spring data jpa 基础详解
目录
orm思想
导入jpa相关jar包坐标
jpa核心配置文件
约束文件
配置persistence-unit节点
配置jpa 的实现方式和数据库信息
配置实现方的配置信息
配置映射关系
配置主键以及自增长
主键生成策略
排除字段
保存数据测试
解决创建实体管理工厂的耗费问题
增删改查和事务的方法
延迟查询
JPQL查询语句
spring data jpa
导入spring data jpa相关jar坐标
spring配置文件
配置EntityManagerFactory 实力类管理工厂
配置厂家(hibernate)的适配器(相关属性)
配置hibernate高级特性
自动创建表
配置数据库连接池
整合spring dataJPA并配置声明式事务
配置注解扫描
写符合spring data jpa规范的dao层接口
测试接口
spring data jpa提供的CRUD方法
延迟查询
JPQL在接口中的应用(复杂查询)
多个参数占位符问题
JPQL更新操作(牵扯事务)
sql查询全部
方法名称规则查询
动态查询(类似离线查询)
创建Specification
Specification查询单个对象
多条件拼接
动态模糊查询列表
动态排序查询
动态分页查询
多表操作
一对多
放弃外键维护
级联添加
级联删除
多对多操作
多对多放弃外键维护
多对多级联操作
多表查询(对象导航查询)
设置延迟加载
前言
hibernate基础 https://blog.csdn.net/yzj17025693/article/details/88604879
hibernate应用 https://blog.csdn.net/yzj17025693/article/details/89010962
spring data jpa 是一种规范,而hibernate是实现了spring data jpa规范最好的框架
如果你已经学习了hibernate,那么学习spring data jpa就和玩一样的
orm思想

只需要你建立实体类和表的关系,以及实体类属性和表属性的关系,那么 实现了orm思想的框架
就会给你自动生成sql语句

导入jpa相关jar包坐标
这里使用的是hibernate-entitymanager,是hibernate对jpa支持的包
hibernate-c3p0是连接池

jpa核心配置文件
需要在META-INF文件下创建persistence.xml(坚持,固执,大概意思是 持久化)
目前来说,名称和位置都必须和图中一样

约束文件
直接在idea里有
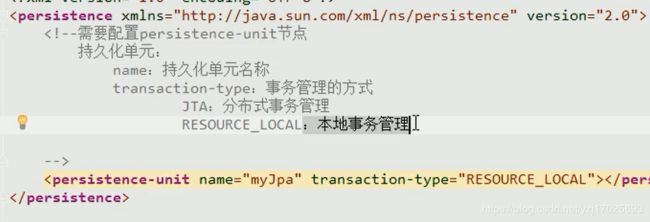
配置persistence-unit节点
持久化单元名称随便填,测试的时候需要这个name
事务管理方式,本地事务一般用resource_local
而JTA是分布式事务管理,因为不同的数据库,连接对象是不同的,事务也不同,这时候需要用到分布式事务
配置jpa 的实现方式和数据库信息
这里拿hibernate做实现方式
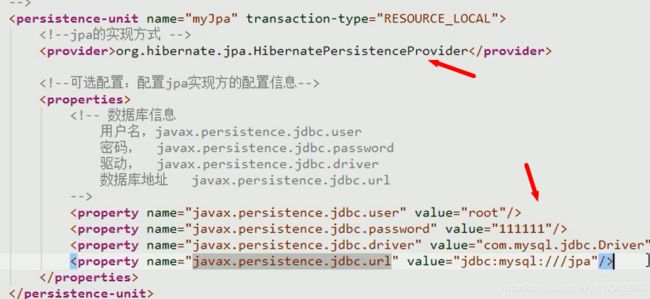
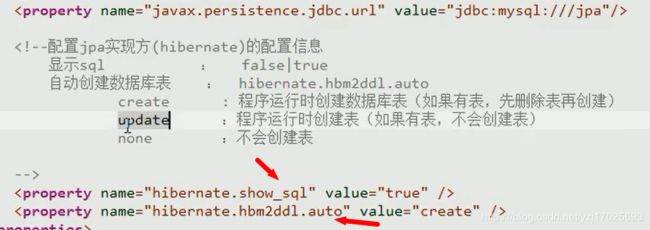
配置实现方的配置信息
这里是hibernate,那么就配置hibernate的配置,hibernate有show_sql,也有自动创建表的功能
而jpa就可以配置
根据数据库创建实体类(后面会有逆向工程)
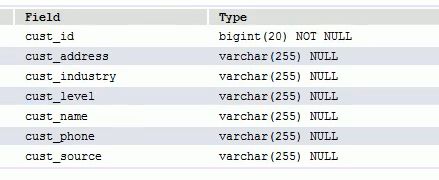

配置映射关系
把实体类和表中的结构一一对应起来
这里使用jpa注解的方式

配置主键以及自增长
generated 生成策略
使用了GeneratedValue,在插入这个实体后,能自动获取到插入的主键,不需要像mytatis一样写keyProperty

除了主键其余属性均使用Column对应关系即可

主键生成策略
第3种是jpa帮我们生成的主键,和数据库没关系,它会自动帮我们生成一张表,这表里面有我们的主键值
第4种是 由jpa自动帮我们选择的生成策略,一般来说只建议使用一二种

如果数据库和表的名称一致,只需要注解一下实体类,并且配置一下id,其他属性如果名称也和数据库一致,那么不用配置
但是需要配置 hibernate.cfg.ImprovedNamestrategy
https://blog.csdn.net/jiesa/article/details/49052827

回显主键
keySql是回显id
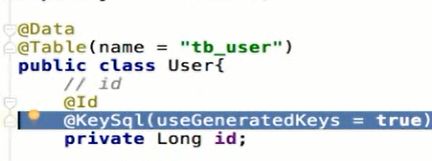
排除字段
如果想把某个字段不作为数据的字段,那么使用Transient(瞬间)

保存数据测试
1 创建实体管理器工厂,
2 从工厂获取实体管理器,
3 从管理器获取事务对象
4 开启事务,进行增删查改,提交事务
5 释放资源

工厂需要指定持久化单元的名称
persist是保存操作,相当于把对象持久化

解决创建实体管理工厂的耗费问题
首先实体管理工厂EntityManagerFactory是线程安全的
所以多个线程同时访问EntityManagerFactory不会有线程安全问题,而如果多个线程访问EntityManagerFactory
那么就需要创建多个EntityManagerFactory,这样就会非常的耗费资源和时间
所以我们需要把EntityManagerFactory做成一个工具类
就和学习hibernate的时候,解决session工厂是一样的,后面会通过spring整合由spring来创建
这里只获取到实体类管理器,并没有顺带把session创建了,是因为session不是线程安全的
多个线程访问一个线程不安全的资源会触发线程安全问题

增删改查和事务的方法
presist (持久化,也就是保存)
merge(合并,吞没,相当于更新)
getRefrence(获取引用)

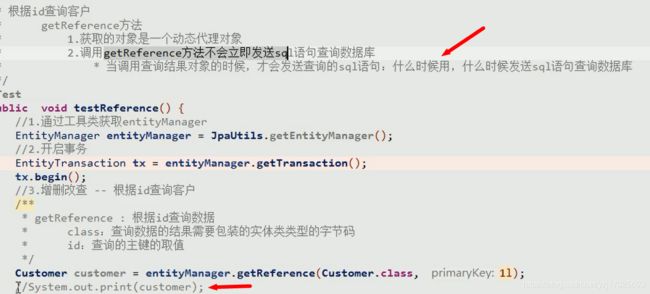
根据id查询
传入实体类字节码,传入主键的值,这里1L 是因为主键是Long类型,在数据库里是bigint类型
这些和hibernate非常相似

延迟查询
延迟加载的应用可以在hibernate基础篇里找到
查询有2个方法,一个是find,一个是getRefrence
使用调试模式下运行,可知
getRefrence是一个延迟加载,调用的时候并不会发送sql语句给数据库,这时候会返回一个代理对象给我们
当需要使用到查询出来的对象时,才会去发送sql语句,然后把数据填满到代理对象里,这个代理对象和我们的对象一模一样
在多表查询的时候,有些关联的数据我们并不想一下查询出来,因为可能不需要,这样就会浪费资源
但是其实延迟加载还有一些问题(后面会讲)
删除数据
需要先查询出实体类后再进行删除,这样能保证不会删除空的东西
orm框架会自动通过实体类的对象主键删除对应的数据

更新操作
更新操作也需要先查询出数据

JPQL查询语句

查询全部(查询单个用find或者getRefrence即可)

倒叙查询

统计查询
使用聚合函数和别名的时候前面需要加上select
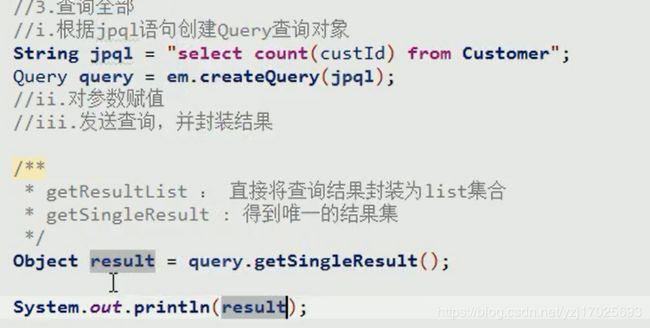
分页查询


条件查询


spring data jpa
其实上面都是在讲jpa的规范和简单操作
而spring data jpa是用来进行数据持久化的解决方案,可以用来完全

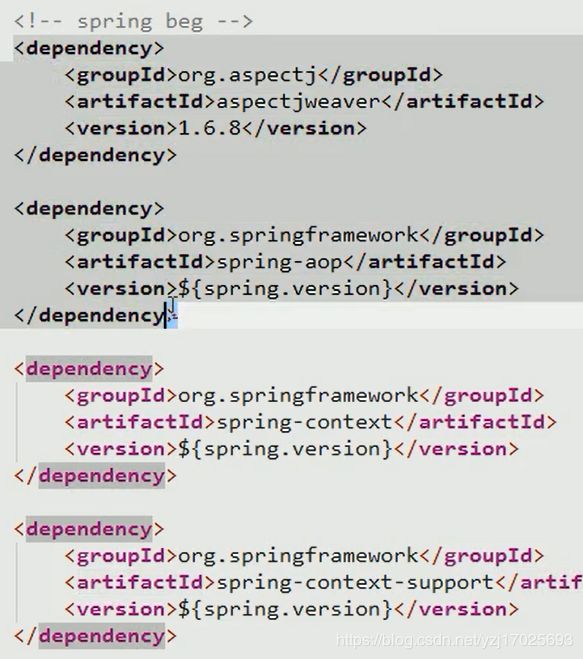
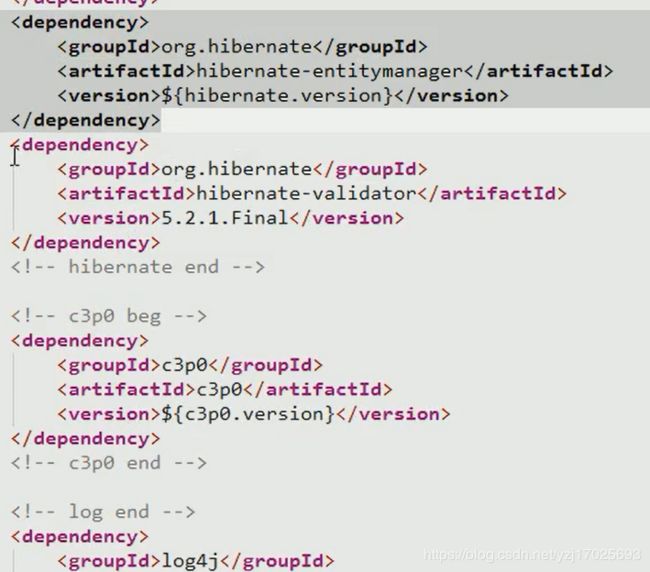
导入spring data jpa相关jar坐标
需要导入spring的常用jar包
导入spring-orm
以及hibernate支持jpa的jar包,以及hibernate的校验包
最后就是导入spring-data-jpa的包
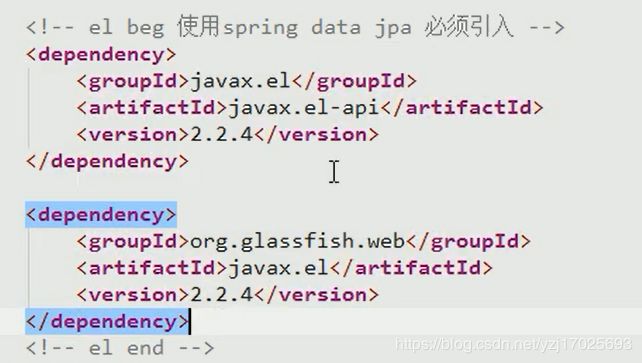
还有2个必须导入的表达式包,2个EL


spring配置文件
约束头
约束头直接添加2jpa的支持即可

配置EntityManagerFactory 实力类管理工厂
需要注入dataSource,也就是数据库连接源
需要扫描实体类
需要执行实现jpa的厂家,这里使用的是hibernate

配置厂家(hibernate)的适配器(相关属性)

配置hibernate高级特性
也就是说jpa也拥有了hibernate的高级特性
比如一级缓存(重复查询不会发送sql语句,节省资源),二级缓存(存指定数据,后面用redis代替)

自动创建表

配置数据库连接池
这里使用的是c3p0连接池,默认的是

整合spring dataJPA并配置声明式事务
也就是说我们的dao 不需要继承xxxSupportDao然后注入dataSource(详情见ssh整合)
ssh整合 https://blog.csdn.net/yzj17025693/article/details/88751198

Platform(平台)TransactionManager 平台事务管理器是一个接口
需要用他的实现类
可以看它有什么实现类,这里是我们使用jpa
这是属于声明式事务管理,而我们一般会使用注解事务管理

配置注解扫描

写符合spring data jpa规范的dao层接口
这部分如果学过mybatis的会很容易理解 https://blog.csdn.net/yzj17025693/article/details/89196963
jpaSpecificationExecutor (jpa规范执行者)
这个类里基础的操作并不需要写任何方法,
这需要注意的,类不能多继承,但是接口却可以
JpaRepository的第二个泛型的类型是Customer的主键的数据类型

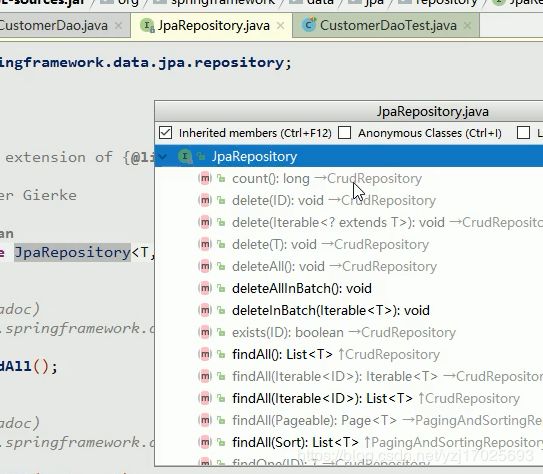
测试接口
我们发现使用customerDao能使用findOne方法,这就是接口里2个父类提供的方法

spring data jpa提供的CRUD方法

保存或更新


删除

查询单个

查询所有

cout方法
统计数量

exists方法

延迟查询
transactional是事务,一般不会用在查询上,而是用在添加,删除,更新上

JPQL在接口中的应用(复杂查询)
我们在简单的jpa里,已经使用了JPQL,只需要createQuery即可
现在在接口中,我们需要在接口里写上方法,并且在方法上写上JPQL查询语句
这里Customer换成List

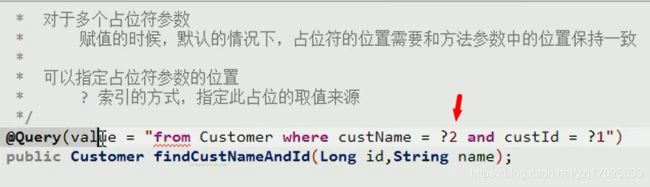
多个参数占位符问题
这个问题在mytatis里就遇到了差不多的问题,mybatis是使用param注解解决
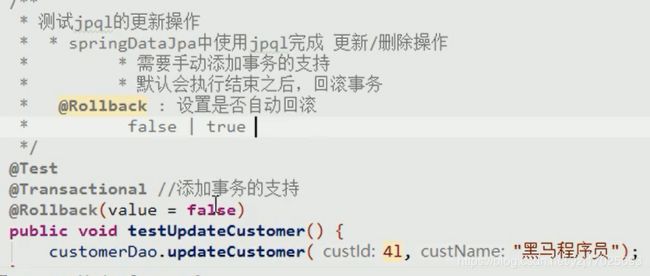
JPQL更新操作(牵扯事务)
需要在Query语句的下面声明Modifying
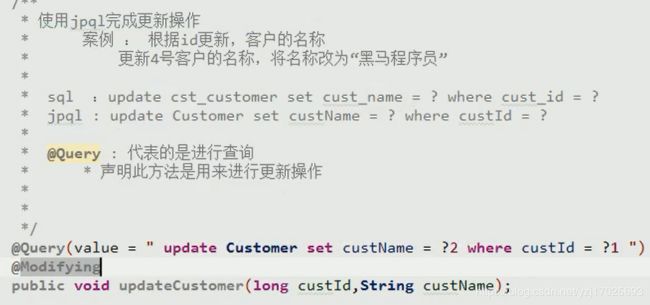
使用增删改操作有能需要注解上transactional和Rollback
使用sql语句
在query还有一个参数

sql查询全部
注意,返回的类型List[Object],不是具体的类
如果想要条件查询,也可以使用占位符,和JPQL一样


方法名称规则查询
只需要按照规则定义方法即可,不需要写jpql语句



方法命名规则--模糊查询


方法命名规则--多条件查询
![]()
这时候参数就必须一一对应的,不能搞乱位置

如果确定只有一个结果,可以使用一个对象,不然还是需要使用List

动态查询(类似离线查询)
离线查询可以无限的添加条件,并且可以在controller和service层传递
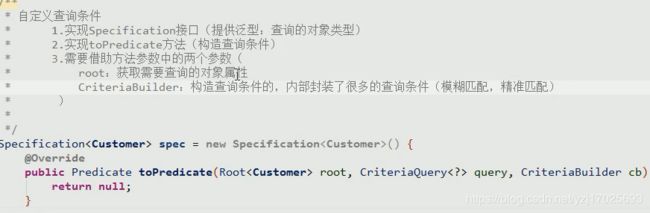
Specification(规范),在下面就是查询条件


创建Specification
它是一个匿名内部类
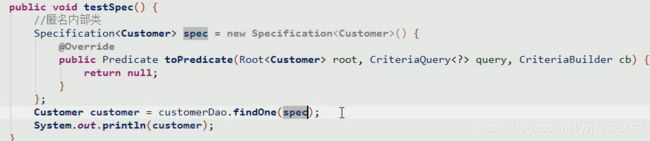

Specification查询单个对象
传递名称条件

多条件拼接


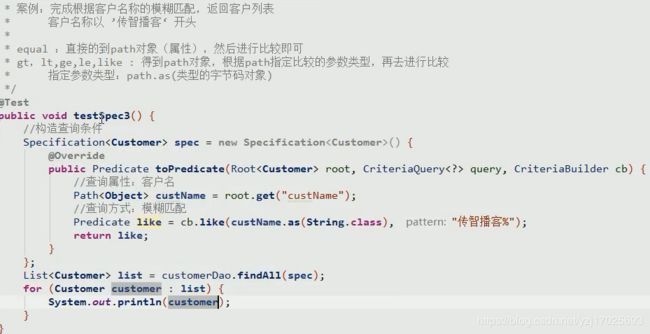
动态模糊查询列表
注意like,gt,lt这些比较查询,都需要指定需要比较的类型
动态排序查询

动态分页查询



多表操作
一对多


在客户的实体类里写上联系人的集合

配置一对多关系
只需要配置对应的外键和主键即可

配置多对一的关系

一对多保存操作
箭头所指的地方便是关联关系的地方


多对一保存操作

放弃外键维护
上面一对多保存的方法执行后,多执行了一条update语句


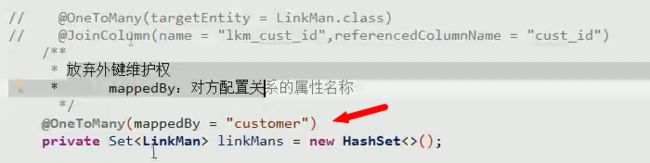
上面的mappedBy先当于参照于对方

级联添加
在一的一方的实体类的多的一方的属性上配置
当使用一的一方进行保存操作的时候,如果已经关联了多的一方,那么多的一放会被一同保存
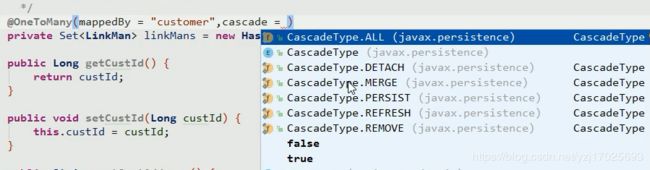

级联删除
因为多表关系的删除,是不能直接删除被关联的一方,也就是一的一方


多对多操作

多对多相当于2个多对一


多对多放弃外键维护
因为2个都能维护外键,都到数据库的中间表去插入数据,并且是相同的数据,所以主键会冲突
需要一方放弃外键,一般是被动的一方放弃,比如用户选角色,那么就是角色放弃外键维护

配置mappedBy

多对多级联操作
和一对多级联的思想是一样的,在user实体类的role属性上配置级联
那么当操作user保存的时候,如果user和role关联了,那么role也会一起被保存到数据库
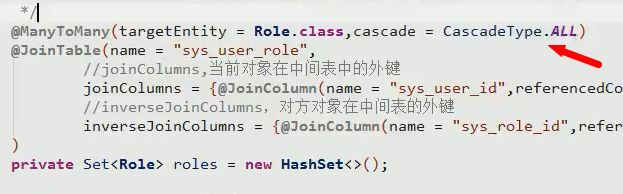
下面双方互相关联,需要配置被动的一方放弃外键维护

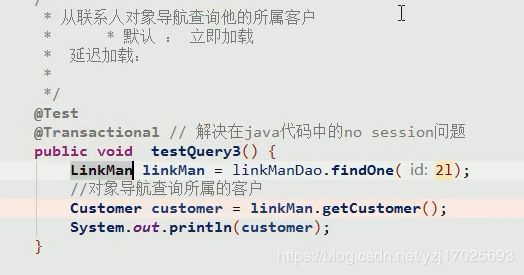
多表查询(对象导航查询)

设置延迟加载

如果不设置延迟加载,那么查询了联系人(多的一方)后变会立即查询客户(一的一方),
这时候在联系人里设置延迟加载,就不会查询联系人的时候查询立即查询客户