redis 内存管理
在说到redis的内存管理,先来聊下redis的一个命令是怎么执行的。
例如 set test “hello word”
redis 在内部形成了一个如下的结构
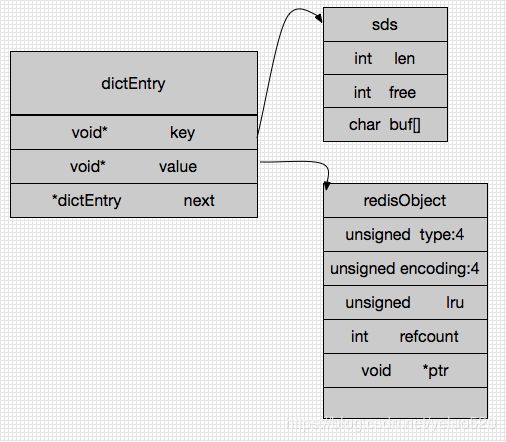
dictEntry key 就是test 存储的结构是sds,下面会说到sds 是一个字符串的存储结构,value形成一个redisObject类型, 定义如下
struct redisObject {
unsigned type:4 //对象类型
unsigned encoding:4 // 编码类型 对应redis里面存储的编码类型 也就是数据类型
unsigned lru // 最后一次访问时间
void *ptr // 数据对应类型的存储地址
}
对象类型: 字符串 列表 集合 有序集合 hash列表 每个类型分别对应了redis的不同操作命令
编码类型: 数据在redis中的数据类型,如下: 整数 embstr 简单动态字符串 字典 双向链表 压缩列表 整数集合 跳跃表
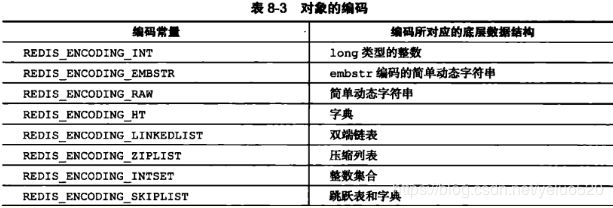
对象类型和编码类型(数据结构的类型)
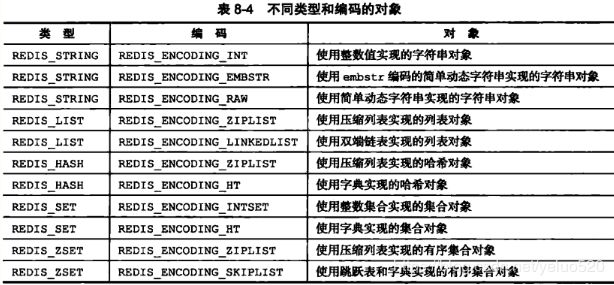
来看下redis中的数据结构
1. string
字符串,浮点,整形的底层存储, 结构如下
struct sdshdr {
int len // 大小
int free // 剩余空间
char buf[] // 存储的值 \0 标识结束
}
string的数据结构包含3种编码类型,int row embstr 他们就是内存分配不一样 int和embstr一次内存分配,row是两次内存分配(大块内存比较珍贵),当存储的时间是int的时候选择 int编码,当存储字符或浮点数的位数小于32是选择的是 embstr, 当data大于32位 选择的是row,内存结构如下
一次内存分配 连续内存
![]()
二次内存分配 内存可能不连续
![]()
内存的管理
1.扩容 预分配 小于1M 当前len的2倍,大于1M,分配1M的空间。
2.缩减 懒性释放 在当前字符串长度缩减时,并不会释放空间,仅仅改变fee的值。
2. 双向列表 linkedlist
list的底层实现数据结构之一,来看下它的定义
struct ListNode{
listNode *pre
listNode *next
void *data // 指向sds对象的指针
}
struct List {
ListNode *head
ListNode *tail
void *(*dup)(void *ptr) // 值copy函数
void (*free)(void *ptr) // 节点释放函数
int (*match)(void *ptr, void *key) // 函数则用于对比链表节点所保存的值和另一个输入值是否相等
unsigned long len // 链表长度
}
结构如下
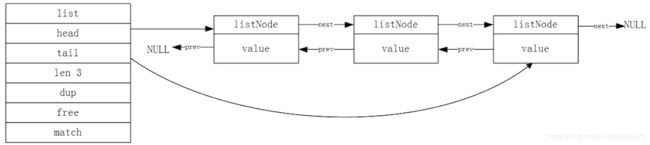
问题
- match函数做什么的
- free函数如何释放内存
3.字典 dict
字典也就是我们所说的hashmap,实现o(1)的操作, 结构如下
struct dict {
dictType *type; // 特定类型函数
void *privdata; // 私有数据
dictht ht[2] // hash 表
int rehashidx; // rehash进度 当 rehash 不在进行时,值为 -1
int iterators; // 目前正在运行的安全迭代器的数量
}
###### Hash 表
typedef struct dictht {
dictEntry **table; // hash 数组
unsigned long size; // hash表大小
unsigned long sizemask; // hash表掩码 size-1用来计算hash值
unsigned long used; // hash表元素个数
}
###### 元素结构
struct dictEntry {
void *key; // 元素的key
union {void *val;uint64_t u64;int64_t s64;} v; // data数据
struct dictEntry *next; // 拉链法解决hash冲突
}
###### hash操作相关函数
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); // 计算哈希值的函数
void *(*keyDup)(void *privdata, const void *key); // 复制键函数
void *(*valDup)(void *privdata, const void *obj); //复制值函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 对比键的函数
void (*keyDestructor)(void *privdata, void *key); // 销毁键的函数
void (*valDestructor)(void *privdata, void *obj); // 销毁值的函数
} dictType;
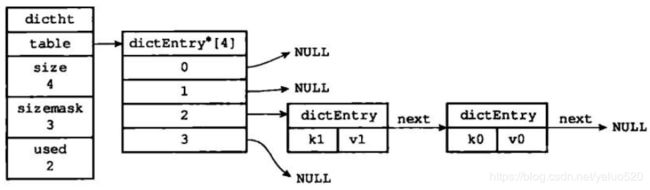
内存结构图
复制键函数
销毁键函数
dictEntry 结构字段的含义,key 指向sds队形的指针 v 联合体 存储指针或存储整数或浮点数
哈希扩容
当hash表中的数据量逐渐增多,hash 碰撞增大,处理冲突的链表长度边长,这时间就需要扩容了。redis里面有个算法计算hash表的负载,当负载因子大于某个临界值之后,hash表就开始扩容。redis 采取的是渐进式hash,简单来说 一次搬一点 一次搬一点。dict 中有个属性dictht,他是个包含两个元素的数组,正常的时候只使用dictht[0],扩容的时候dictht[1]开始使用,1的大小是0的二部,扩容有个标志rehashidx 扩容时为1,正常为0,当访问表中的某一个key的时候,如果key在dictt[0]中,先把元素从0搬到1中,在返回。直到dictht[0]为空,1变成0,rehashidx置为-1。为什么选择渐进式hash,哈希表里保存的键值对数量是四百万、四千万甚至四亿个键值对,那么要一次性将这些键值对全部rehash到ht[1]的话,庞大的计算量可能会导致服务器在一段时间内停止服务。因此,为了避免rehash对服务器性能造成影响。
4. 压缩列表
3.2版本之后改为quicklist列表了 还没仔细看
5. 跳跃表
跳跃表是有序集合的一种实现,它本质是是变型的有序列表,有序链表在正常情况下插入和查找的时间复杂度o(n) 跳跃表做到o(lgn)我们来看下
// node 节点
struct zskiplistNode {
robj *obj; // key值
double score; // 分值
struct zskiplistNode *backward; // 下一个节点的位置
struct zskiplistLevel { // 跳跃表的关键
struct zskiplistNode *forward; // 下一个节点的位置
unsigned int span; // 到下一个节点的长度
} level[]; // 层高
} zskiplistNode;
// 压缩列表
struct zskiplist {
struct zskiplistNode *header, *tail; // 头节点,尾节点
unsigned long length; // 节点数量
int level; // 最大层高
} zskiplist;
结构图如下:
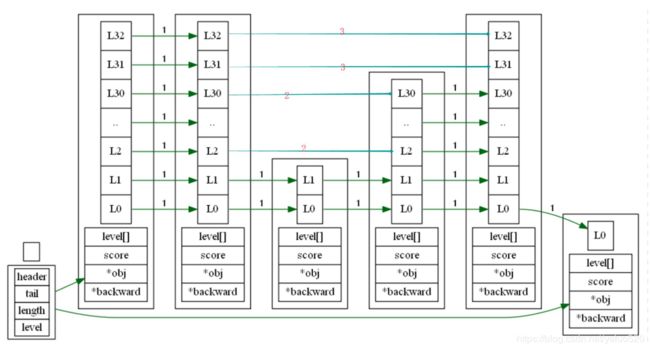
如上的内存结构图,每一层形成一个单项链表,当有个元素插入进来先查zskiplist level层高i,从最高层开始顺序遍历查找,定位元素在该层的范围,记录start位置update[i],然后层高建议从start位置继续查找,定位start位置update[i-1],直到层高i为0,找到具体的位置,更新zskiplistNode.forward 指针值 那两个元素之间,然后在根据插入节点的层高,更新 update数组中zskiplistNode.level[] 中span和forward的值
6. 整数集合
整数集合(intset)是集合键set的底层实现之一: 当一个集合只包含整数值元素, 并且这个集合的元素数量不多时, Redis 就会使用整数集合作为集合键的底层实现。来看下intset的结构
struct intset {
uint32_t encoding; // 编码方式
uint32_t length; // 集合中元素的长度
int8_t contents[]; // 集合元素的数组 有序数组
}
升级和降级