list-databases, list-tables, merge, metastore, version。其中常用命令为create-hive-table, export, import, help等。
sqoop命令格式:sqoop ,也就是说sqoop的所有命令有公用的参数列表,除此之外每个命令都有自己特定的执行参数。
- help
help命令主要作用是查看sqoop提供的帮助信息,命令格式如下:sqoop help [。
help后面的参数为sqoop支持的命令名称。如果不给定help后面的参数,那么表示显示sqoop命令的帮助信息,如果给定后面的参数,那么表示显示具体sqoop命令的帮助信息。 实例:
1. sqoop help
2. sqoop help list-tables- list-tables&list-databases
list-tables和list-databases两个命令都是针对关系型数据库(可以通过jdbc连接的数据库/数据仓库)而言的,我们一般可以通过该命令查看对应数据库中的table&database的列表。基本命令格式为: sqoop (list-tables|list-databases) --connect jdbc_url --username user_name --password user_pwd
实例:
sqoop list-tables --connect jdbc:mysql://hh:3306/hive --username hive --password hive
sqoop list-databases --connect jdbc:mysql://hh:3306/hive --username hive --password hive- create-hive-table
create-hive-table命令根据关系型数据库中的表创建hive表,不进行数据的copy,只进行表结构的copy。如果hive中存在要创建的表,默认情况下不进行任何操作。命令格式:sqoop create-hive-table --connect jdbc_url --username db_name --password db_pwd --table db_table_name --hive-table hive_table_name
实例:
sqoop create-hive-table --connect jdbc:mysql://hh:3306/test --username hive --password hive --table test --hive-table hivetest- import
import命令的主要作用是将关系型数据库中的数据导入到hdfs文件系统中(或者hbase/hive中),不管是导入到hbase还是导入到hive中,都需要先导入到hdfs中,然后再导入到最终的位置。一般情况下,只会采用将关系型数据库的数据导入到hdfs或者hive中,不会导入到hbase中。import命令导入到hdfs中默认采用’,’进行分割字段值,导入到hive中默认采用’\u0001’来进行分割字段值,如果有特殊的分割方式,我们可以通过参数指定。
import命令导入到hive的时候,会先在/user/${user.name}/文件夹下创建一个同关系型数据库表名的一个文件夹作为中转文件夹,如果该文件夹存在,则报错。可以通过命令sqoop help import查看import命令的帮助信息。
实例:
sqoop import --connect jdbc:mysql://hadoop-master:3306/hive --username root --password admin --table TBLS --fields-terminated-by '\t'- export
export命令的主要作用是将hdfs文件数据导入到关系型数据库中,不支持从hive和hbase中导出数据,但是由于hive的底层就是hdfs的一个基本文件,所以可以将hive导出数据转换为从hdfs导出数据。导出数据的时候,默认字段分割方式是’,’,所以如果hive的字段分割不是’,’,那么就需要设计成对应格式的分割符号。可以通过命令:sqoop help export查看export命令的详细参数使用方式&各个参数的含义。
注意:前提条件,关系型数据库中目的表已经存在。
实例:
sqoop export --connect jdbc:mysql://hh:3306/test --username hive --password hive --table test2 --export-dir /test三、Sqoop的导入导出示例
1、import操作
这里假设我们已经在hadoop-master服务器中安装了MySQL数据库服务,并使用默认端口3306。需要注意的是,sqoop的数据库驱动driver默认只支持mysql和oracle,如果使用sqlserver的话,需要把sqlserver的驱动jar包放在sqoop的lib目录下,然后才能使用drive参数。
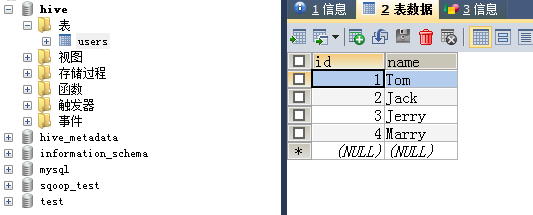
(1)首先创建MySQL数据源:mysql中的hive数据库的users表,内容如下:
(2)使用import命令将mysql中的数据导入HDFS:
import命令的基本格式如下:
sqoop ##sqoop命令
import ##表示导入
--connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
--username root ##连接mysql的用户名
--password admin ##连接mysql的密码
--table mysql1 ##从mysql导出的表名称
--fields-terminated-by '\t' ##指定输出文件中的行的字段分隔符
-m 1 ##复制过程使用1个map作业
--hive-import ##把mysql表数据复制到hive空间中。如果不使用该选项,意味着复制到hdfs中 这里将mysql中的users表导入到hdfs中(默认导入目录是/user/root/),通过运行如下命令:
sqoop import --connect jdbc:mysql://sparkproject1:3306/hive --username root --password root --table users --fields-terminated-by '\t'运行完毕后查看HDFS目录:
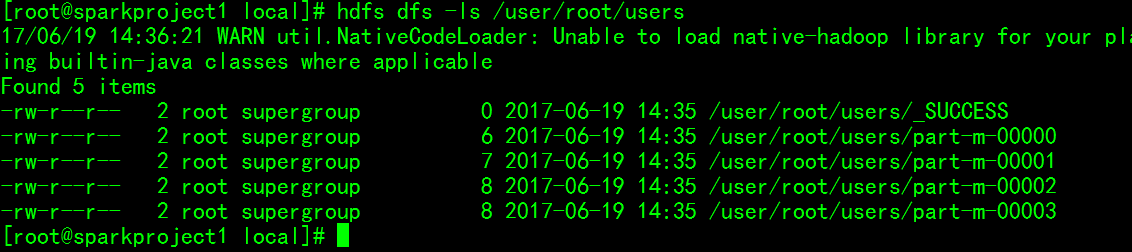
可以看到users表存入了多个map任务所生成的文件中。
(3)刚刚看到了默认是由多个map来进行处理生成,可以设置指定数量的map任务。又由于sqoop默认不是追加方式写入,还可以设置其为追加方式写入已有文件末尾:使用如下命令
sqoop import --connect jdbc:mysql://sparkproject1:3306/hive --username root --password root --table users --fields-terminated-by '\t' --null-string '**' -m 1 --append运行完毕后查看HDFS目录:

(4)还可以将MySQL中的数据导入Hive中(你设定的hive在hdfs中的存储位置,我这里是/user/hive/):
首先得删掉刚刚导入到hdfs中的文件数据:
hdfs fs -rmr /user/root/*然后再通过以下命令导入到hive中:
sqoop import --connect jdbc:mysql://sparkproject1:3306/hive --username root --password root --table users --hive-table hivetest --hive-import -m 1运行完毕后查看HDFS目录:
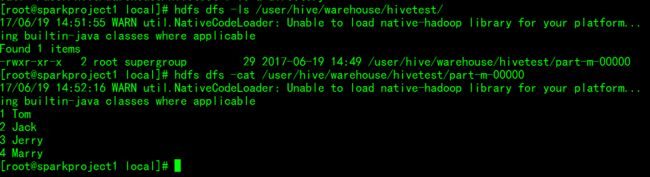
2、export操作
(1)要导出到MySQL,那么首先得要有一张接收从HDFS导出数据的表。这里为了示范,只创建一个简单的数据表IDS,只有一个int类型的id字段。如下:

(2)使用export命令进行将数据从HDFS导出到MySQL中,可以看看export命令的基本格式:
sqoop
export ##表示数据从hive复制到mysql中
--connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
--username root ##连接mysql的用户名
--password admin ##连接mysql的密码
--table mysql2 ##mysql中的表,即将被导入的表名称
--export-dir '/user/root/warehouse/mysql1' ##hive中被导出的文件目录
--fields-terminated-by '\t' ##hive中被导出的文件字段的分隔符注意:导出的数据表必须是事先存在的
(3)准备一个符合数据表规范的文件ids并上传到HDFS中,作为导出到MySQL的数据源:这个ids里边只有10个数字
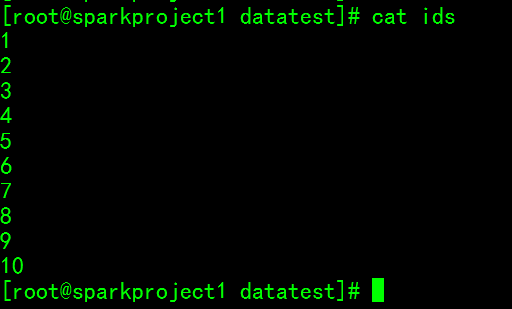
(4)将HDFS中的ids导出到mysql中的TEST_IDS数据表中
sqoop export --connect jdbc:mysql://sparkproject1:3306/hive --username root --password root --table IDS --export-dir /mysql/ids(5)查看结果: