hadoop集群基础上安装ZooKeeper和HBase
之前的文章已经介绍了如何搭建hadoop集群,以及在hadoop集群之上搭建spark集群。可以点击如下链接查看:
一、centos7+hadoop2.8.0+VMware搭建完全分布式集群
二、hadoop完全分布式基础上搭建spark集群
本篇文章记录的是在上述hadoop集群上安装HBase和ZooKeeper的过程,以备后续参考!
软件版本和系统环境
①HBase,1.2.5,下载链接 http://archive.apache.org/dist/hbase/1.2.5/hbase-1.2.5-bin.tar.gz
②ZooKeeper,3.4.8,下载链接 http://archive.apache.org/dist/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz
安装配置ZooKeeper
①将下载的zookeeper压缩包上传到/opt/hadoop目录下并解压(这个目录是自己创建的用来存放相关软件安装包的)
在/opt/hadoop目录下执行解压命令:tar -zxf zookeeper-3.4.8.tar.gz

②进入zookeeper安装包的conf目录下,复制一份zoo_sample.cfg文件到zoo.cfg文件

③配置zoo.cfg

④创建dataDir对应的目录
因为上一步配置了dataDir的目录此时并不存在,因此需要创建。
进入/root/hadoop目录,执行命令:mkdir -p zookeeper/data
⑤进入data文件夹,新建myid文件并且写入“1”
命令:vi myid
⑥配置zookeeper安装目录下的conf文件夹中的日志文件log4j.properites,修改如下两处
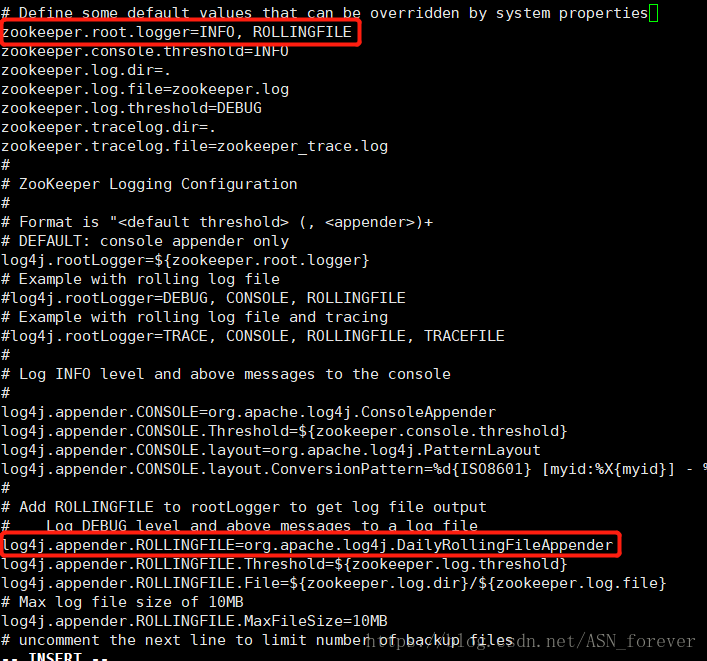
⑦bin目录下的zkEnv.sh文件,配置日志路径,修改如下两处

⑧将master节点上配置好的zookeeper文件传到slave1和slave2节点的/opt/hadoop目录下
命令:scp -r ....
![]()
![]()
⑧像步骤④一样,在slave1和slave2节点分别创建dataDir对应的目录,以及创建并编辑myid文件
区别是,myid文件的内容分别改为“2”和“3”,slave1对应2,slave2对应3
命令:mkdir -p zookeeper/data
⑨在所有机器上分别配置zookeeper环境变量
命令:vi /etc/profile,添加如下两行

⑩在每台机器上都运行zookeeper,并查看状态
下面三张图依次是我的启动顺序,status状态会根据集群启动情况动态选举leader和follower。

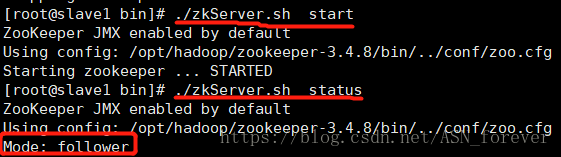
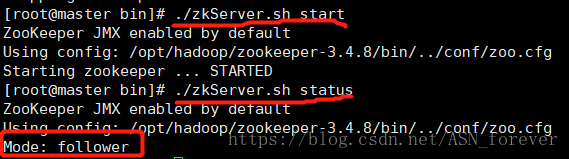
jps查看进程,看到所有节点都有QuorumPeerMain进程

注意:zookeeper的启动顺序不需要按照myid值的顺序依次启动。
如果觉得每次启动zookeeper集群都有在所有节点上执行start命令比较麻烦,可以参考下面链接进行设置,这样只需要在master节点的相关目录下执行startzk.sh即可启动集群。
https://blog.csdn.net/loopeng1/article/details/79012989
安装配置HBase
①将hbase压缩包上传到master节点的/opt/hadoop目录下并解压

②配置/opt/hadoop/hbase-1.2.5/conf目录下的一系列文件
主要是配置这三个文件hbase-env.sh、hbase-site.xml和 regionservers
hbase-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_181
export HBASE_CLASSPATH=/opt/hadoop/hbase-1.2.5
export HBASE_MANAGES_ZK=false(因为要使用自己安装的zookeeper,所以这里设置成false来禁止使用hbase自带的)
export HBASE_PID_DIR=/root/hadoop/pids(这是用来存放pid的目录,需要自己创建)hbase-site.xml
在
hbase.rootdir
hdfs://master:9000/hbase
hbase.master
hdfs://master:60000
hbase.cluster.distributed
true
hbase.zookeeper.property.dataDir
/opt/hadoop/zookeeper-3.4.8
hbase.zookeeper.property.clientPort
2181
hbase.zookeeper.quorum
master:2181,slave1:2181,slave2:2181
zookeeper.session.timeout
60000000
dfs.support.append
true
regionservers
添加节点主机名

③创建pid存放目录
在步骤②中,我们设置了HBASE_PID_DIR=/root/hadoop/pids,但当前并不存在此目录,因此需要手动创建此目录
命令:midir /root/hadoop/pids
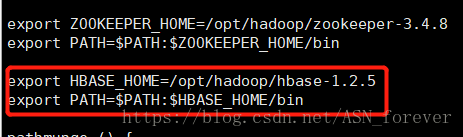
④在/etc/profile文件中配置hbase的环境变量
⑤将master节点上配置好的hbase-1.2.5安装包发送到slave1和slave2节点
在/opt/hadoop路径下依次执行下面两行命令
scp -r ./hbase-1.2.5 slave1:/opt/hadoop
scp -r ./hbase-1.2.5 slave2:/opt/hadoop⑥在master节点上启动hbase
在此之前,先启动hadoop和zookeeper。
在master节点上执行命令:start-hbase.sh来启动hbase,并用jps查看进程
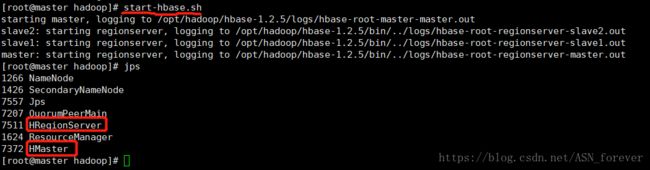
在slave节点查看进程

注意:此时Hadoop集群应处于启动状态,并且是在主节点执行start-hbase.sh启动HBase集群,否则HMaster进程将在启动几秒后消失,而备用的HMaster进程需要在备用主节点单独启动,命令是:./hbase-daemon.sh start master
⑦登录web页面查看
hbase1.0版本以后web默认的端口是16010,也可以自己在hbase.site.xml中设置
输入网址:masterip:16010 即可
