基于TCP协议的Socket网络编程( )
TCP编程
Socket是网络编程的一个抽象概念。通常我们用一个Socket表示“打开了一个网络链接”,而打开一个Socket需要知道目标计算机的IP地址和端口号,再指定协议类型即可。
今天我们要在Python中,基于TCP协议进行Socket网络编程
客户端
大多数连接都是可靠的TCP连接。创建TCP连接时,主动发起连接的叫客户端,被动响应连接的叫服务器。
举个例子,当我们在浏览器中访问百度时,我们自己的计算机就是客户端,浏览器会主动向百度的服务器发起连接。如果一切顺利,百度的服务器接受了我们的连接,一个TCP连接就建立起来的,后面的通信就是发送网页内容了。
言归正传,如果我们需要进行网络通信,就必须要创建一个基于TCP连接的Socket:
#######################
#########客户端#########
#######################
import socket#导入socket库
import time, threading#导入threading模块
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #创建一个socket
s.connect(('www.baidu.com', 80))#建立连接创建Socket时,AF_INET指定使用IPv4协议,如果要用更先进的IPv6,就指定为AF_INET6。SOCK_STREAM指定使用面向流的TCP协议,这样,一个Socket对象就创建成功,但是还没有建立连接。
客户端要主动发起TCP连接,必须知道服务器的IP地址和端口号。百度网站的IP地址可以用域名www.baidu.com自动转换到IP地址,但是怎么知道百度服务器,它作为服务器,提供什么样的服务,端口号就必须固定下来。由于我们想要访问网页,因此百度提供网页服务的服务器必须把端口号固定在80端口,因为80端口是Web服务的标准端口。其他服务都有对应的标准端口号,例如SMTP服务是25端口,FTP服务是21端口,等等。端口号小于1024的是Internet标准服务的端口,端口号大于1024的,可以任意使用。
因此,我们连接百度服务器的代码如下
注意参数是一个tuple(元祖),包含地址和端口号。
建立TCP连接后,我们就可以向百度服务器发送请求,要求返回首页的内容:
s.send(b'GET / HTTP/1.1\r\nHost: www.baidu.com\r\nConnection: close\r\n\r\n')
#发送数据TCP连接创建的是双向通道,双方都可以同时给对方发数据。但是谁先发谁后发,怎么协调,要根据具体的协议来决定。例如,HTTP协议规定客户端必须先发请求给服务器,服务器收到后才发数据给客户端。
发送的文本格式必须符合HTTP标准,如果格式没问题,接下来就可以接收百度服务器返回的数据了:
#接收数据
buffer = []
while True:
#每次最多接受1kb
d = s.recv(1024)#一次最多接受指定的字节数
if d:
buffer.append(d)
else:
break
data = b''.join(buffer)接收数据时,调用recv(max)方法,一次最多接收指定的字节数,因此,在一个while循环中反复接收,直到recv()返回空数据,表示接收完毕,退出循环。
当我们接收完数据后,调用close()方法关闭Socket,
# 关闭连接:
s.close()这样,一次完整的网络通信就结束了;
接下来把接收到数据包括HTTP首部和网页本身,我们只需要把HTTP首部和网页分离一下,把HTTP首部内容打印出来,而接受到的网页内容保存到文件:
header,html = data.split(b'\r\n\r\n',1) #将HTTP首部和网页分离
print(header.decode('utf-8'))
#把接收的数据写入文件
with open('baidu.html','wb') as f:
f.write(html);
整体的客户端代码如下
#######################
#########客户端#########
#######################
import socket#导入socket库
import time, threading#导入threading模块
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #创建一个socket
s.connect(('www.baidu.com', 80))#建立连接
s.send(b'GET / HTTP/1.1\r\nHost: www.baidu.com\r\nConnection: close\r\n\r\n')#发送数据
#s.connect(('www.sina.com.cn', 80))#新浪
#s.send(b'GET / HTTP/1.1\r\nHost: www.sina.com.cn\r\nConnection: close\r\n\r\n')#发送数据
#接收数据
buffer = []
while True:
#每次最多接受指定的字节数,此处最多接受1kb
d = s.recv(1024)
if d:
buffer.append(d)
else:
break
data = b''.join(buffer)
#关闭连接
s.close()
header,html = data.split(b'\r\n\r\n',1) #将HTTP首部和网页分离
print(header.decode('utf-8'))
#把接收的数据写入文件
with open('baidu.html', 'wb') as f:
f.write(html);
#with open('sina.html','wb') as f:
#f.write(html)
正确运行结果如下:
接受的网页数据成功写入了一个html文件中
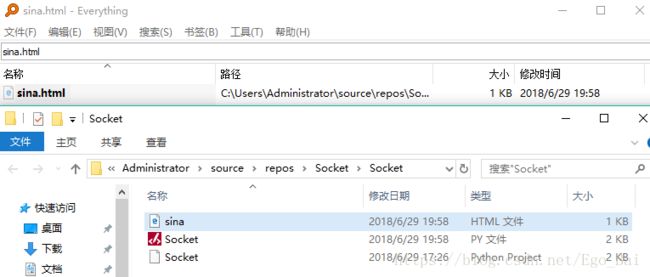
html文件内容

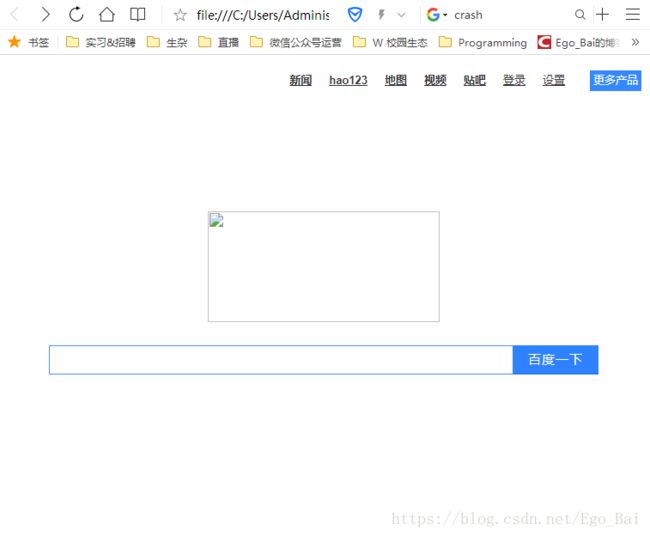
- 开始的时候因为代码缩进和传参字符串少个空格的问题,结果一直请求失败,无法接受正确的网页信息


其中with在文件操作上的用法非常巧妙,以前不太熟悉,看的时候很困惑,所以特别了解了一下
With语句是什么?
关于with我已经单独整理到这篇博客中:
Python中With的用法
有一些任务,可能事先需要设置,事后做清理工作。对于这种场景,Python的with语句提供了一种非常方便的处理方式。其中一个很好的例子是文件处理,你需要获取一个文件句柄,从文件中读取数据,然后关闭文件句柄。
如果不用with语句,代码如下:
file = open("/tmp/foo.txt")
data = file.read()
file.close()这里有两个问题。一是可能忘记关闭文件句柄;二是文件读取数据发生异常,没有进行任何处理。下面是处理异常的加强版本:
file = open("/tmp/foo.txt")
try:
data = file.read()
finally:
file.close()这段代码运行良好,但是太冗长。这时候with便体现出了优势。 除了有更优雅的语法,with还可以很好的处理上下文环境产生的异常。下面是with版本的代码:
with open("/tmp/foo.txt") as file:
data = file.read()是不是很简单?
但是如果对with工作原理不熟悉的通许可能会和刚才的我一样,不懂其中原理
那么下面我们简单看一下with的工作原理
with是如何工作的?
基本思想是:with所求值的对象必须有一个enter()方法,一个exit()方法。
紧跟with**后面的语句被求值后,返回对象的**__enter__()方法被调用,这个方法的返回值将被赋值给as后面的变量。当with后面的代码块全部被执行完之后,将调用前面返回对象的exit()方法。
下面是一个例子
######################
########with()##########
######################
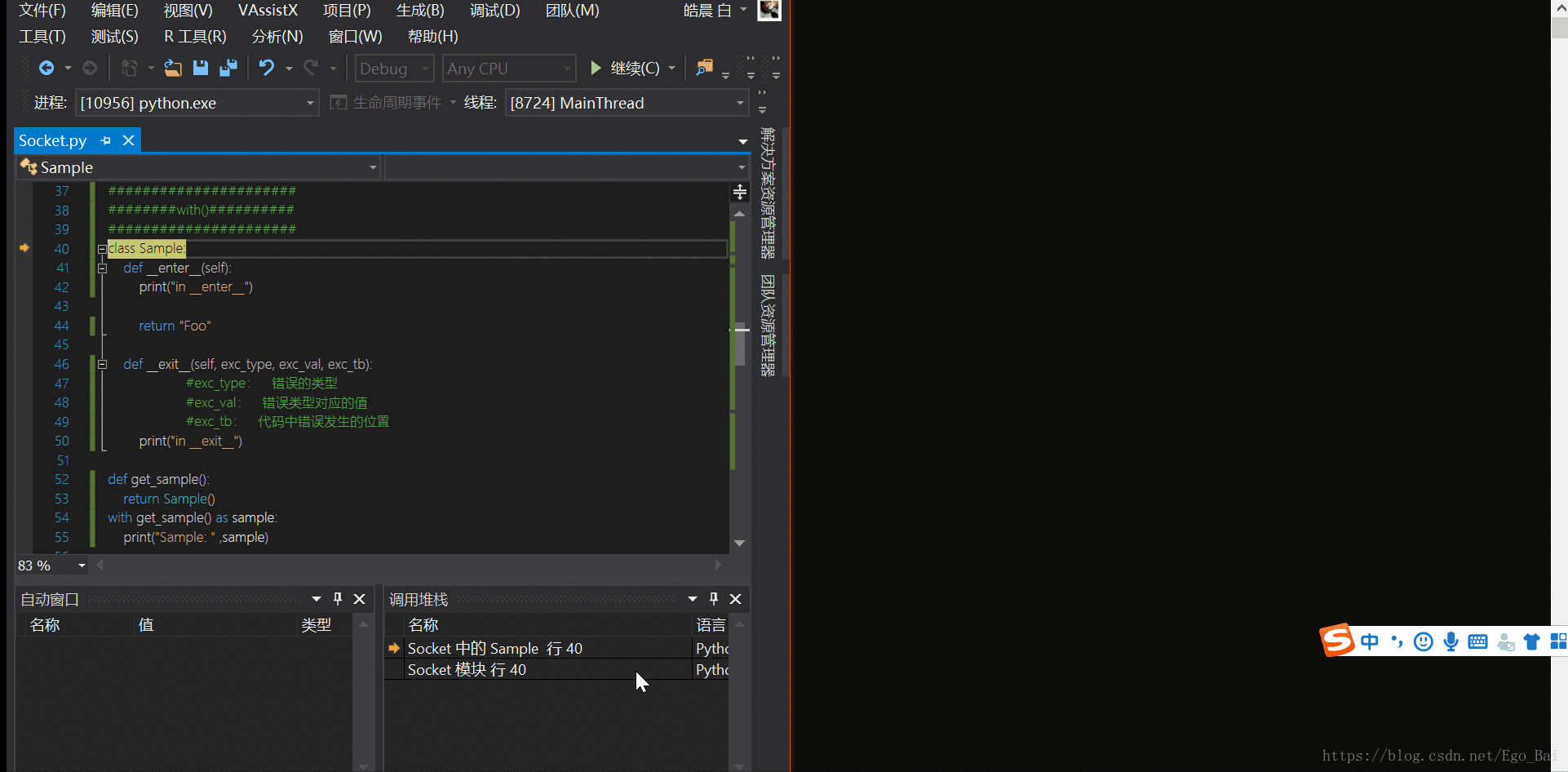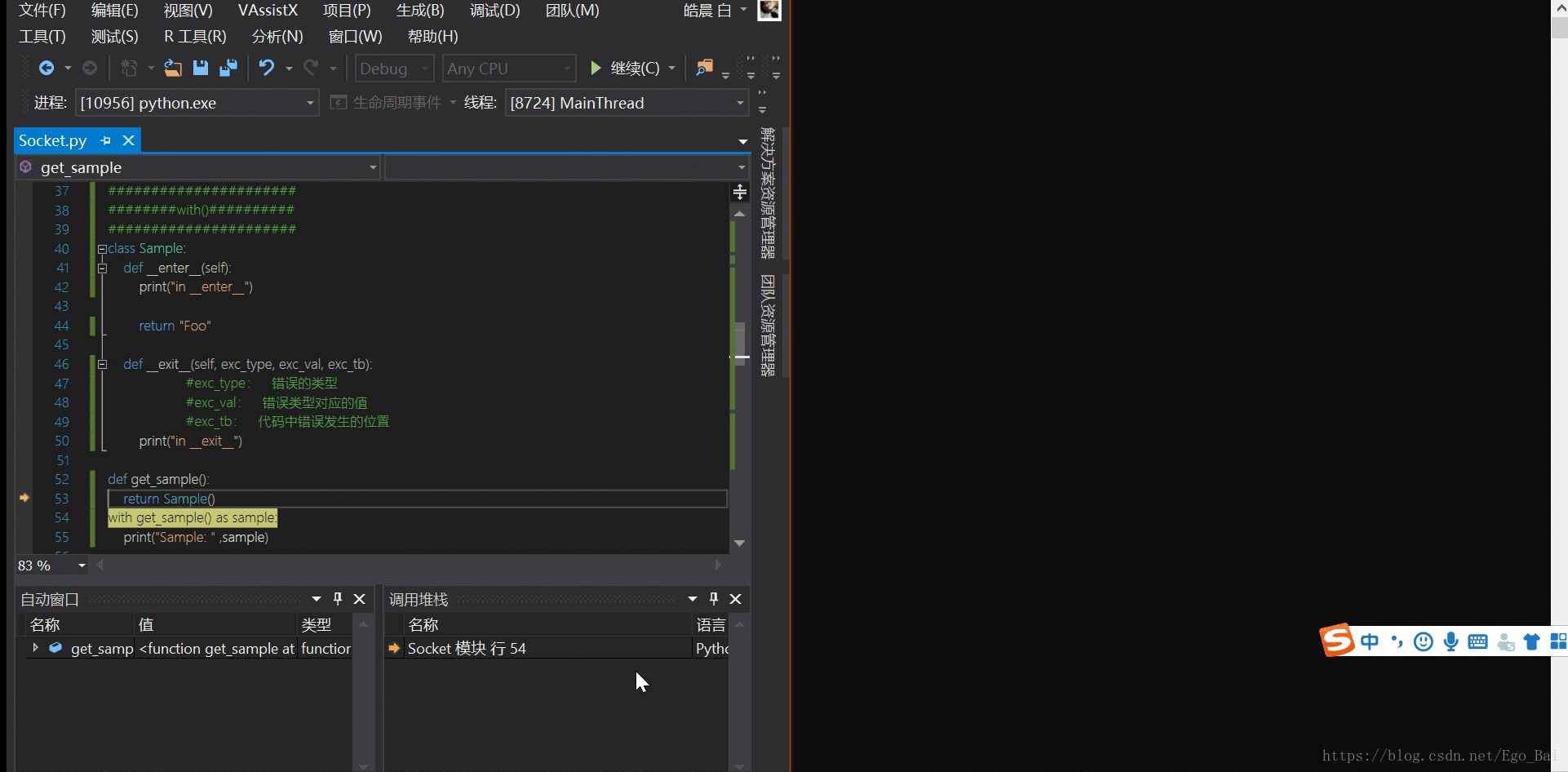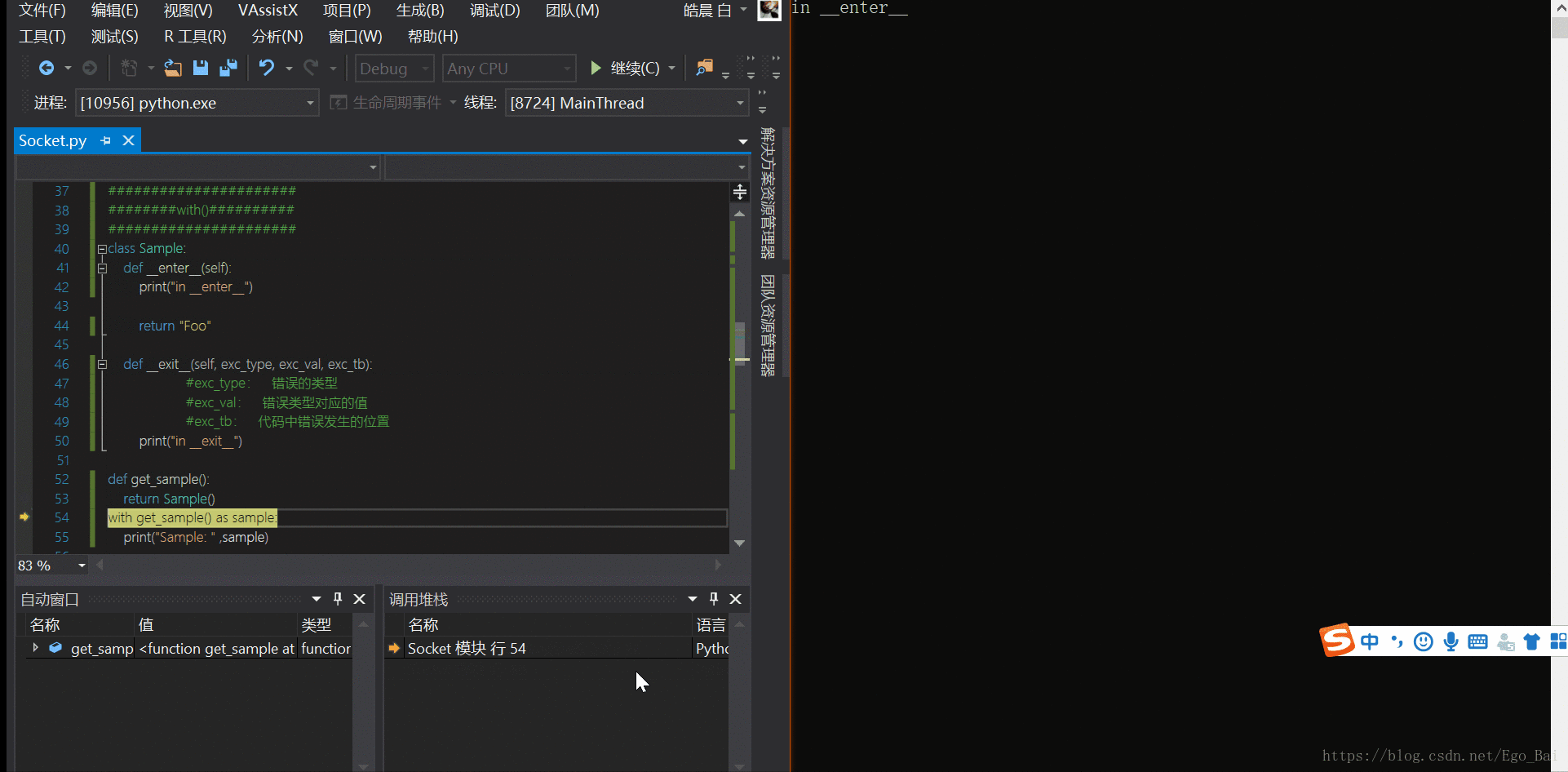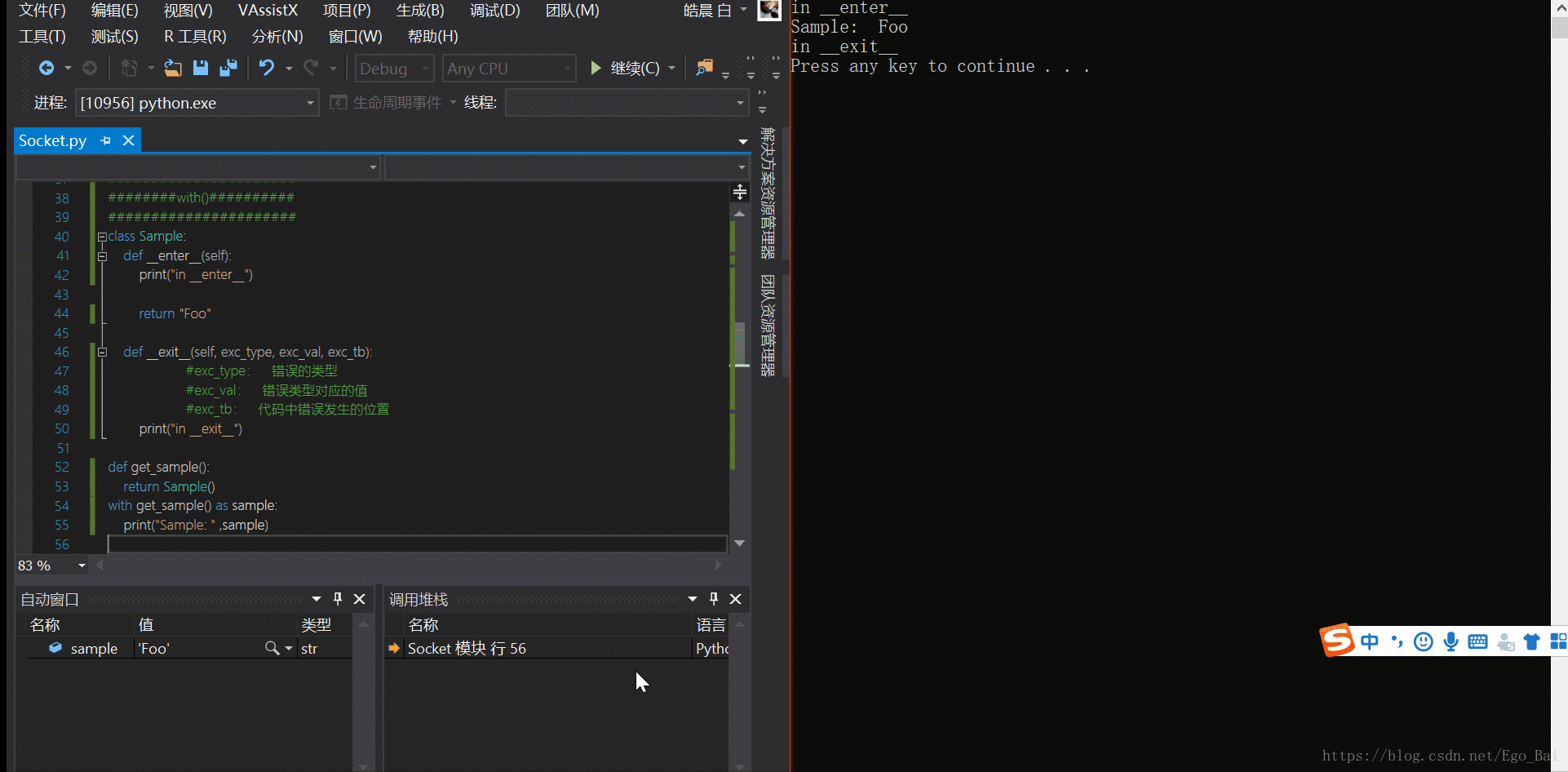
class Sample:
def __enter__(self):
print("in __enter__")
return "Foo"
def __exit__(self, exc_type, exc_val, exc_tb):
#exc_type: 错误的类型
#exc_val: 错误类型对应的值
#exc_tb: 代码中错误发生的位置
print("in __exit__")
def get_sample():
return Sample()
with get_sample() as sample:
print("Sample: " ,sample)
运行代码,输出如下
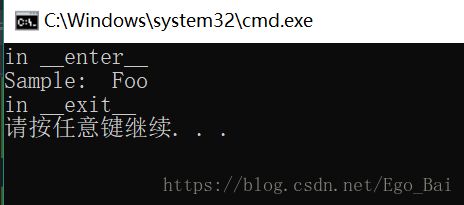
分析运行过程:
- 进入这段程序,首先创建Sample类,完成它的两个成员函数enter ()、exit()的定义,然后顺序向下定义get_sample()函数.
进入with语句,调用get_sample()函数,返回一个Sample()类的对象,此时就需要进入Sample()类中,可以看到
1. __enter__()方法先被执行 2. __enter__()方法返回的值 - 这个例子中是"Foo",赋值给变量'sample' 3. 执行with中的代码块,打印变量"sample",其值当前为 "Foo" 4. 最后__exit__()方法被调用
完整执行细节的调试过程请看gif:
这里只做了有限的简单说明,关于python中with用法详细参考:
浅谈 Python 的 with 语句
python的with用法
说完with我们继续回到,socket编程
服务器
接下来我们实现服务器端的过程
和客户端编程相比,服务器编程就要复杂一些。
服务器进程首先要绑定一个端口并监听来自其他客户端的连接。如果某个客户端连接过来了,服务器就与该客户端建立Socket连接,随后的通信就靠这个Socket连接了。
所以,服务器会打开固定端口(比如80)监听,每来一个客户端连接,就创建该Socket连接。由于服务器会有大量来自客户端的连接,所以,服务器要能够区分一个Socket连接是和哪个客户端绑定的。一个Socket依赖4项:服务器地址、服务器端口、客户端地址、客户端端口来唯一确定一个Socket。
但是服务器还需要同时响应多个客户端的请求,所以,每个连接都需要一个新的进程或者新的线程来处理,否则,服务器一次就只能服务一个客户端了。
我们来编写一个简单的服务器程序,它接收客户端连接,把客户端发过来的字符串加上Hello再发回去。
首先,创建一个基于IPv4和TCP协议的Socket:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)然后,我们要绑定监听的地址和端口。服务器可能有多块网卡,可以绑定到某一块网卡的IP地址上,也可以用0.0.0.0绑定到所有的网络地址,还可以用127.0.0.1绑定到本机地址。127.0.0.1是一个特殊的IP地址,表示本机地址,如果绑定到这个地址,客户端必须同时在本机运行才能连接,也就是说,外部的计算机无法连接进来。
端口号需要预先指定。因为我们写的这个服务不是标准服务,所以用9999这个端口号。请注意,小于1024的端口号必须要有管理员权限才能绑定:
# 绑定端口:
s.bind(('127.0.0.1', 9999))紧接着,调用listen()方法开始监听端口,传入的参数指定等待连接的最大数量:
s.listen(5)
print('Waiting for connection...')接下来,服务器程序通过一个死循环来接不断接收来自客户端的连接,accept()会等待并返回一个客户端的连接:
while True:
# 接受一个新连接:
sock, addr = s.accept()
# 创建新线程来处理TCP连接:
t = threading.Thread(target=tcplink, args=(sock, addr))
t.start()每个连接都必须创建新线程(或进程)来处理,否则,单线程在处理连接的过程中,无法接受其他客户端的连接:
def tcplink(sock, addr):
print('Accept new connection from %s:%s...' % addr)
sock.send(b'Welcome!')
while True:
data = sock.recv(1024)
time.sleep(1)
if not data or data.decode('utf-8') == 'exit':
break
sock.send(('Hello, %s!' % data.decode('utf-8')).encode('utf-8'))
sock.close()
print('Connection from %s:%s closed.' % addr)
连接建立后,服务器首先发一条欢迎消息,然后等待客户端数据,并加上Hello再发送给客户端。如果客户端发送了exit字符串,就直接关闭连接。
要测试这个服务器程序,我们还需要单独编写一个客户端程序:
##########
#测试 客户端
##########
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect(('127.0.0.1', 9999))
# 接收欢迎消息:
print(s.recv(1024).decode('utf-8'))
for data in [b'Michael', b'Tracy', b'Sarah']:
# 发送数据:
s.send(data)
print(s.recv(1024).decode('utf-8'))
s.send(b'exit')
s.close()
测试时,先启动服务器程序,再运行客户端程序,这样我们就能完整看到这次简要的建立连接-发送请求-接受响应报文-解析并输出的网络通信过程了
完整代码
- server.py
########################
##########服务器#########
########################
import socket#导入socket库
import time, threading#导入threading模块
#创建一个给予IPv4和TCP协议的Socket:
s = socket.socket(socket.AF_INET , socket.SOCK_STREAM)
#监听端口
#绑定
s.bind(('127.0.0.1',9999))
#调用listen()函数监听端口,传入的参数指定等待连接的最大数量
s.listen(5)
print('Waiting for connection...')
def tcplink(sock, addr):
print('Accept new connection from %s:%s...' % addr)
sock.send(b'Welcome!')
while True:
data = sock.recv(1024)
time.sleep(1)
if not data or data.decode('utf-8') == 'exit':
break
sock.send(('Hello, %s!' % data.decode('utf-8')).encode('utf-8'))
sock.close()
print('Connection from %s:%s closed.' % addr)
#建立连接后,服务器首先发一条欢迎消息,然后等待客户端数据,并加上Hello,xxx!再发送给客户端.入伙客户端发送了'exit'字符串,就直接关闭连接
#服务器通过一个死循环来接受来自客户端的链接,accept()会等待并返回一个客户端的链接:
while True:
# 接受一个新连接:
sock, addr = s.accept()
# 创建新线程来处理TCP连接:
t = threading.Thread(target=tcplink, args=(sock, addr))
t.start()
#每个链接都必须创建新线程(或进程)来单独处理,否则,单线程在处理连接的过程中,无法接受其他客户的链接:- client.py
##########
#测试 客户端
##########
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect(('127.0.0.1', 9999))
# 接收欢迎消息:
print(s.recv(1024).decode('utf-8'))
for data in [b'Michael', b'Tracy', b'Sarah']:
# 发送数据:
s.send(data)
print(s.recv(1024).decode('utf-8'))
s.send(b'exit')
s.close()
运行结果:

总结一下:
其实用TCP协议进行Socket编程在Python中十分简单:
对于客户端:
1.要主动连接服务器的IP和指定端口,
对于服务器
1.首先监听指定端口
2.对每一个新的连接,创建一个线程或进程来处理。
3.通常,服务器程序会无限运行下去。
注意:同一个端口,被一个Socket绑定了以后,就不能被别的Socket绑定了,即被占用了,此时就会发生冲突
参考源码
do_tcp.py