关于线程池的执行原理
Executor线程池实现的接口,正如源码中看到的,里面只有一个方法excute,参数是Runnable任务。
public interface Executor {
void execute(Runnable command);
}对于上面接口的扩展,做了如下的一个流程梳理:

(日常核心类的一个关系梳理,不代表全部)
ExecutorService接口扩展了Executor,添加了线程生命周期的管理,提供任务终止、返回任务结果等方法。AbstractExecutorService实现了ExecutorService,提供方法的默认实现逻; 另一条是定时相关的线程池使用,这篇文章赞不介绍。主角登场:ThreadPoolExecutor,继承了AbstractExecutorService,提供线程池的具体实现。我们的核心线程池使用都是围绕着这个类开展的(主角光环),let us来分析下吧
线程池创建
ExecutorService es = Executors.newFixedThreadPool(10);
newFixedThreadPool的corePoolSize和maximumPoolSize都设置为传入的固定数量,keepAliveTim设置为0,毫秒级别的。线程池创建后,线程数量将会固定不变,适合需要线程很稳定的场合
ExecutorService es = Executors.newCachedThreadPool();
newCachedThreadPool生成一个会缓存的线程池,线程数量可以从0到Integer.MAX_VALUE,超时时间为1分钟。线程池用起来的效果是:如果有空闲线程,会复用线程;如果没有空闲线程,会新建线程;如果线程空闲超过1分钟,将会被回收。
ExecutorService es = Executors.newSingleThreadExecutor();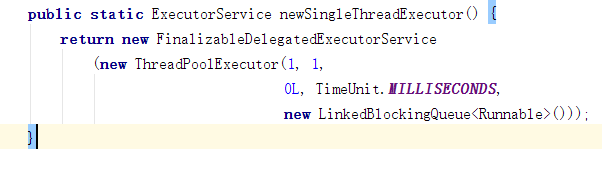
newSingleThreadExecutor目的是生成单线程串行的线程池。注意下该方法的返回的是FinalizableDelegatedExecutorService,这是区别上面的两种的线程池的一个点,想要了解更多可以查看里面的源代码。
ExecutorService es = Executors.newScheduledThreadPool(10);
newScheduledThreadPool将会创建一个可定时执行任务的线程池,这里就不再做多扩展了。
Executors 内部为我们提供了静态的创建线程池的方式,底层实现是基于ThreadPoolExecutor,构造函数如下:

源码中提供了四种构造函数,我们来依次认识下每个参数的含义:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) corePoolSize是线程池的活跃线程数,也叫核心线程数。maximumPoolSize是线程池的最大上限。keepAliveTime指明空闲线程的存活时间,超出存活时间的空闲线程就会被回收。空闲线程:maximumPoolSize减去corePoolSize即叫空闲线程,unit 空闲世家单位,workQueue 指的是工作的缓冲队列,threadFactory :线程工厂,handler:拒绝策略的方式,下图是大概的工作流:

下面详细介绍工作队列、拒绝(饱和)策略。
工作队列
线程池里的工作队列使用了blockingQueue阻塞的工作队列,因为操作系统资源是有限的,任务的处理速度有可能比不上任务的提交速度。因此,提供一个阻塞队列来保存因线程不足而等待的Runnable任务,在内部的任务处理实现也是通过生产者-消费者模式完成处理的。
JDK为BlockingQueue提供了几种实现方式,常用的有:
- ArrayBlockingQueue:数组结构的阻塞队列
- LinkedBlockingQueue:链表结构的阻塞队列
- PriorityBlockingQueue:有优先级的阻塞队列
- SynchronousQueue:不会存储元素的阻塞队列
newFixedThreadPool和newSingleThreadExecutor在默认情况下使用一个无界的LinkedBlockingQueue。要注意的是,如果任务一直提交,但线程池又不能及时处理,等待队列将会无限制地加长,系统资源总会有消耗殆尽的一刻。所以,推荐使用有界的等待队列,避免资源耗尽。但解决一个问题,又会带来新问题:队列填满之后,再来新任务,这个时候怎么办?后文会介绍如何处理队列饱和。
newCachedThreadPool使用的SynchronousQueue十分有趣,看名称是个队列,但它却不能存储元素。要将一个任务放进队列,必须有另一个线程去接收这个任务,一个进就有一个出,队列不会存储任何东西。因此,SynchronousQueue是一种移交机制,不能算是队列。newCachedThreadPool生成的是一个没有上限的线程池,理论上提交多少任务都可以,使用SynchronousQueue作为等待队列正合适。
饱和策略
饱和策略:当线程数达到醉倒maximumPoolSize,且工作队列达到最大,此时触发饱和策略机制。在线程池中定义了4种饱和策略(4个静态内部类):DiscardPolicy(直接抛出异常,默认的饱和策略)
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
DiscardPolicy(直接丢弃当前任务)

DiscardOldestPolicy(丢弃很久不使用的任务)

CallerRunsPolicy (它既不抛弃新任务,也不抛弃旧任务,而是直接在当前线程运行这个任务)
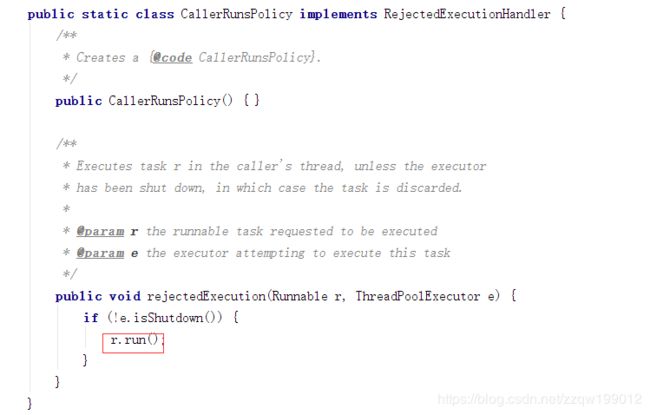
以上四种策略都实现了RejectedExecutionHandler 接口,如果我们在项目中需要重新定义拒绝策略,实现该接口即可。
上面介绍的线程池知识点还是比较泛泛的,里面未提到线程池的工作内部流转,大家感兴趣可以去看看源码,有不对的地方也请指教出来,互相学习。
相对于jdk1.7,1.8在Executoers 中增加了newWorkStealingPool,底层的实现是基于ForkJoinPool实现,具体的实现方式大家可以参考其他文章