前言
EM算法,此博客介绍了 EM E M 算法相关理论知识,看本篇博客前先熟悉 EM E M 算法。
本篇博客打算先从单个高斯分布说起,然后推广到多个高斯混合起来,最后给出高斯混合模型参数求解过程。
单个高斯分布
假如我们有一些数据,这些数据来自同一个高斯分布(独立同分布),那个我们如何根据这些数据估计出这个高斯分布的参数呢?我们知道只要知道高斯分布的参数 θ={μ,σ2} θ = { μ , σ 2 } 就能确定此高斯分布。
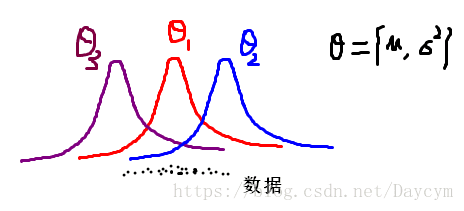
从上图中,我们要想知道数据是来自哪个高斯分布,我们就要知道高斯分布的参数,直观上可以认定数据来自参数为
θ1 θ 1 的高斯分布,然而这毕竟是我们直观上的,那么我们应该如何根据数据估计高斯分布的参数呢?
假设数据为 X={x1,x2,...,xN},xi X = { x 1 , x 2 , . . . , x N } , x i 独立同分布 p(X|θ) p ( X | θ ) ,其中 θ={μ,σ2} θ = { μ , σ 2 } ;
由贝叶斯公式知:
p(θ|X)∝p(X|θ)p(θ) p ( θ | X ) ∝ p ( X | θ ) p ( θ )
p(θ|X) p ( θ | X ) 为后验概率,
p(X|θ) p ( X | θ ) 为似然度,
p(θ) p ( θ ) 为先验概率。
关于贝叶斯公式的,可参考我之前的博客,里面有提到:链接
不加上先验概率,就是极大似然估计;
加上先验概率,就是极大后验概率估计
这里我们只介绍极大似然估计,极大后验概率估计类似
(1)写出对数似然函数
L(θ|X)=log [p(X|θ)]=∑i=1Nlog p(xi|θ)=∑i=1Nlog [12π−−√σexp(−(xi−μ)22σ2)] L ( θ | X ) = l o g [ p ( X | θ ) ] = ∑ i = 1 N l o g p ( x i | θ ) = ∑ i = 1 N l o g [ 1 2 π σ e x p ( − ( x i − μ ) 2 2 σ 2 ) ]
(2)求极大似然估计
分别对 μ,σ μ , σ 求偏导,并令为0:
∂L(θ|X)∂μ=∂(∑Ni=1log [12π√σexp(−(xi−μ)22σ2)])∂μ=∂(∑Ni=1log[exp(−(xi−μ)22σ2)])∂μ=∂(∑Ni=1−(xi−μ)22σ2)∂μ=−∑i=1N(xi−μ)σ2=0 ∂ L ( θ | X ) ∂ μ = ∂ ( ∑ i = 1 N l o g [ 1 2 π σ e x p ( − ( x i − μ ) 2 2 σ 2 ) ] ) ∂ μ = ∂ ( ∑ i = 1 N l o g [ e x p ( − ( x i − μ ) 2 2 σ 2 ) ] ) ∂ μ = ∂ ( ∑ i = 1 N − ( x i − μ ) 2 2 σ 2 ) ∂ μ = − ∑ i = 1 N ( x i − μ ) σ 2 = 0
由此得到
μ μ 的似然估计为:
μMLE=1N∑i=1Nxi μ M L E = 1 N ∑ i = 1 N x i
∂L(θ|X)∂σ=∂(∑Ni=1log [12π√σexp(−(xi−μMLE)22σ2)])∂σ=∂∑Ni=1log12π√σ∂σ+∂(∑Ni=1log[exp(−(xi−μMLE)22σ2)])∂σ=∑i=1N−(12π−−√σ)2π−−√+∂(∑Ni=1−(xi−μMLE)22σ2)∂σ=−N+∑Ni=1(xi−μMLE)2σ2=0 ∂ L ( θ | X ) ∂ σ = ∂ ( ∑ i = 1 N l o g [ 1 2 π σ e x p ( − ( x i − μ M L E ) 2 2 σ 2 ) ] ) ∂ σ = ∂ ∑ i = 1 N l o g 1 2 π σ ∂ σ + ∂ ( ∑ i = 1 N l o g [ e x p ( − ( x i − μ M L E ) 2 2 σ 2 ) ] ) ∂ σ = ∑ i = 1 N − ( 1 2 π σ ) 2 π + ∂ ( ∑ i = 1 N − ( x i − μ M L E ) 2 2 σ 2 ) ∂ σ = − N + ∑ i = 1 N ( x i − μ M L E ) 2 σ 2 = 0
其中用到
d log(1x)dx=−1x d l o g ( 1 x ) d x = − 1 x
得到
σ2 σ 2 的似然估计为:
σ2=∑Ni=1(xi−μMLE)2N σ 2 = ∑ i = 1 N ( x i − μ M L E ) 2 N
综上我们可以表述为:
θ=argmaxθ[∑i=1Nlog N(xi|μ,σ2)] θ = a r g max θ [ ∑ i = 1 N l o g N ( x i | μ , σ 2 ) ]
μ→∂L(μ,σ2|X)∂μσ2→∂L(μ,σ2|X)∂σ μ → ∂ L ( μ , σ 2 | X ) ∂ μ σ 2 → ∂ L ( μ , σ 2 | X ) ∂ σ
以上问题是只有一个高斯分布的,如果不止一个高斯分布呢?
高斯混合模型
同样,我们看下图:
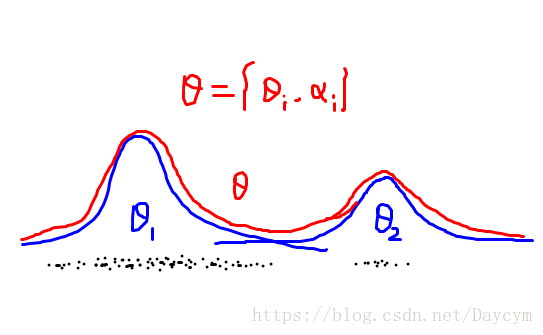
上图是一个高斯混合模型,此处只画了两个高斯分布,可以是多个高斯分布。
如果我们知道每一个数据属于哪一个高斯分布,就会很容易求解,但是我们不可能都知道的,这时随便一个数据点,我们应该如何判断它是哪个高斯分布产生的呢?
这里我们引入 αk α k 表示属于第 k k 个高斯分布的权重,并满足 ∑Kk=1αk=1 ∑ k = 1 K α k = 1
这样我们可以得到:
p(X|θ)=∑k=1KαkN(μk,σ2k)∑i=kKαk=1 p ( X | θ ) = ∑ k = 1 K α k N ( μ k , σ k 2 ) ∑ i = k K α k = 1
其中 N(μk,σ2k) N ( μ k , σ k 2 ) 是高斯分布, αk α k 是系数
给出定义:
高斯混合模型是指具有如下形式的概率分布模型:
p(x|θ)=∑k=1Kαkϕ(x|θk) p ( x | θ ) = ∑ k = 1 K α k ϕ ( x | θ k )
其中,
αk α k 是系数,
αk⩾0∑Kk=1αk=1 α k ⩾ 0 ∑ k = 1 K α k = 1 ;
ϕ(x|θk) ϕ ( x | θ k ) 是高斯分布密度,
θk=(μk,σ2k) θ k = ( μ k , σ k 2 ) ,
ϕ(x|θk)=12π−−√σkexp(−(x−μk)22σ2k) ϕ ( x | θ k ) = 1 2 π σ k e x p ( − ( x − μ k ) 2 2 σ k 2 )
称为第
k k 个分模型。
高斯混合模型参数估计的 EM E M 算法
假设观测数据 x1,x2,...,xN x 1 , x 2 , . . . , x N 由高斯混合模型生成,
p(x|θ)=∑k=1Kαkϕ(x|θk) p ( x | θ ) = ∑ k = 1 K α k ϕ ( x | θ k )
其中,
θ=(α1,α2,..,αk;θ1,θ2,..,θk) θ = ( α 1 , α 2 , . . , α k ; θ 1 , θ 2 , . . , θ k ) ,我们用
EM E M 算法估计高斯混合模型的参数
θ θ .
1. 明确隐变量,写出完全数据的对数似然函数
我们设想数据是这样产生的:
首先依概率 αk α k 选择第 k k 个高斯分布模型 ϕ(x|θk) ϕ ( x | θ k ) ;然后依第 k k 个分模型的概率分布 ϕ(x|θk) ϕ ( x | θ k ) 生成观测数据 xj x j 。这时观测数据 xj x j ,是已知的;反映观测数据 xj x j 来自第 k k 个分模型的数据是未知的, k=1,2,...,K k = 1 , 2 , . . . , K ,以隐变量 γjk γ j k 表示,其定义如下:
γjk={1,第j个观测来自第k个分模型0,否则j=1,2,...,N;k=1,2,...,K γ j k = { 1 , 第 j 个 观 测 来 自 第 k 个 分 模 型 0 , 否 则 j = 1 , 2 , . . . , N ; k = 1 , 2 , . . . , K
有了观测数据 xj x j 及未观测数据 γjk γ j k ,那么完全数据是: (xj,γj1,γj2,...,γjK),j=1,2,...,N ( x j , γ j 1 , γ j 2 , . . . , γ j K ) , j = 1 , 2 , . . . , N
于是,可以写出完全数据的似然函数:
p(x,γ|θ)=∏j=1Np(xj,γj1,γj2,...,γjK|θ)=∏k=1K∏j=1N[αkϕ(xj|θk)]γjk=∏k=1Kαnkk∏j=1N[ϕ(xj|θk)]γjk=∏k=1Kαnkk∏j=1N[12π−−√σkexp(−(xj−μk)22σ2k)]γjk p ( x , γ | θ ) = ∏ j = 1 N p ( x j , γ j 1 , γ j 2 , . . . , γ j K | θ ) = ∏ k = 1 K ∏ j = 1 N [ α k ϕ ( x j | θ k ) ] γ j k = ∏ k = 1 K α k n k ∏ j = 1 N [ ϕ ( x j | θ k ) ] γ j k = ∏ k = 1 K α k n k ∏ j = 1 N [ 1 2 π σ k e x p ( − ( x j − μ k ) 2 2 σ k 2 ) ] γ j k
式中:
nk=∑Nj=1γjk,∑Kk=1nk=N n k = ∑ j = 1 N γ j k , ∑ k = 1 K n k = N
那么,对数似然函数为:
log p(x,γ|θ)=∑k=1K{nklog αk+∑j=1Nγjk[log(12π−−√)−logσk−12σ2k(xj−μk)2]} l o g p ( x , γ | θ ) = ∑ k = 1 K { n k l o g α k + ∑ j = 1 N γ j k [ l o g ( 1 2 π ) − l o g σ k − 1 2 σ k 2 ( x j − μ k ) 2 ] }
2. EM E M 算法 E E 步:确定Q函数
Q(θ,θ(i))=E[log p(x,γ|θ)|x,θ(i)]=E{∑k=1K{nklog αk+∑j=1Nγjk[log(12π−−√)−logσk−12σ2k(xj−μk)2]}}=∑k=1K{∑j=1N(Eγjk)log αk+∑j=1N(Eγjk)[log(12π−−√)−logσk−12σ2k(xj−μk)2]} Q ( θ , θ ( i ) ) = E [ l o g p ( x , γ | θ ) | x , θ ( i ) ] = E { ∑ k = 1 K { n k l o g α k + ∑ j = 1 N γ j k [ l o g ( 1 2 π ) − l o g σ k − 1 2 σ k 2 ( x j − μ k ) 2 ] } } = ∑ k = 1 K { ∑ j = 1 N ( E γ j k ) l o g α k + ∑ j = 1 N ( E γ j k ) [ l o g ( 1 2 π ) − l o g σ k − 1 2 σ k 2 ( x j − μ k ) 2 ] }
这里需要计算
E(γjk|x,θ) E ( γ j k | x , θ ) ,记为
γjk^ γ j k ^
γjk^=E(γjk|x,θ)=p(γjk=1|x,θ)=p(γjk=1,xj|θ)∑Kk=1p(γjk=1,xj|θ)=p(xj|γjk=1,θ)p(γjk=1|θ)∑Kk=1p(xj|γjk=1,θ)p(γjk=1|θ)=αkϕ(xj|θk)∑Kk=1αkϕ(xj|θk),j=1,2,...,N;k=1,2,...,K γ j k ^ = E ( γ j k | x , θ ) = p ( γ j k = 1 | x , θ ) = p ( γ j k = 1 , x j | θ ) ∑ k = 1 K p ( γ j k = 1 , x j | θ ) = p ( x j | γ j k = 1 , θ ) p ( γ j k = 1 | θ ) ∑ k = 1 K p ( x j | γ j k = 1 , θ ) p ( γ j k = 1 | θ ) = α k ϕ ( x j | θ k ) ∑ k = 1 K α k ϕ ( x j | θ k ) , j = 1 , 2 , . . . , N ; k = 1 , 2 , . . . , K
γjk^ γ j k ^ 是在当前模型参数下第 j j 个观测数据来自第 k k 个分模型的概率,称为分模型 k k 对观测数据 xj x j 的响应度。
将 γjk^=Eγjk及nk=∑Nj=1Eγjk γ j k ^ = E γ j k 及 n k = ∑ j = 1 N E γ j k 代入之前式子即得:
Q(θ,θ(i))=∑k=1K{nklog αk+∑k=1Kγjk^[log(12π−−√)−logσk−12σ2k(xj−μk)2]} Q ( θ , θ ( i ) ) = ∑ k = 1 K { n k l o g α k + ∑ k = 1 K γ j k ^ [ l o g ( 1 2 π ) − l o g σ k − 1 2 σ k 2 ( x j − μ k ) 2 ] }
3. EM E M 算法 M M 步:
迭代的 M M 步是求函数 Q(θ,θ(i)) Q ( θ , θ ( i ) ) 对 θ θ 的极大值,即求新一轮迭代的模型参数:
θ(i+1)=argmaxθQ(θ,θ(i)) θ ( i + 1 ) = a r g max θ Q ( θ , θ ( i ) )
求 μk^,σ2k^ μ k ^ , σ k 2 ^ 只需要将Q函数对 μk,σ2k μ k , σ k 2 求偏导并令为0,即可得到;求 αk^ α k ^ 是在 ∑Ki=kαk=1 ∑ i = k K α k = 1 条件下求偏导数并令为0得到的,用到拉格朗日乘子法。
结果如下:
μk^=∑Nj=1γjk^xj∑Nj=1γjk^,k=1,2,...,Kσ2k^=∑Nj=1γjk^(xj−μk)2∑Nj=1γjk^,k=1,2,...,Kαk^=nkN=∑Nj=1γjk^N,k=1,2,...,K μ k ^ = ∑ j = 1 N γ j k ^ x j ∑ j = 1 N γ j k ^ , k = 1 , 2 , . . . , K σ k 2 ^ = ∑ j = 1 N γ j k ^ ( x j − μ k ) 2 ∑ j = 1 N γ j k ^ , k = 1 , 2 , . . . , K α k ^ = n k N = ∑ j = 1 N γ j k ^ N , k = 1 , 2 , . . . , K
重复以上计算,直到对数似然函数值不再有明显变化为止。
高斯混合模型参数估计的 EM E M 算法
输入:观测数据 x1,x2,...,xN x 1 , x 2 , . . . , x N ,高斯混合模型
输出:高斯混合模型参数
(1)取参数的初始值开始迭代
(2)E步:依据当前模型参数,计算分模型 k k 对观测数据 xi x i 的响应度
γjk^=αkϕ(xj|θk)∑Kk=1αkϕ(xj|θk),j=1,2,...,N;k=1,2,...,K γ j k ^ = α k ϕ ( x j | θ k ) ∑ k = 1 K α k ϕ ( x j | θ k ) , j = 1 , 2 , . . . , N ; k = 1 , 2 , . . . , K
(3)M步:计算新一轮迭代的模型参数
μk^=∑Nj=1γjk^xj∑Nj=1γjk^,k=1,2,...,Kσ2k^=∑Nj=1γjk^(xj−μk)2∑Nj=1γjk^,k=1,2,...,Kαk^=nkN=∑Nj=1γjk^N,k=1,2,...,K μ k ^ = ∑ j = 1 N γ j k ^ x j ∑ j = 1 N γ j k ^ , k = 1 , 2 , . . . , K σ k 2 ^ = ∑ j = 1 N γ j k ^ ( x j − μ k ) 2 ∑ j = 1 N γ j k ^ , k = 1 , 2 , . . . , K α k ^ = n k N = ∑ j = 1 N γ j k ^ N , k = 1 , 2 , . . . , K
(4)重复第(2)步和第(3)步,直到收敛。
至此,高斯混合模型的 EM E M 算法我们就介绍完了,关于算法 M M 步中的计算,这里没有给出,求解方法会使用到带约束条件的拉格朗日乘子法
参考资料:
李航《统计学习方法》,徐亦达机器学习