KDD2019 论文解读 如何从科研论文中挖掘算法的演变路线?
作者: 殷达 清华大学
每年新的科研论文数量都在不断增长,这给想要快速了解学术领域主流信息的研究人员造成了很大的困扰。为了帮助研究人员克服这一难题,UCSB的学者在KDD2019发表了Mining Algorithm Roadmap in Scientific Publications,提出了能够自动生成学术路线图的算法,刻画不同算法之间的演进路线。
论文题目:Mining Algorithm Roadmap in Scientific Publications
论文作者:Hanwen Zha,Wenhu Chen,Keqian Li,Xifeng Yan
相关工作
在先前的工作中,从文档中抽取概念并构建树状结构是一种描述关系的高效方式。其中主要包含基于语义特征进行模式抽取的做法以及利用聚类间接建立层级结构的做法。然而这些关系的抽取往往局限于“A是B”这样的形态。
主要思路
本文主要聚焦于算法这一概念以及其缩写形态,目标是构建算法的演进路线。GAN算法相关的演变如下图所示。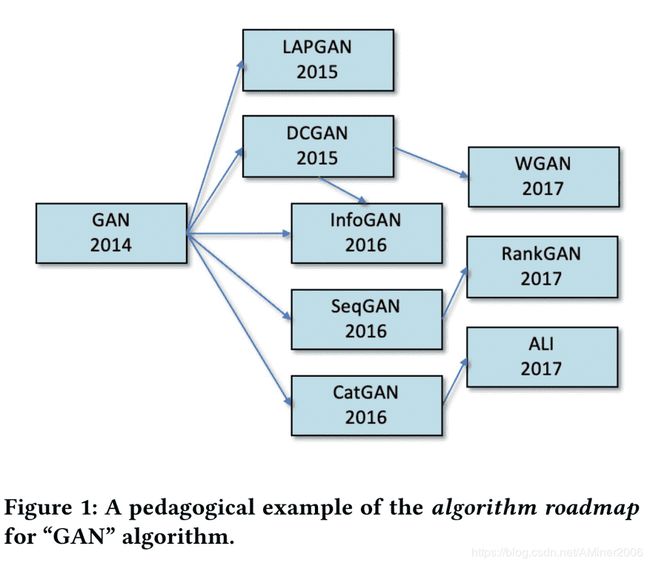
对于路线图的刻画面临的最大的三个问题是:
“标签缺失:由于算法名词经常在发生演变,有标注的算法实体常常过时,而且新算法的出现频率又相对较低。因此无论是对于监督学习方法还是基于频率的弱监督学习方法,标签缺失都是一个巨大的挑战。
“实体歧义:算法名词本身可能有多种形态,使用缩写形态可以大大减轻困难,但同时会带来歧义。在缺少标注数据的前提下,传统的去歧算法很难发挥作用。
“算法关系:算法之间比较性质的描述,出现在论文的一条或多条语句中。传统无监督学习方法更多地关注在”A是B“关系的挖掘上,监督学习方法一部分聚焦于单条句子、另一部分则关注段落级别的通用关系,而非算法缩写之间的比较关系,这一方面又缺乏标注数据进行训练。
为了解决这些问题,本文的算法首先抽取缩写作为算法候选。然后从文本及表格中抽取比较关系及实体作为弱监督学习的训练数据。进而使用本文提出的Cross-sentence Attention NeTwork for cOmparative Relation(CANTOR)进行算法抽取,在构建演进图的过程中预测算法类型从而进行去歧处理。最后利用时间及频率信息连接演进图中的节点。
算法细节
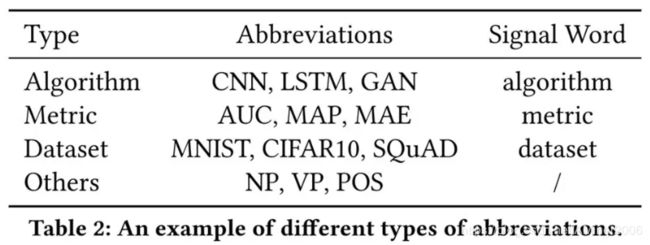
在算法候选的抽取方面,论文采用缩写作为候选,一是因为缺乏标注数据,短语的低频性导致短语名词抽取不可靠;二是因为缩写在论文中被普遍使用,而且形式简单,可以使用正则表达式进行精准匹配,后续比较关系抽取的表格中也主要使用缩写。对于缩写的类型,可以用其周围的标志性词语(Signal Word)来判断,如下图所示。
在跨语句关系抽取方面,本文分成了单语句和多语句两个不同模块进行处理。对于单语句,论文使用了Piecewise CNN (PCNN);对于多语句,论文使用两套注意力机制(自注意力及缩写注意力)。单语句和多语句模块得到的结果会通过加权的方式汇总在一起。
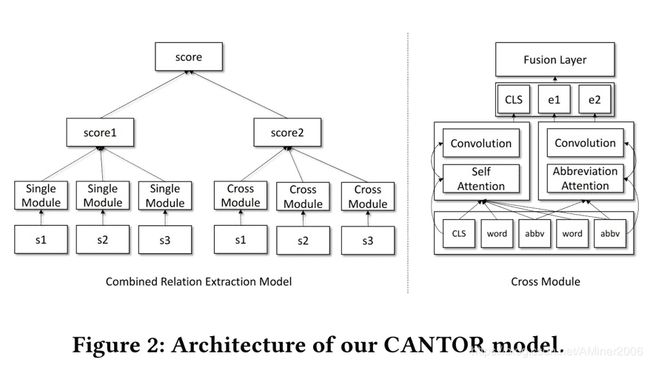
“语句每个词语的输入由词向量以及位置向量拼接而成。
“PCNN是一种CNN变形。对于输入的句子,将其分成三个片段,分别是第一个实体之前的片段、两个实体之间的片段和第二个实体之后的片段。三个片段用不同的Kernel分别做卷积以及Max-pooling,最后将三个分别处理过后的片段拼接起来,作为一个整体输入到最后的非线性层中。PCNN结构在短上下文关系抽取任务上有良好的表现效果。
“在注意力机制上,本文采用了Transformer的结构。类似BERT,论文引入了和两个token放在段落中作为结构标志。
“除此之外,本文还是用了字符级别的Character Embedding,为了应对有一些缩写在论文中出现频率过低的问题。
在实体类型的判别上,本文预设了一些类型,把它作为一个分类任务,放在上述的关系抽取过程中一起训练。具体来讲,是在注意力机制之后使用Softmax层进行预测。在损失函数上,由于一对实体,如算法之间的比较,应当具有同样的类型,因此额外加入KL散度。
关系抽取的数据采用了论文表格中的数据:同一列或同一行的实体为正例,同时再生成一系列负例。
在路线图的生成方面,由于先前生成的关系并无方向信息,在这里,作者使用算法出现的第一篇论文的时间作为算法的诞生时间,根据时间先后给定关系方向。如果年份相同,则按照出现频率大小给定方向。

实验
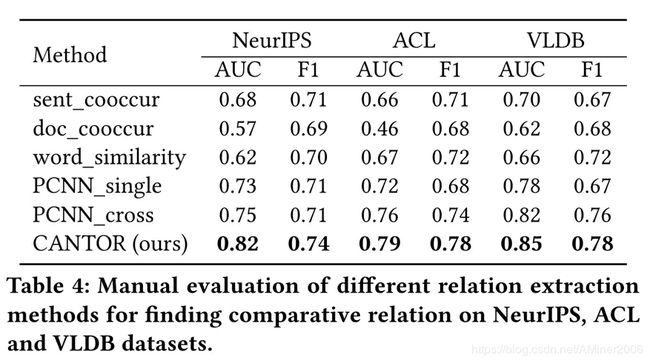
论文采用了NeurIPS/ACL/VLDB共12k篇论文。使用其中80%作为训练数据,20%作为测试数据。使用co-occurrence、词相似度等方法作为Baseline算法进行比较评估。由于生成的数据中,负例数量较多,所以无监督学习算法整体的准确率都较差。
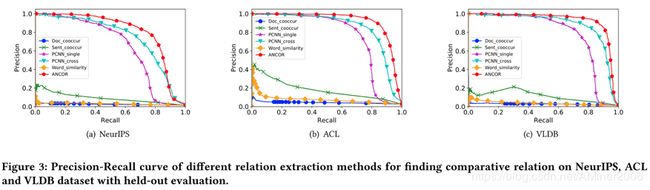
案例分析
论文对三个数据集中的GAN/Word2Vec/MonetDB三个不同的算法进行了分析,得到了以下路线图。由于在本文的做法中,并未区分缩写的不同形态,诸如SteinGAN和SteinGan这样的不同形态在当前的路线图中同时出现了。
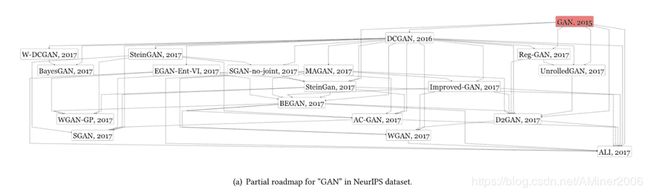
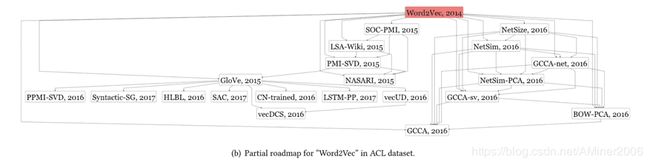
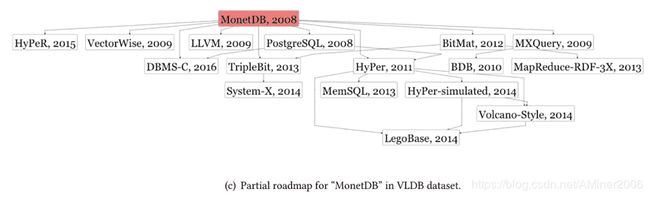
此外,在ACL的案例中,LSA-Wiki实际上是作为Word2vec的Baseline算法出现的,然而由于LSA-Wiki这个词在2015年才作为一个整体出现,因此被错分在了Word2vec之后。而且,一个名词的初次出现可能存在于当前数据集之外,意味着在当前数据集中的首次出现并不绝对代表这个名词的诞生。所幸公开的论文集,如Arxiv,的出现减轻了这个问题。