nodejs 做一个简单的爬虫
文章目录
- 前言
- 准备工作
- 创建工程
- 武大计算机学院新闻爬虫代码
- 草榴技术讨论区爬虫
- 后记
前言
(前言是废话可以略过)感觉我写的已经很基础了,就算没有编程经验的人应该也能做出来吧?
起因是昨天中午在 stromzhang 的知识星球(会不会有广告嫌疑)上看到一个球友分享了这么一篇东西
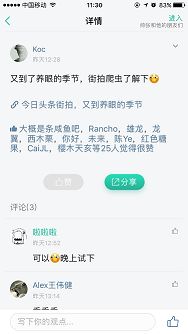
链接如下:
今日头条街拍,又到养眼的季节
作为一个程序员,到现在还没尝试过爬虫,感觉自己很 low,当然不是为了街拍图片。
点进去一看,好吧,是我并没有用过的 python。
但是既然已经点燃了我想爬的愿望,不爬的话就很难受。因为学过 js,知道 js 也可以做爬虫,于是到网上搜了一下,万能的 js 果然无所不能。
于是在网上搜到了这么一篇文章 手把手教你做爬虫—基于NodeJs 于是就按照他的步骤开始做,不过北大的微电子学院好像禁止访问了,大概是被爬的次数太多,服务器崩了?还有人说爬完一次之后 IP 就会被禁止访问。
既然这样,只能拿武大开刀了。
准备工作
- 首先,你需要下载 nodejs,这个应该没啥问题吧
- 原文要求下载 webstrom,我电脑上本来就有,但其实不用下载,完全在命令行里面操作就行
创建工程
准备工作做完了,下面就开始创建工程了
- 首先,在你想要放资源的地方创建文件夹,比如我在 E 盘里面创建了一个 myStudyNodejs 的文件夹
- 在命令行里面进入你创建的文件夹 如图
进入 e 盘:E:
进入文件夹:cd myStudyNodejs(你创建的文件夹的名字)
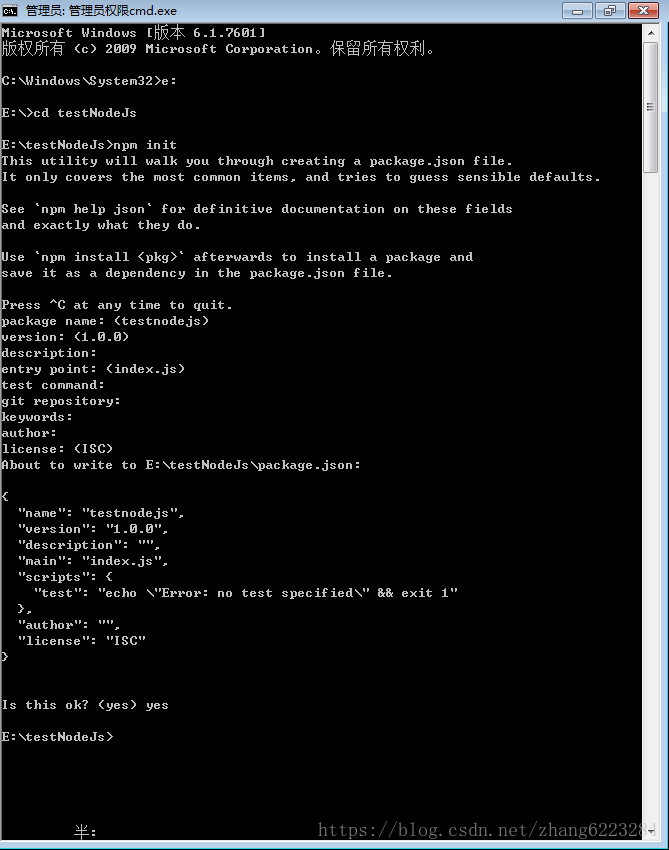
注意全是英文符号 - 初始化项目,在你创建的文件夹下面运行 npm init 初始化项目
一路回车,最后输个 yes 就行 - 运行完以后,会在文件夹里面生成一个 package.json 的文件,里面包含了项目的一些基本信息。
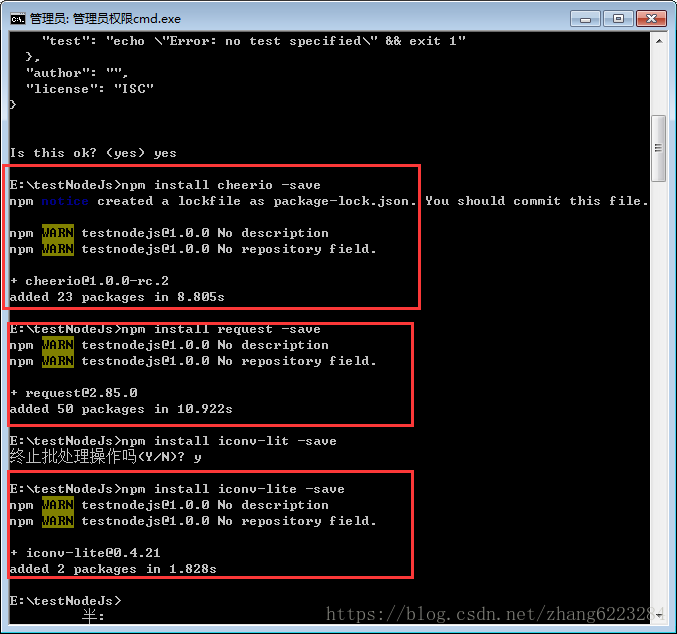
- 安装所需要的包
在所创建的文件夹的目录下运行
npm install cheerio –save
npm install request -save
爬武大的话,这两个包就够了,如果想爬草榴需要额外的转换编码的包,windows 上面是
npm install iconv-lite -save
Mac 上面是 npm install iconv -save
运行结果应该第二幅图这样,中间手滑少写了个字母 - 创建文件
在你所创建的文件夹下面创建一个 data 文件夹用于保存爬到的文本数据。
创建一个 image 文件夹用于保存图片数据。
创建一个 js 文件用来写程序。比如 study.js。(创建一个记事本文件将 .txt 改为 .js)
说明 –save 的目的是将项目对该包的依赖写入到 package.json 文件中。
武大计算机学院新闻爬虫代码
下面就是武大计算机学院新闻的爬虫代码了,复制到创建的 .js 文件中,保存。
var http = require('http');
var fs = require('fs');
var cheerio = require('cheerio');
var request = require('request');
var i = 0;
//初始url
var url = "http://cs.whu.edu.cn/a/xinwendongtaifabu/2018/0428/7053.html";
function fetchPage(x) { //封装了一层函数
startRequest(x);
}
function startRequest(x) {
//采用http模块向服务器发起一次get请求
http.get(x, function (res) {
var html = ''; //用来存储请求网页的整个html内容
var titles = [];
res.setEncoding('utf-8'); //防止中文乱码
//监听data事件,每次取一块数据
res.on('data', function (chunk) {
html += chunk;
});
//监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数
res.on('end', function () {
var $ = cheerio.load(html); //采用cheerio模块解析html
var news_item = {
//获取文章的标题
title: $('div#container dt').text().trim(),
i: i = i + 1,
};
console.log(news_item); //打印新闻信息
var news_title = $('div#container dt').text().trim();
savedContent($,news_title); //存储每篇文章的内容及文章标题
savedImg($,news_title); //存储每篇文章的图片及图片标题
//下一篇文章的url
var nextLink="http://cs.whu.edu.cn" + $("dd.Paging a").attr('href');
str1 = nextLink.split('-'); //去除掉url后面的中文
str = encodeURI(str1[0]);
//这是亮点之一,通过控制I,可以控制爬取多少篇文章.武大只有8篇,所以设置为8
if (i <= 8) {
fetchPage(str);
}
});
}).on('error', function (err) {
console.log(err);
});
}
//该函数的作用:在本地存储所爬取的新闻内容资源
function savedContent($, news_title) {
$('dd.info').each(function (index, item) {
var x = $(this).text();
var y = x.substring(0, 2).trim();
if (y == '') {
x = x + '\n';
//将新闻文本内容一段一段添加到/data文件夹下,并用新闻的标题来命名文件
fs.appendFile('./data/' + news_title + '.txt', x, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
}
})
}
//该函数的作用:在本地存储所爬取到的图片资源
function savedImg($,news_title) {
$('dd.info img').each(function (index, item) {
var img_title = $(this).parent().next().text().trim(); //获取图片的标题
if(img_title.length>35||img_title==""){
img_title="Null";
}
var img_filename = img_title + '.jpg';
var img_src = 'http://cs.whu.edu.cn' + $(this).attr('src'); //获取图片的url
//采用request模块,向服务器发起一次请求,获取图片资源
request.head(img_src,function(err,res,body){
if(err){
console.log(err);
}
});
request(img_src).pipe(fs.createWriteStream('./image/'+news_title + '---' + img_filename)); //通过流的方式,把图片写到本地/image目录下,并用新闻的标题和图片的标题作为图片的名称。
})
}
fetchPage(url); //主程序开始运行
下面就是激动人心的时刻了,在当前文件夹下面,运行创建的 js 文件,比如我的是 news.js。
npm news.js

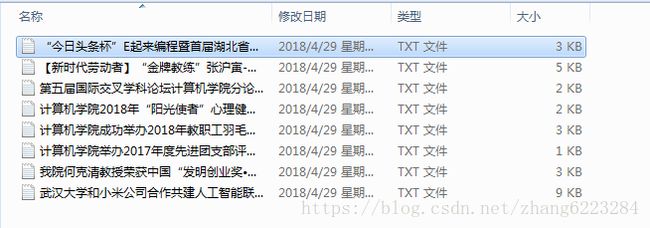
文本资源:
图片资源:
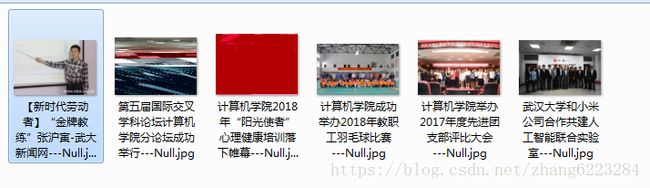
草榴技术讨论区爬虫
爬完武大的新闻并不过瘾,于是尝试了一波爬草榴的技术讨论区(当然也能爬一些你懂的)。其中遇到了一些问题。
爬草榴的时候,发送 http 请求报文头里面需要包含 User-Agent 字段,于是需要把 初始url 做如下改变
var url = {
hostname: 'cl.5fy.xyz',
path: '/thread0806.php?fid=7',
headers: {
'Content-Type': 'text/html',
//没有这个字段的话访问不了
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36',
}};
其次,nodejs 只支持 抓取 utf-8 字符编码的网站,所以需要安装额外的包来转换编码,所以修改代码如下
/*
* @Author: user
* @Date: 2018-04-28 19:34:50
* @Last Modified by: user
* @Last Modified time: 2018-04-30 21:35:26
*/
var http = require('http');
var fs = require('fs');
var cheerio = require('cheerio');
var request = require('request');
var iconv=require('iconv-lite');
var i = 0;
//用来判断存储还是访问
var temp=0;
let startPage=3;//从哪一页开始爬
let page=startPage;
let endPage=5;//爬到哪一页
let searchText='';//爬取的关键字,默认全部爬取,根据自己需要
//初始url
var url = {
hostname: '1024liuyouba.tk',
path: '/thread0806.php?fid=16'+'&search=&page='+startPage,
headers: {
'Content-Type': 'text/html',
//没有这个字段的话访问不了
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36',
}};
//存储首页url
urlList=[];
//封装了一层函数
function fetchPage(x) {
setTimeout(function(){
startRequest(x); },5000)
}
//首先存储要访问界面的url
function getUrl(x){
temp++;
http.get(x,function(res){
var html = '';
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
var buf=new Buffer(html,'binary');
var str=iconv.decode(buf,'GBK');
var $ = cheerio.load(str); //采用cheerio模块解析html
$('tr.tr3 td.tal h3 a').each(function(){
var search=$(this).text();
if(search.indexOf(searchText)>=0){
var nextLink="http://cl.5fy.xyz/" + $(this).attr('href');
str1 = nextLink.split('-'); //去除掉url后面的中文
str = encodeURI(str1[0]);
urlList.push(str); }
})
page++;
if(page<endPage){
//存储下一页url
x.path='/thread0806.php?fid=16'+'&search=&page='+page,
getUrl(x);
}else if(urlList.length!=0){
fetchPage(urlList.shift());
}else{
console.log('未查询到关键字!');
}
})
}).on('error', function (err) {
console.log(err);
});
}
function startRequest(x) {
if(temp===0){
getUrl(x);
}
else{
//采用http模块向服务器发起一次get请求
http.get(x, function (res) {
var html = ''; //用来存储请求网页的整个html内容
res.setEncoding('binary');
var titles = [];
//监听data事件,每次取一块数据
res.on('data', function (chunk) {
html += chunk;
});
//监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数
res.on('end', function () {
var buf=new Buffer(html,'binary');
var str=iconv.decode(buf,'GBK');
var $ = cheerio.load(str); //采用cheerio模块解析html
var news_item = {
//获取文章的标题
title: $('h4').text().trim(),
//i是用来判断获取了多少篇文章
i: i = i + 1,
};
console.log(news_item); //打印信息
var news_title = $('h4').text().trim();
savedContent($,news_title); //存储每篇文章的内容及文章标题
savedImg($,news_title); //存储每篇文章的图片及图片标题
//如果没访问完继续访问
if (urlList.length!=0 ) {
fetchPage(urlList.shift());
}
});
}).on('error', function (err) {
console.log(err);
});
}
}
//该函数的作用:在本地存储所爬取的文本内容资源
function savedContent($, news_title) {
$("div.t2[style] .tpc_content.do_not_catch").each(function (index, item) {
var x = $(this).text();
x = x + '\n';
//将新闻文本内容一段一段添加到/data文件夹下,并用新闻的标题来命名文件
fs.appendFile('./data/' + news_title + '.txt', x, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
})
}
//该函数的作用:在本地存储所爬取到的图片资源
function savedImg($,news_title) {
//创建文件夹
fs.mkdir('./image/'+news_title, function (err) {
if(err){console.log(err)}
});
$('.tpc_content.do_not_catch input[src]').each(function (index, item) {
var img_title = index;//给每张图片附加一个编号
var img_filename = img_title + '.jpg';
var img_src = $(this).attr('src'); //获取图片的url
//采用request模块,向服务器发起一次请求,获取图片资源
request.head(img_src,function(err,res,body){
if(err){
console.log(err);
}
});
setTimeout(function(){
request({uri: img_src,encoding: 'binary'}, function (error, response, body) {
if (!error && response.statusCode == 200) {
fs.writeFile('./image/'+news_title+'/' + img_filename, body, 'binary', function (err) {
if(err){console.log(err)}
});
}
})
});
})
}
fetchPage(url); //主程序开始运行
成果展示:
后记
通过这次学习爬虫的经历,虽然爬草榴的时候经历了很多挫折,也慢慢克服了,不过这个代码应该还是很基础,爬一些大的网站估计不行,所以还是要慢慢学习,就算入门了吧,爬成功带给我的成就感还是很大的。
开心。
修改了一下爬草榴的代码,请求过快好像会被禁止访问,所以就添加了个延时函数,隔5秒申请一次,基本没啥问题
2018/4/30
修改了爬草榴的代码,增加了从哪一页爬到哪一页,并且将爬下来的图片单独创建一个文件夹,而不是全都放在一个文件夹里面
2018-04-30
增加了草榴代码中按关键字查询某几页