Large-Scale and Language-Oblivious Code Authorship Identification
摘要
Eicient extraction of code authorship attributes is key for suc- cessful identiication. However, the extraction of such attributes is very challenging, due to various programming language speciics, the limited number of available code samples per author, and the average code lines per ile, among others. To this end, this work proposes a Deep Learning-based Code Authorship Identiication System (DL-CAIS) for code authorship attribution that facilitates large-scale, language-oblivious, and obfuscation-resilient code au- thorship identiication. The deep learning architecture adopted in this work includes TF-IDF-based deep representation using multi- ple Recurrent Neural Network (RNN) layers and fully-connected layers dedicated to authorship attribution learning. The deep repre- sentation then feeds into a random forest classiier for scalability to de-anonymize the author. Comprehensive experiments are conducted to evaluate DL-CAIS over the entire Google Code Jam (GCJ) dataset across all years (from 2008 to 2016) and over real-world code samples from 1987 public repositories on GitHub. The results of our work show the high accuracy despite requiring a smaller number of iles per author. Namely, we achieve an accuracy of 96% when experimenting with 1,600 authors for GCJ, and 94.38% for the real-world dataset for 745 C programmers. Our system also allows us to identify 8,903 authors, the largest-scale dataset used by far, with an accuracy of 92.3%. Moreover, our technique is resilient to language-speciics, and thus it can identify authors of four pro- gramming languages (e.g., C, C++, Java, and Python), and authors writing in mixed languages (e.g., Java/C++, Python/C++). Finally, our system is resistant to sophisticated obfuscation (e.g., using C Tigress) with an accuracy of 93.42% for a set of 120 authors.
背景
- On the one hand, code authorship identiication poses a privacy risk for programmers who wish to remain anonymous, including contributors to open-source projects, activists, and programmers who conduct programming activities on the side. Thus, in turn, this makes code authors identiication a de-anonymization problem.
- On the other hand, code authorship identiication is useful for software forensics and security analysts, especially for identifying malicious code (such as malware) pro- grammers; e.g., where such programmers could leave source code in a compromised system for compilation, or where features of programmers could be extracted from decompiled binaries. More- over, authorship identiication of source code is helpful with plagia- rism detection [15], authorship disputes [49], copyright infringe- ment [26], and code integrity investigations [38].
- compare:
- [20] showed that a simple reverse engineering process of binary iles can generate a pseudo-code that can be treated as a source code for code authorship identiication.
limitations
- (i) most software features used in the literature for author identiication are not directly applicable to another language; features extracted in Java cannot be directly used as features in C or in Python for identifying the same author,
- (ii) techniques used for extracting code authorship features do not scale well for a large set of authors (see section 2).
- (iii) the extracted features are usually large and not all of them are relevant to the identiication task, necessitating an additional procedure for feature evaluation and selection [22].
- the deep learning architecture alone does not accurately identify programmers (86.2% accuracy for 1000 programmers).
- 多个程序员合作开发一个项目
- 作者身份混淆攻击
- 进行训练的样本不能过小
- 代码重用的影响,当大量代码中插入小量恶意代码时无法识别真正的恶意代码作者
目的
- 检测代码作者身份
方法
- ecurrent neural network (RNN)
- TF-IDF (Term Frequency-Inverse Doc- ument Frequency) that is already a well-known tool for textual data analysis
- The basic idea of TF-IDF is to evaluate the importance of terms in a document in a corpus, where the importance of a term is proportional to the frequency of the term in a document.
- Random Forest Classiier (RFC) is utilized as a classiier of a TF-IDF-based deep representation extracted by RNN. This approach allows us to utilize both deep learning’s good feature extraction capability and RFC’s large scale classiication capability.
- The quality of extracted au- thorship attributes signiicantly afects the identiication accuracy and the extent to which the proposed method can scale in terms of the number of authors.
- The techniques used in this paper are LSTM (Long Short-Term Memory) and Gated Recurrent Units (GRU) that are sorts of Recurrent Neural Network (RNN) among various Deep Neural Networks (DNN).
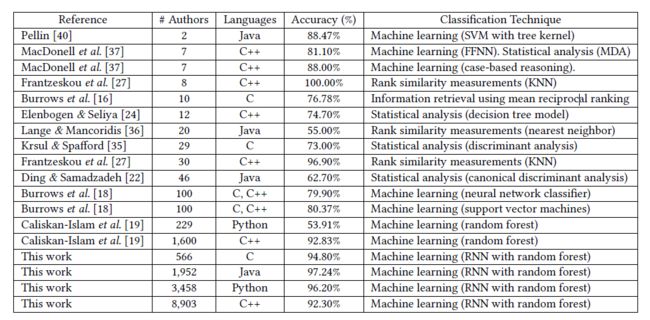
- we used the Principal Components Analysis (PCA). The PCA is a statistical tool that is widely used as a visualization technique that relects the diference in observations of multidimen- sional data for the purpose of simplifying further analysis
- In Figure 2(a), code iles are presented with the initial TF-IDF features, which are insuicient to draw a decision boundary for all programmers. In Figure 2(b), however, the deep representations have increased the margin for decision boundary so distinguishing programmers has become eas- ier. This visualization of the representations space (TF-IDF features and deep representations) illustrates the quality of representations obtained using the deep learning technique.
- Our authorship identiier is built by feeding a TF-IDF-based deep representation extracted by RNN and then classifying the representation by RFC. This hybrid approach allows us to take advantage of both deep representation’s distinguishing attribute extraction capability and RFC’s large scale classiication capability.
-
- preprocessing,
- representation through learning
- and classiication
- Preprocessing. The first phase starts with data preprocessing to handle code samples and generate initial representations. The initial representations of code samples are later fed into a deep learning architecture to learn more distinctive features. Finally, deep repre- sentations of code authorship attributions are used to construct a robust random forest model. Figure 3 illustrates the overall structure of our proposed system. In the irst phase, a straightforward mech- anism is used to represent source code iles based on a weighting scheme commonly used in information retrieval.
- Representation by Learning. This phase includes learning deep representations of authorship from less distinctive ones. Those representations are learned using an architecture with multiple RNN layers and fully-connected layers.
- Classiication. After training the deep architecture, the resulting representations are used to construct a random forest classiier with 300 trees grown to the maximum extent.

- The RNN layers in our deep learning architecture included a dropout regularization technique [44]. In essence, this technique randomly and temporally excludes a number of units on the forward pass and weight updates on the backward pass during the training process. The dropout regularization technique has been shown to enable the neural network to reach better generalization capabilities [44].
- RNN layers with dropout keep-rate of 0.6, followed by three fully-connected layers with ReLU activation. Each of the fully-connected layers has 1024 units except the last layer, which has 800 units representing the dimensional- ity of code authorship features for a given input file.
- supervised learning approach
- Thus, we use the output of layer Lk −1 (where the Lk is the softmax layer) to be the deep representations of code authorship features.
- TensorFlow’s Adaptive Moment estimation (Adam) [32] with a learning rate of 10−4, and without reducing the learning rate over time.
- 300 decision trees
特征
- Source code authorship identiication is the process of code writer identiication by associating a programmer to a given code based on the programmer’s distinctive stylometric features.
- Code authorship identiication relies on extracting features from source code that a programmer produces based on the program- mer’s preferences in structuring codes and naming variables.
- First, programming łstylež of program- mers continuously evolves as a result of their education, their ex- perience, their use of certain software engineering paradigms, and their work environment [17].
- Second, the programming style of programmers varies from language to another due to external con- straints placed by managers, tools, or even languages. Third, while it is sometimes possible to obtain the source code of programs, sometimes it is not, and the source code is occasionally obfuscated by automatic tools, preventing their recognition.
- 8,903 programmers high accuracy (92.3%)
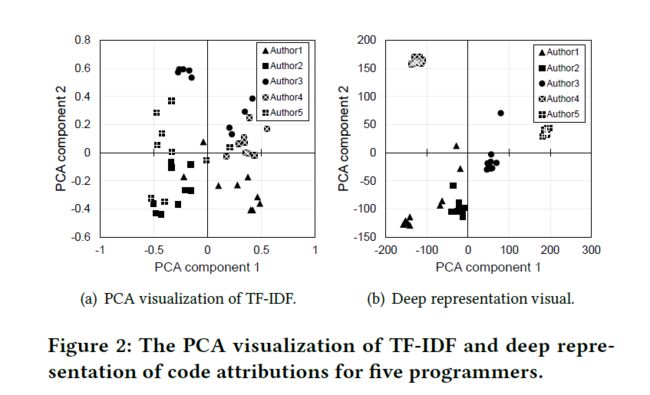
- Figure 4(a) shows the impact of feature selection, using four diferent approaches, on the accuracy of our approach using TF-IDF features in identifying code authors. In this experiment, we use 1,000 features to identify authors in a 250 C++ programmers experiment. The results demonstrate a substantial accuracy rate (of over 96%) for the given problem size. In Figure 4(b), we demonstrate the impact of the number of the selected TF-IDF features on the accuracy of the classiier. We note that the accuracy increases up to some value of the number of features after which it decays quickly. The accuracy, even with the smallest number of features, is relatively high.
训练服务器性能
24 cores, one GeForce GTX TITAN X GPU, and 256GB of memory
数据集
Our experiments cover the entire Google Code Jam dataset from 2008 to 2016
The Google Code Jam (GCJ) is an international programming com- petition run by Google since 2008 [1]. At GCJ, programmers from all over the world use several programming languages and develop- ment environments to solve programming problems over multiple rounds. Each round of the competition involves writing a program to solve a small number of problemsÐthree to six, within a ixed amount of time. We evaluate our approach on the source code of solutions to programming problems from GCJ. The most commonly used programming languages at GCJ are C++, Java, Python, and C, in order. Each of those languages has a suicient number of source code samples for each programmer, thus we use them for our evaluation. For a large-scale evaluation, we used the contest code from 2008 to 2016, with general statistics as shown in Table 2. The table shows the number of iles per author across years, with the total number of authors per programming language and the average ile size (lines of code, LoC). For evaluation, we create the following three dataset views (Tables 2ś4):
(1) Dataset 1: includes iles across all years from 2008 to 2016 in a łcross-yearsž view, as shown in Table 2.
(2) Dataset 2: consists of code iles for participants drawn from
2015 and 2016 competitions for four programming languages, as shown in Table 3.
(3) Dataset 3: consists of programmers who wrote in more than
one language (i.e., Java-C++, C-C++, and Python-C++) as shown in Table 4.
Number of Files. In [19], the use of nine files per programmer for
accuracy is recommended. Our approach provides as goodśor even betterśaccuracy with only seven files, as shown in ğ5.3.
效果
- language kinds
- coding time
- training file number
- training author number
- Obfuscated