离线计算辅助系统--Flume详解
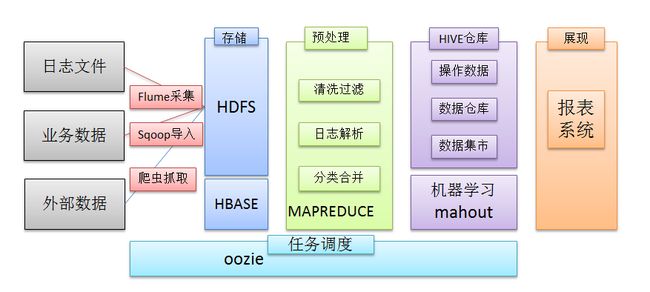
在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数据导出、任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中都有便捷的开源框架,如图所示:
(一)Flume介绍
• Apache软件基金顶级项目• Apache Flume是一个分布式、可信任的弹性系统,用于高效收集、汇聚和移动大规模日志信息从多种不同的数据源到一个集中的数据存储中心(HDFS、HBase)
• 功能:
– 支持在日志系统中定制各类数据发送方,用于收集数据
– Flume提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力
• 多种数据源:
– Console、RPC、Text、Tail、Syslog、Exec等

• 一般的采集需求,通过对flume的简单配置即可实现
• Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
特点:
• Flume可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中
• 使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中
• 支持各种接入资源数据的类型以及接出数据类型• 支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等
• 可以被水平扩展
(二)Flume Core
2.1、外部架构

• 数据发生器(如:facebook,twitter)产生的数据被被单个的运行在数据发生器所在服务器上的agent所收集,之后数据收容器从各个agent上汇集数据并将采集到的数据存入到HDFS或者HBase中
2.2 事件 ( Flume Event)
• 由两部分组成:转载数据的字节数组+可选头部

• Body是一个字节数组,包含了实际的内容
2.3、代理 ( Flume Agent)
• 每一个Agent是一个独立的守护进程(JVM)
• 从客户端哪儿接收收集,或者从其他的Agent哪儿接收,然后迅速的将获取的数据传给下一个目的节点Agent

2.4、 Agent Source
• 负责一个外部源(数据发生器),如一个web服务器传递给他的事件
• 该外部源将它的事件以Flume可以识别的格式发送到Flume中
• 当一个Flume源接收到一个事件时,其将通过一个或者多个通道存储该事件
2.5 Agent Channel—有时某一时间突然来的数据量比较大,就需要channel来缓存
• 通道:采用被动存储的形式,即通道会缓存该事件直到该事件被sink组件处理
• 所以Channel是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channel是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接
• 可以通过参数设置event的最大个数
• Flume通常选择FileChannel,而不使用Memory Channel(Kafka可以合并这两个的优点)
– Memory Channel:内存存储事务,吞吐率极高,但存在丢数据风险
– File Channel:本地磁盘的事务实现模式,保证数据不会丢失(WAL实现)
2.6 Agent Sink
– 例如:通过Flume HDFS Sink将数据放置到HDFS中,或者放置到下一个Flume的Source,等到下一个Flume处理。
– 对于缓存在通道中的事件,Source和Sink采用异步处理的方式
• Sink成功取出Event后,将Event从Channel中移除
• Sink必须作用于一个确切的Channel
• 不同类型的Sink:如果图中3个agent都往HDFS中下沉,可以先下沉到一个中转的agent4
– 存储Event到最终目的的终端:HDFS、Hbase
– 自动消耗:Null Sink
– 用于Agent之间通信:Avro

2.7、 Agent Interceptor
• 在app(应用程序日志)和 source 之间的,对app日志进行拦截处理的。也即在日志进入到source之前,对日志进行一些包装、清新过滤等等动作
• 官方上提供的已有的拦截器有:
– Timestamp Interceptor:在event的header中添加一个key叫:timestamp,value为当前的时间戳
– Host Interceptor:在event的header中添加一个key叫:host,value为当前机器的hostname或者ip
– Static Interceptor:可以在event的header中添加自定义的key和value
– Regex Filtering Interceptor:通过正则来清洗或包含匹配的events
– Regex Extractor Interceptor:通过正则表达式来在header中添加指定的key,value则为正则匹配的部分
• flume的拦截器也是chain形式的,可以对一个source指定多个拦截器,按先后顺序依次处理
2.8、 Agent Selector
– Replicating Channel Selector (default):将source过来的events发往所有channel
– Multiplexing Channel Selector:而Multiplexing 可以选择该发往哪些channel
• 对于有选择性选择数据源,明显需要使用Multiplexing 这种分发方式

– 通过设置上游不同的Source就可以解决
2.9、可靠性
• Flume保证单次跳转可靠性的方式:传送完成后,该事件才会从通道中移除• Flume使用事务性的方法来保证事件交互的可靠性。
• 整个处理过程中,如果因为网络中断或者其他原因,在某一步被迫结束了,这个数据会在下一次重新传输。
• Flume可靠性还体现在数据可暂存上面,当目标不可访问后,数据会暂存在Channel中,等目标可访问之后,再进行传输
• Source和Sink封装在一个事务的存储和检索中,即事件的放置或者提供由一个事务通过通道来分别提供。这保证了事件集在流中可靠地进行端到端的传递。
– Sink开启事务
– Sink从Channel中获取数据
– Sink把数据传给另一个Flume Agent的Source中
– Source开启事务
– Source把数据传给Channel
– Source关闭事务– Sink关闭事务
2.10 复杂的流动性
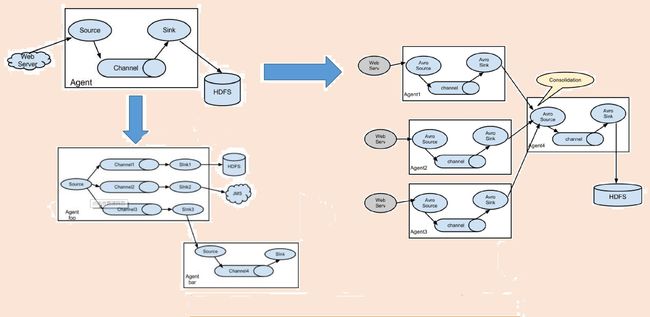

(三)Flume运行机制
1、 Flume分布式系统中最 核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成2、 每一个agent相当于一个数据传递员,内部有三个组件:
a) Source:采集源,用于跟数据源对接,以获取数据
b) Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
c) Channel:angent内部的数据传输通道,用于从source将数据传递到sink

数据传递元:Source 到 Channel 到 Sink之间传递数据的形式是Event事件;Event事件是一个数据流单元。
(四)Flume采集系统结构图
1. 简单结构
单个agent采集数据

2. 复杂结构
多级agent之间串联

(五)Flume集群环境搭建
参考链接
(六)采集案例
6.1 采集目录到HDFS
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去根据需求,首先定义以下3大要素
l 采集源,即source——监控文件目录 : spooldir
l 下沉目标,即sink——HDFS文件系统 : hdfs sink
l source和sink之间的传递通道——channel,可用filechannel 也可以用内存channel
配置文件编写:
#定义三大组件的名称
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 配置source组件
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/hadoop/logs/
agent1.sources.source1.fileHeader = false
#配置拦截器
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
# 配置sink组件
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path =hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1Channel参数解释:
capacity:默认该通道中最大的可以存储的event数量trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量
keep-alive:event添加到通道中或者移出的允许时间
6.2 采集文件到HDFS
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
根据需求,首先定义以下3大要素
l 采集源,即source——监控文件内容更新 : exec ‘tail -F file’
l 下沉目标,即sink——HDFS文件系统 : hdfs sink
l Source和sink之间的传递通道——channel,可用filechannel 也可以用内存channel
配置文件编写:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure tail -F source1
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /home/hadoop/logs/access_log
agent1.sources.source1.channels = channel1
#configure host for source
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
# Describe sink1
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
agent1.sinks.sink1.hdfs.path =hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 10
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel16.3 更多source和sink组件
Flume支持众多的source和sink类型,详细手册可参考官方文档http://flume.apache.org/FlumeUserGuide.html