centos6.5安装与使用elasticsearch-6.7.2
文章目录
- 1 安装
- 2 新建用户
- 3 配置
- 4 启动
- 5 查看
- 6 基本操作
- 6.1 查看基本信息
- 6.2 查看集群健康
- 6.3 查看集群的节点列表
- 6.4 索引操作
- 6.4.1 查看全部索引
- 6.4.2 创建索引
- 6.4.3 删除索引
- 6.5 文档操作
- 6.5.1 添加文档
- 6.5.2 查看文档
- 6.5.3 更新文档
- 6.5.4 删除文档
- 6.6 批处理
- 6.6.1 批量添加
- 6.6.2 批量更新删除
- 6.6.2 data.json文件批量添加
- 6.7 搜索
- 6.7.1 搜索全量文件
- 6.7.2 查询语言
- 6.7.2.1 配置分页
- 6.7.2.2 配置排序
- 6.7.2.3 配置分页+排序
- 6.7.3 搜索
- 6.7.3.1 展示部分字段
- 6.7.3.2 字段搜索查询(数字)
- 6.7.3.3 字段搜索查询(匹配单个关键字)
- 6.7.3.4 字段搜索查询(匹配多个关键字)
- 6.7.4 bool查询
- 6.7.5 过滤
- 6.7.6 聚集
- 7 参考文档
1 安装
# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.2.tar.gz
# tar -zxvf elasticsearch-6.7.2.tar.gz
# mkdir -p /Data/apps/elasticsearch
# mv elasticsearch-6.7.2/* /Data/apps/elasticsearch/
2 新建用户
ES启动的时候不能使用root用户,即普通用户启动,此时需要新创建一个用户,并为这个用户赋予访问ES目录的权限,在ES所在的目录下,为这个文件夹赋予权限
# useradd es
# passwd es
# chown es.es /Data/apps/elasticsearch -R
3 配置
1 /etc/sysctl.conf
elasticsearch用户拥有的内存权限太小,至少需要262144
vm.max_map_count=262144
执行命令,让配置生效
# sysctl -p
2 system_call_filter
因为Centos6不支持SecComp,而ES5.2.0默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。
vi /Data/apps/elasticsearch/config/elasticsearch.yml
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
#
2 修改Ip和端口
vi /Data/apps/elasticsearch/config/elasticsearch.yml
network.host: 10.1.20.101
http.port: 9200
4 启动
# su - es
# /Data/apps/elasticsearch
# -d后台启动
# ./bin/elasticsearch -d
5 查看
在浏览器中输入http://10.1.20.101:9200/
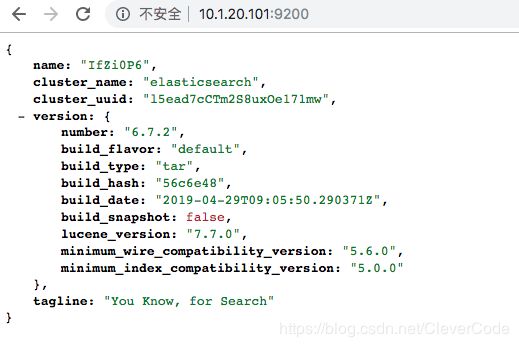
6 基本操作
6.1 查看基本信息
[[email protected] ~]$ curl -X GET "10.1.20.101:9200"
{
"name" : "IfZi0P6",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "l5ead7cCTm2S8uxOe171mw",
"version" : {
"number" : "6.7.2",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "56c6e48",
"build_date" : "2019-04-29T09:05:50.290371Z",
"build_snapshot" : false,
"lucene_version" : "7.7.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
[[email protected] ~]$
6.2 查看集群健康
[[email protected] ~]$ curl -X GET "10.1.20.101:9200/_cat/health?v"
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1570780907 08:01:47 elasticsearch green 1 1 0 0 0 0 0 0 - 100.0%
[[email protected] ~]$
我们可以看到,我们命名为“elasticsearch”的集群现在是green状态。
无论何时我们请求集群健康时,我们会得到green, yellow, 或者 red 这三种状态。
Green : everything is good(一切都很好)(所有功能正常)
Yellow : 所有数据都是可用的,但有些副本还没有分配(所有功能正常)
Red : 有些数据不可用(部分功能正常)
从上面的响应中我们可以看到,集群"elasticsearch"总共有1个节点,0个分片因为还没有数据。
6.3 查看集群的节点列表
可以看到集群中只有一个节点,它的名字是“IfZi0P6”
[[email protected] ~]$ curl -X GET "10.1.20.101:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.1.20.101 21 95 1 0.03 0.02 0.00 mdi * IfZi0P6
[[email protected] ~]$
6.4 索引操作
6.4.1 查看全部索引
[[email protected] ~]$
`
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
[[email protected] ~]$
上面的输出意味着:我们在集群中没有索引
6.4.2 创建索引
现在,我们创建一个名字叫“clevercode”的索引,然后查看索引。pretty的意思是响应(如果有的话)以JSON格式返回
[[email protected] ~]$ curl -X PUT "10.1.20.101:9200/clevercode?pretty"
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "clevercode"
}
[[email protected] ~]$
查看索引
[[email protected] ~]$ curl -X GET "10.1.20.101:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open clevercode nN4H3_YTQ3qnI9Td_LGQSQ 5 1 0 0 1.1kb 1.1kb
[[email protected] ~]$
结果的第二行告诉我们,我们现在有叫"clevercode"的索引,并且他有5个主分片和1个副本(默认是1个副本),有0个文档。
可能你已经注意到这个"clevercode"索引的健康状态是yellow。回想一下我们之前的讨论,yellow意味着一些副本(尚未)被分配。
之所以会出现这种情况,是因为Elasticsearch默认情况下为这个索引创建了一个副本。由于目前我们只有一个节点在运行,所以直到稍后另一个节点加入集群时,才会分配一个副本(对于高可用性)。一旦该副本分配到第二个节点上,该索引的健康状态将变为green。
6.4.3 删除索引
删除clevercode索引
[[email protected] ~]$ curl -X DELETE "10.1.20.101:9200/clevercode?pretty"
{
"acknowledged" : true
}
[[email protected] ~]$
6.5 文档操作
6.5.1 添加文档
1 让我们put一些数据到我们的"clevercode"索引。put方式需要指定id。这里id=1。id为整型。“result” : "created"表示新创建文档。
[[email protected] ~]$ curl -X PUT "10.1.20.101:9200/clevercode/_doc/1?pretty" -H 'Content-Type: application/json' -d'{"name": "CleverCode","address":"beijing"}'
{
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
[[email protected] ~]$
2 让我们put一些数据到我们的"clevercode"索引。put方式需要指定id。这里id=abcd,这里指定为字符串。
[[email protected] ~]$ curl -X PUT "10.1.20.101:9200/clevercode/_doc/abcd?pretty" -H 'Content-Type: application/json' -d'{"name": "CleverCode2","address":"beijing"}'
{
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "abcd",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
[[email protected] ~]$
3 让我们post一些数据到我们的"clevercode"索引。post方式不需要指定id。
[[email protected] ~]$ curl -X POST "10.1.20.101:9200/clevercode/_doc?pretty" -H 'Content-Type: application/json' -d'{"name": "CleverCode3","address":"beijing"}'
{
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "C-zXvW0Bsm6kRVId5yjQ",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
[[email protected] ~]$
4 查看索引信息,发现已经有4篇文档了。
[[email protected] ~]$ curl -X GET "10.1.20.101:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open clevercode Z17FxUrcSU2u9OzSkBZi3Q 5 1 4 0 16.7kb 16.7kb
[[email protected] ~]$
5 php版本curl直接上传一个文件
function posturl($url,$data){
$data = json_encode($data);
$headerArray =array("Content-Type: application/json");
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST,FALSE);
curl_setopt($curl, CURLOPT_POST, 1);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
curl_setopt($curl,CURLOPT_HTTPHEADER,$headerArray);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($curl);
curl_close($curl);
return $output;
}
$url = "10.1.20.101:9200/clevercode/_doc?pretty";
$data = array();
$data["fileName"] = "quckSort.php";
$data["filePath"] = "/home/dev/quckSort.php";
$data["fileContent"] = iconv('gbk','utf-8',file_get_contents("/home/dev/quckSort.php"));
$ret = posturl($url,$data);
print_r($ret);
执行后打印出的结果
{
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "E-wAvm0Bsm6kRVIdWiih",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
6.5.2 查看文档
1 curl 直接查看。"_source"字段返回了一个完整的JSON文档。
[[email protected] service]$ curl -X GET "10.1.20.101:9200/clevercode/_doc/E-wAvm0Bsm6kRVIdWiih?pretty"
{
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "E-wAvm0Bsm6kRVIdWiih",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fileName" : "quckSort.php",
"filePath" : "/home/dev/quckSort.php",
"fileContent" : "= $right) \n {\n return; \n }\n $tmp = $data[$right];\n $data[$right] = $data[$left];\n $data[$left] = $tmp;\n}/*}}}*/\n\nfunction huaFen(&$data,$left,$right)\n{/*{{{*/\n $pointIdx = $left;\n $pointValue = $data[$left];\n \n while($left < $right)\n {\n //浠??????宸??????????????????涓????pointValue灏????????n while($left < $right && $data[$right] >= $pointValue)\n {\n $right--; \n }\n\n //浠??????婵????????????涓????pointValue澶х??????n while($left < $right && $data[$left] <= $pointValue)\n {\n $left++; \n }\n\n //浜ゆ????????\n mySwap($data,$left,$right);\n }\n\n //浜ゆ??????????????left缈??硷伎????????????????????????????架n mySwap($data,$pointIdx,$left);\n \n return $left;\n}/*}}}*/\n\nfunction quickSort(&$data,$left,$right)\n{/*{{{*/\n if($left >= $right) \n {\n return; \n }\n\n //蹇????\n $pos = huaFen($data,$left,$right);\n\n //姹??????????\n quickSort($data,$left,$pos-1);\n\n //姹??????????\n\n quickSort($data,$pos + 1,$right);\n}/*}}}*/\n\nfunction mySort(&$data)\n{/*{{{*/\n if(false == is_array($data) || empty($data))\n {\n return; \n }\n quickSort($data,0,count($data)-1); \n}/*}}}*/\n\n\n$data = array(3,7,8,2,1,6,3,6,8,9,21,88,3);\nmySort($data);\nprint_r($data);\n\n"
}
}
[[email protected] service]$
2 php版本的curl查看
function geturl($url){
$headerArray =array("Content-Type: application/json");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch,CURLOPT_HTTPHEADER,$headerArray);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
return $output;
}
$url = "10.1.20.101:9200/clevercode/_doc/E-wAvm0Bsm6kRVIdWiih?pretty";
$ret = geturl($url);
print_r($ret);
打印结果
{
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "E-wAvm0Bsm6kRVIdWiih",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fileName" : "quckSort.php",
"filePath" : "/home/dev/quckSort.php",
"fileContent" : "= $right) \n {\n return; \n }\n $tmp = $data[$right];\n $data[$right] = $data[$left];\n $data[$left] = $tmp;\n}/*}}}*/\n\nfunction huaFen(&$data,$left,$right)\n{/*{{{*/\n $pointIdx = $left;\n $pointValue = $data[$left];\n \n while($left < $right)\n {\n //浠??????宸??????????????????涓????pointValue灏????????n while($left < $right && $data[$right] >= $pointValue)\n {\n $right--; \n }\n\n //浠??????婵????????????涓????pointValue澶х??????n while($left < $right && $data[$left] <= $pointValue)\n {\n $left++; \n }\n\n //浜ゆ????????\n mySwap($data,$left,$right);\n }\n\n //浜ゆ??????????????left缈??硷伎????????????????????????????架n mySwap($data,$pointIdx,$left);\n \n return $left;\n}/*}}}*/\n\nfunction quickSort(&$data,$left,$right)\n{/*{{{*/\n if($left >= $right) \n {\n return; \n }\n\n //蹇????\n $pos = huaFen($data,$left,$right);\n\n //姹??????????\n quickSort($data,$left,$pos-1);\n\n //姹??????????\n\n quickSort($data,$pos + 1,$right);\n}/*}}}*/\n\nfunction mySort(&$data)\n{/*{{{*/\n if(false == is_array($data) || empty($data))\n {\n return; \n }\n quickSort($data,0,count($data)-1); \n}/*}}}*/\n\n\n$data = array(3,7,8,2,1,6,3,6,8,9,21,88,3);\nmySort($data);\nprint_r($data);\n\n"
}
}
6.5.3 更新文档
事实上,每当我们执行更新时,Elasticsearch就会删除旧文档,然后索引一个新的文档。
下面这个例子展示了如何更新一个文档(ID为abcd),改变name字段为"mic"。 “result” : "updated"表示更新文档。
[[email protected] service]$ curl -X PUT "10.1.20.101:9200/clevercode/_doc/abcd?pretty" -H 'Content-Type: application/json' -d'{"name": "mic","address":"beijing"}'
{
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "abcd",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}
6.5.4 删除文档
删除clevercode索引中,id=abcd。 “result” : “deleted”,可以看到结果删除。
[[email protected] service]$ curl -X DELETE "10.1.20.101:9200/clevercode/_doc/abcd?pretty"
{
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "abcd",
"_version" : 6,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 1
}
[[email protected] service]$
6.6 批处理
除了能够索引、更新和删除单个文档之外,Elasticsearch还可以使用_bulk API批量执行上述任何操作。
这个功能非常重要,因为它提供了一种非常有效的机制,可以在尽可能少的网络往返的情况下尽可能快地执行多个操作。
6.6.1 批量添加
批量添加3个文档。
curl -X POST "10.1.20.101:9200/clevercode/_doc/_bulk?pretty" -H 'Content-Type: application/json' -d'
{"index":{"_id":"a"}}
{"name": "mic","address":"beijing"}
{"index":{"_id":"b"}}
{"name": "hans","address":"shanghai"}
{"index":{"_id":"c"}}
{"name": "jack","address":"guangzhou"}
'
响应结果
{
"took" : 9,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "a",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "b",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 7,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "c",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}
6.6.2 批量更新删除
更新a,删除b
curl -X POST "10.1.20.101:9200/clevercode/_doc/_bulk?pretty" -H 'Content-Type: application/json' -d'
{"update":{"_id":"a"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"delete":{"_id":"b"}}
'
响应结果
{
"took" : 10,
"errors" : false,
"items" : [
{
"update" : {
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "a",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 200
}
},
{
"delete" : {
"_index" : "clevercode",
"_type" : "_doc",
"_id" : "b",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 8,
"_primary_term" : 1,
"status" : 200
}
}
]
}
6.6.2 data.json文件批量添加
1 新建data.json文件
vi /home/dev/data.json
{"index":{"_id":"e"}}
{"name": "zhang shan","address":"beijing"}
{"index":{"_id":"f"}}
{"name": "li si","address":"shanghai"}
{"index":{"_id":"g"}}
{"name": "wang wu","address":"guangzhou"}
2 导入data.json数据到user索引
[[email protected] ~]$ curl -X POST "10.1.20.101:9200/user/_doc/_bulk?pretty&refresh" -H "Content-Type: application/json" --data-binary "@/home/dev/data.json"
3 查看索引信息,发现user下面有3个文档
[[email protected] ~]$ curl "10.1.20.101:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open user L2CHRHRNTqq-Slhkw5yH2A 5 1 3 0 8.7kb 8.7kb
yellow open clevercode Z17FxUrcSU2u9OzSkBZi3Q 5 1 10 0 42.7kb 42.7kb
[[email protected] ~]$
6.7 搜索
6.7.1 搜索全量文件
1 我们在"user"索引中检索,q=*参数表示匹配所有文档;sort=name:asc表示每个文档的name字段升序排序;pretty参数表示返回漂亮打印的JSON结果。
# curl -X GET "10.1.20.101:9200/user/_search?q=*&sort=name:asc&pretty"
响应结果
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "user",
"node" : "IfZi0P6oTH-4djuXxkJCVA",
"reason" : {
"type" : "illegal_argument_exception",
"reason" : "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
],
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
},
"status" : 400
}
根据官方文档显示,出现该错误是因为5.x之后,Elasticsearch对排序、聚合所依据的字段用单独的数据结构(fielddata)缓存到内存里了,但是在text字段上默认是禁用的,如果有需要单独开启,这样做的目的是为了节省内存空间。——官方文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/fielddata.html
2 开启user索引,name字段可以排序聚合索引。(方式一:通过REST请求URI发送检索参数)
# curl -X PUT "10.1.20.101:9200/user/_mapping/_doc" -H "Content-Type: application/json" -d'
{
"properties": {
"name": {
"type": "text",
"fielddata": true
}
}
}
'
"acknowledged":true}
再次搜索,发现有了sort字段。
[[email protected] ~]$ curl -X GET "10.1.20.101:9200/user/_search?q=*&sort=name:asc&pretty"
{
"took" : 25,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : null,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "f",
"_score" : null,
"_source" : {
"name" : "li si",
"address" : "shanghai"
},
"sort" : [
"li"
]
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "e",
"_score" : null,
"_source" : {
"name" : "zhang shan",
"address" : "beijing"
},
"sort" : [
"shan"
]
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "g",
"_score" : null,
"_source" : {
"name" : "wang wu",
"address" : "guangzhou"
},
"sort" : [
"wang"
]
}
]
}
}
[[email protected] ~]$
3 另外一种查询方式(方式二:通过REST请求体发送检索参数)。如果不带pretty,将会直接返回json,不美观。
curl -X GET "10.1.20.101:9200/user/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"sort": [
{ "name": "asc" }
]
}
'
可以看到,响应由下列几部分组成:
took : Elasticsearch执行搜索的时间(以毫秒为单位)
timed_out : 告诉我们检索是否超时
_shards : 告诉我们检索了多少分片,以及成功/失败的分片数各是多少
hits : 检索的结果
hits.total : 符合检索条件的文档总数
hits.hits : 实际的检索结果数组(默认为前10个文档)
hits.sort : 排序的key(如果按分值排序的话则不显示)
hits._score 和 max_score 现在我们先忽略这些字段
6.7.2 查询语言
6.7.2.1 配置分页
1 配置size=1,如果size没有指定,则默认是10
curl -X GET "10.1.20.101:9200/user/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"size": 1
}'
2 下面的例子执行match_all,并返回第10到19条文档。(from参数(从0开始)指定从哪个文档索引开始,并且size参数指定从from开始返回多少条。这个特性在分页查询时非常有用)。注意:如果没有指定from,则默认从0开始
curl -X GET "10.1.20.101:9200/user/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"from": 10,
"size": 10
}'
6.7.2.2 配置排序
配置查询全部,安装name降序排序
curl -X GET "10.1.20.101:9200/user/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"sort": { "name": { "order": "desc" } }
}'
6.7.2.3 配置分页+排序
配置查询全部,安装name降序排序,从0开始取2个结果。
curl -X GET "10.1.20.101:9200/user/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"sort": { "name": { "order": "desc" } },
"from": 0,
"size": 2
}'
响应结果。可以看到hits.total=3。说明命中了3个结果。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : null,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "e",
"_score" : null,
"_source" : {
"name" : "zhang shan",
"address" : "beijing"
},
"sort" : [
"zhang"
]
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "g",
"_score" : null,
"_source" : {
"name" : "wang wu",
"address" : "guangzhou"
},
"sort" : [
"wu"
]
}
]
}
}
6.7.3 搜索
6.7.3.1 展示部分字段
继续学习查询DSL。首先,让我们看一下返回的文档字段。默认情况下,会返回完整的JSON文档(PS:也就是返回所有字段)。这被成为source(hits._source)
如果我们不希望返回整个源文档,我们可以从源文档中只请求几个字段来返回。
下面的例子展示了只返回文档中的两个字段:account_number 和 balance字段
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"_source": ["account_number", "balance"]
}
'
相当于SELECT account_number, balance FROM bank
6.7.3.2 字段搜索查询(数字)
下面的例子返回account_number为20的文档
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match": { "account_number": 20 } }
}
'
相当于SELECT * FROM bank WHERE account_number = 20
6.7.3.3 字段搜索查询(匹配单个关键字)
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match": { "address": "mill" } }
}
'
相当于SELECT * FROM bank WHERE address LIKE ‘%mill%’
6.7.3.4 字段搜索查询(匹配多个关键字)
下面的例子返回address中包含"mill"或者"lane"的账户:
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match": { "address": "mill lane" } }
}
'
相当于SELECT * FROM bank WHERE address LIKE ‘%mill’ OR address LIKE ‘%lane%’
6.7.4 bool查询
下面的例子将两个match查询组合在一起,返回address中包含"mill"和"lane"的账户:
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}
'
相当于SELECT * FROM bank WHERE address LIKE ‘%mill%lane%’
上面是bool must查询,下面这个是bool shoud查询
curl -X GET “10.1.20.101:9200/bank/_search” -H ‘Content-Type: application/json’ -d’
{
“query”: {
“bool”: {
“should”: [
{ “match”: { “address”: “mill” } },
{ “match”: { “address”: “lane” } }
]
}
}
}
’
画外音:must相当于and,shoud相当于or,must_not相当于!)
(画外音:逻辑运算符:与/或/非,and/or/not,在这里就是must/should/must_not)
我们可以在bool查询中同时组合must、should和must_not子句。此外,我们可以在任何bool子句中编写bool查询,以模拟任何复杂的多级布尔逻辑。
下面的例子是一个综合应用:
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}
'
相当于SELECT * FROM bank WHERE age LIKE ‘%40%’ AND state NOT LIKE ‘%ID%’
6.7.5 过滤
分数是一个数值,它是文档与我们指定的搜索查询匹配程度的相对度量(PS:相似度)。分数越高,文档越相关,分数越低,文档越不相关。
但是查询并不总是需要产生分数,特别是当它们仅用于“过滤”文档集时。Elasticsearch检测到这些情况并自动优化查询执行,以便不计算无用的分数。
我们在前一节中介绍的bool查询还支持filter子句,该子句允许使用查询来限制将由其他子句匹配的文档,而不改变计算分数的方式。
作为一个例子,让我们引入range查询,它允许我们通过一系列值筛选文档。这通常用于数字或日期过滤。
下面这个例子用一个布尔查询返回所有余额在20000到30000之间(包括30000,BETWEEN…AND…是一个闭区间)的账户。换句话说,我们想要找到余额大于等于20000并且小于等等30000的账户。
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
'
6.7.6 聚集
画外音:相当于SQL中的聚集函数,比如分组、求和、求平均数之类的)
1 首先,这个示例按state对所有帐户进行分组,然后按照count数降序(默认)返回前10条(默认):
(画外音:相当于按state分组,然后count(),每个组中按照COUNT()数取 top 10)
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}
'
在SQL中,上面的聚集操作类似于:SELECT state, COUNT() FROM bank GROUP BY state ORDER BY COUNT() DESC LIMIT 10;
注意,我们将size=0设置为不显示搜索结果,因为我们只想看到响应中的聚合结果。
2 接下来的例子跟上一个类似,按照state分组,然后取balance的平均值
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
'
在SQL中,相当于:SELECT state, COUNT(), AVG(balance) FROM bank GROUP BY state ORDER BY COUNT() DESC LIMIT 10;
3 下面这个例子展示了我们如何根据年龄段(20-29岁,30-39岁,40-49岁)来分组,然后根据性别分组,最后得到平均账户余额,每个年龄等级,每个性别:
curl -X GET "10.1.20.101:9200/bank/_search" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"group_by_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}
}
'
7 参考文档
《Elasticsearch 快速开始》:https://www.cnblogs.com/cjsblog/p/9439331.html